kafka
1、kafka简介
kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),在kafka中主要涉及到四个基本名词:
Topic Kafka将消息种子分门别类, 每一类的消息称之为一个主题(Topic).
Producer 发布消息的对象称之为主题生产者.
Consumer 订阅消息并处理消息的对象称之为主题消费者
Broker 已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器称为一个代理(Broker). 消费者可以订阅一个或多个主题,并从Broker拉数据,从而消费这些已发布的消息。
生产者和消费者由开发人员编写,通过API连接到Broker Server进行数据操作
2、其他名词的辨析
-
controller: Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic增删、分区副本分配和 leader选举 等工作。Controller的管理工作都是依赖于Zookeeper的。controller通过各broker在zk中抢注产生。
-
分区partition:每个 Topic 可以划分多个分区(每个 Topic 至少有一个分区),同一 Topic 下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个 offset,它是消息在此分区中的唯一编号,Kafka 通过 offset 保证消息在分区内的顺序,offset 的顺序不跨分区,即 Kafka 只保证同一分区内消息有序。
-
leader:为保证可靠性patition可能需要进行备份,于是每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers。leader server 处理一切对 partition 的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,ISR(in-sync replica set)列表中的第一副本服务器会自动成为新的 leader,ISR列表由leader维护并写入zk中。
-
Consumer Group:逻辑上的概念,是Kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的Consumer,只有一个Consumer能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个Consumer消费。group内的Consumer可以使用多线程或多进程来实现,也可以将进程分散在多台机器上,Consumer的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了一个partition只能被一个Consumer消费(同一group内)。
3、kafka生产者
- 消息发送流程:Kafka的Producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main线程和Sender线程,以及一个线程共享变量——RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker。
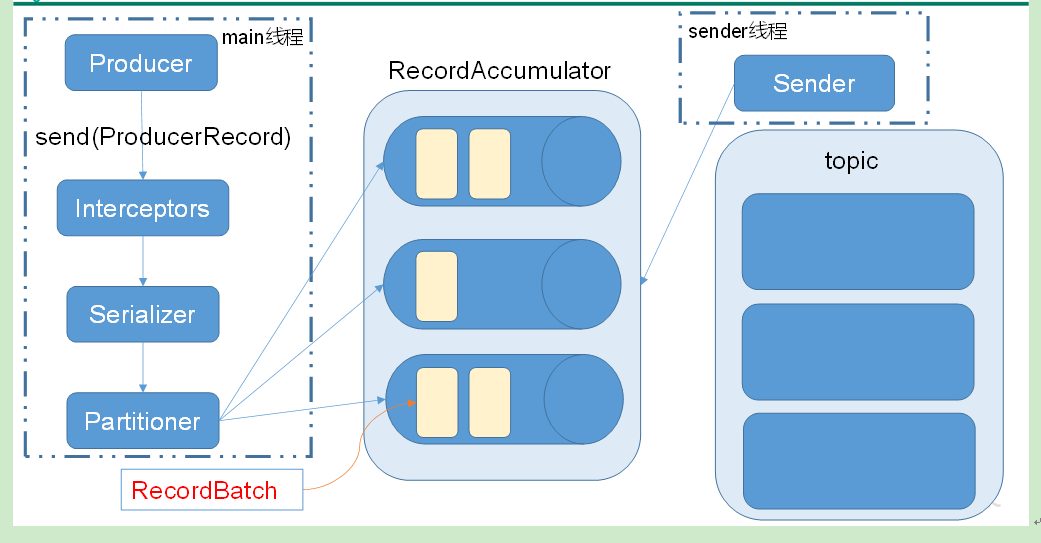
其中:batch.size:只有数据积累到batch.size之后,sender才会发送数据。
linger.ms:如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。
-
分区的原则:
(1)指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
(2)没有指明 partition 值但有 key 的情况下(kafka中的消息即为key-value对,key可以为空,value也可以为空),将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
(3)既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。
-
消息发送可靠级别acks=[0,1,-1]
4、kafka消息存储
-
kafka自己存储数据,不依赖HDFS。
-
kafka的数据是持久化的,被消费后不会消失
-
Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
-
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。
每个partition(目录)相当于一个巨型文件被平均分配到多个大小相等的segment(段)数据文件中(每个segment 文件中消息数量不一定相等),这种特性也方便old segment的删除,即方便已被消费的消息的清理,提高磁盘的利用率。每个partition只需要支持顺序读写就行,segment的文件生命周期由服务端配置参数(log.segment.bytes,log.roll.{ms,hours}等若干参数)决定。
每个segment对应两个文件——“.index”文件和“.log”文件。分别表示为segment索引文件和数据文件(引入索引文件的目的就是便于利用二分查找快速定位message位置)。这两个文件的命令规则为:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充。
这些文件位于一个文件夹下(partition目录),该文件夹的命名规则为:topic名称+分区序号。例如,first这个topic有三个分区,则其对应的文件夹为first-0,first-1,first-2。
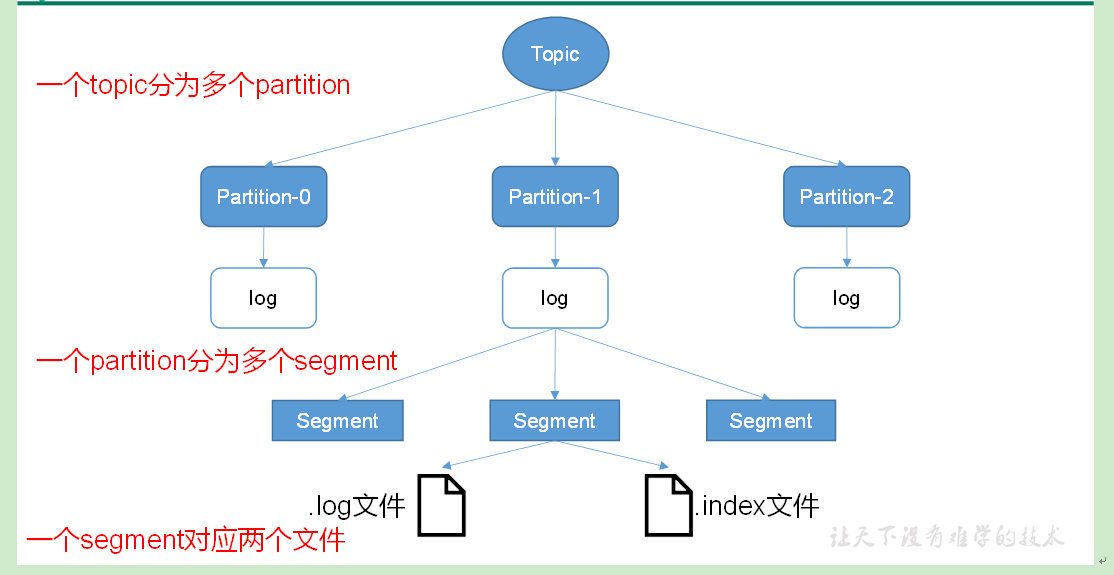
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。index和log文件以当前segment的第一条消息的offset命名。下图为index文件和log文件的结构示意图。

5、kafka消费者
-
消费方式:consumer采用pull(拉)模式从broker中读取数据。
- push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。
- pull模式则可以根据consumer的消费能力以适当的速率消费消息,但其不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
-
分区分配策略:确定那个partition由哪个consumer来消费,kafka中的默认消费逻辑是:一个分区只能被同一个消费组(ConsumerGroup)内的一个消费者消费。
-
Kafka有两种分配策略,一是RoundRobin,一是Range。
-
当以下事件发生时,Kafka 将会进行一次分区分配:
l 同一个 Consumer Group 内新增消费者
l 消费者离开当前所属的Consumer Group,包括shuts down 或 crashes
l 订阅的主题新增分区
-
6、版本特性的变化
- 在0.8.0版本后,producer不再通过zookeeper连接broker, 而是通过brokerlist(hadoop102:9092,hadoop103:9092)配置,直接和broker连接,只要能和一个broker连接上就能够获取到集群中其他broker上的信息,减轻zk负担。
- 每个消费者都要维护自己读取数据的offset。低版本0.9之前将offset保存在Zookeeper中,0.9及之后保存在Kafka的“__consumer_offsets”主题中。
7、一些值得注意的点
-
partitoin的数量可以多于broker。
-
消费者一定会有一个消费者组,可以指定消费者去消费一个topic的消息,也可以指定消费者组去消费一个topic的消息,指定时只能到topic级别,无法指定具体分区。