1.摘要
该文提出一种基于双向注意力机制的图像描述生成方法,在单向注意力机制的基础上,加入图像特征到语义信息方向上的注意力计算,实现图像和语义信息两者在两个方向上的交互,并设计了 一种门控网络对上述两个方向上的信息进行融合。最终,提高解码器所蕴含的语义信息与图像内容的 一致性,使得所生成描述更加准确。此外,与前人研究不同的是,该文在注意力模块中利用了历史时刻的语义信息辅助当前时刻的单词生成,并对历史语义信息的作用进行了验证。
2.LSTM隐状态输出h存在的问题及解决方法
使用循环神经网络的隐状态输出h作为语义信息表达,将其映射到词表空间,生成当前时刻的单词,所以h的内容将直接影响最终的生成结果。然而,目前的注意力方法仅使用隐状态输出h选取合适的局部图像特征,对于h的内部信息并未进一步检验或约束。此外,从图像特征角度看,目前的图像特征始终处于被选择的被动状态,对生成过程中的语义信息表示未起到监督作用,存在语义信息与图像内容一致性较差的问题,导致最终生成描述的准确性不足。
为解决上述问题,本文提出了一种基于双向注意力机制的图像描述生成方法,旨在提升解码器中蕴含的语义信息与图像内容的一致性,使生成的描述更加准确。具体地,双向注意力机制包含以下两个方面的内容。其一,根据循环神经网络的隐状态输出(h)为所有的图像特征分量分配权重,经加权求和计算后,得到新的图像特征表示(cv)。其二,本文保留了历史的隐状态输出集合 {h0,h1,…,ht},并根据图像的全局特征表示(V)为隐状态集合中的每个元素(hi)计算注意力得分,同样经加权求和操作,得到新的语义信息表示(ch)。至此,本方法完成了图像特征和语义信息二者在两个方向上的信息交互,增强了两者的一致性。之后,本文设计了一种门控机制完成对上述两种信息表示(cv和ch)的融合。与前人方法不同,本文首次使用了解码器中历史时刻的语义信息,并对历史语义信息的有效性进行了验证。
3.方法
3.1图像特征提取
在编码阶段,本文使用了两种预训练模型进行图像特征的提取,分别是 Resnet101和 FasterR-CNN,使用过程中均固定模型参数,不进行微调。本文使用 Resnet101最后一个卷积层的输出作为图像的特征表示,并通过双线性插值方法将所得图像特征维度固定到14×14×1024,以此作为图像的区域特征,对区域特征进行平均池化操作得到全局特征。
FasterR-CNN分为两个阶段,第 一阶段中,RegionProposalNetworks(RPN)层生成候选区域并进行第 一次边框回归。在第二阶段,Regionofinterest(Roi)池化层将上述所有候选区域特征的维度进行统一,之后,将所得特征输入全连接层进行多分类,同时,完成第二次边框回归,以获得物体的精准位置。本文将所有候选区域经 Roi池化层的输出作为该图像的区域特征,每个区域特征的维度固定为2048,对区域特征进行平均池化操作,得到图像的全局特征。
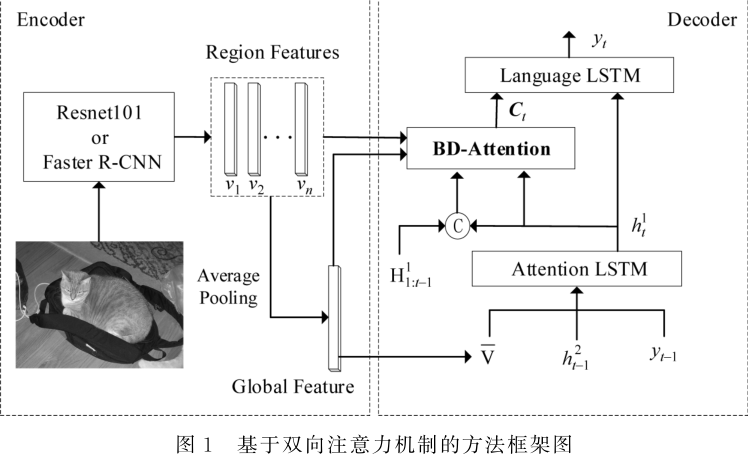
3.2方法框架
对于编码器部分,本文使用Resnet101和 FasterR-CNN分别进行了实验。使用上述任一种编码器,均可得到图像的区域特征(regionfeatures){v1,v2,…,vn}以及全局特征(globalfeature)V,区域特征和全局特征均用于双向注意力计算模块。具体地,双向注意力模块将完成以下两种计算:其一,根据语义信息筛选出重要的区域特征;其二,根据全局特征筛选出重要的语义信息。
本文使用了两阶段的训练策略 ,分别使用交叉熵损失和强化学习的优化方法训练模型 。在第 一阶段 ,根据真实描述序列y*1:T,模型参数θ以及前向传播得到的概率分布pθ,最小化交叉熵损失。在第二阶段,基于强化学习的 self-critical learning方法,直接对 CIDEr分值进行优化。训练目标是最小化负的期望分值。
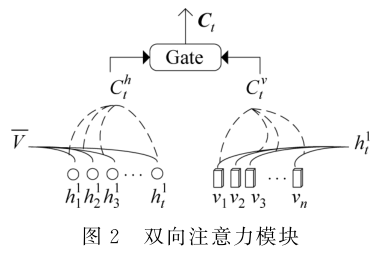
3.3双向注意力模块
本文提出的双向注意力机制(bi-directional attention,BD-Attention),将从两个方向进行注意力计算,完成图像特征和语义信息的两次交互。同时,筛选出较为重要的图像特征和语义信息,并通过门控单元获得融合两种模态信息的向量表示Ct,同时借助历史语义信息扩充当前的特征表示。
4.本方法存在的问题
图4展示了应用本文所提双向注意力方法生成结果较差的样例,本文对图中两类错误样例逐一进行了分析。对于样例 (a),本方法生成 “teddy bear”,但实际上是 一个身穿熊装的人,说明本文方法对复杂物体的识别有 一定局限性。对于样例(b),本方法生成“remotecontrol”,但对图中线路板并未描述,说明当多个物体同时存在时,本方法存在忽视个别核心实体的现象。
