官方文档如下描述:
This variable indicates the number of equality ranges in an equality comparison condition when the optimizer should switch from using index dives to index statistics in estimating the number of qualifying rows. It applies to evaluation of expressions that have either of these equivalent forms, where the optimizer uses a nonunique index to look up col_name values:
col_name IN(val1, ..., valN)
col_name = val1 OR ... OR col_name = valN
In both cases, the expression contains N equality ranges. The optimizer can make row estimates using index dives or index statistics. If eq_range_index_dive_limit is greater than 0, the optimizer uses existing index statistics instead of index dives if there are eq_range_index_dive_limit or more equality ranges. Thus, to permit use of index dives for up to N equality ranges, set eq_range_index_dive_limit to N + 1. To disable use of index statistics and always use index dives regardless of N, set eq_range_index_dive_limit to 0.
简单来说就是根据eq_range_index_dive_limit参数设置的阀值来按照不同算法预估影响行数,对于IN或OR条件中的每个范围段视为一个元组,对于元组数低于eq_range_index_dive_limit参数阀值时使用index dive,高于阀值时使用
index dive:针对每个元组dive到index中使用索引完成元组数的估算,类似于使用索引进行实际查询得到影响行数
index statistics:即根据索引的统计数值进行估算,例如索引统计信息计算出每个等值影响100条数据,那么IN条件中包含5个等值则影响5*100条记录
在MySQL 5.6版本中引入eq_range_index_dive_limit参数,默认值为10,通常业务在使用IN时会超过10个值,因此在MySQL 5.7版本中将默认阀值设为200。
========================================
测试环境:
MySQL版本:5.6.20
测试用例表:t_disk_check_result_his,该表存放的1200+台服务器的约95万条磁盘数据
测试目的:通过各种角度来验证index dive和index statistics两种方式的优缺点
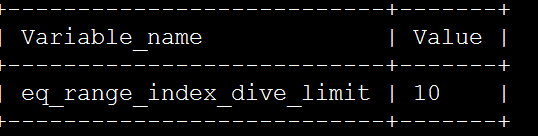
1、检查参数
show variables like '%eq_range_index_dive_limit%';
2、查看查询使用到的索引和表
SHOW INDEX FROM t_disk_check_result_his G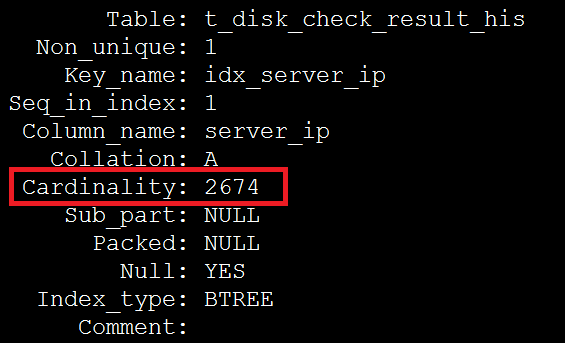
show table status like 't_disk_check_result_his' G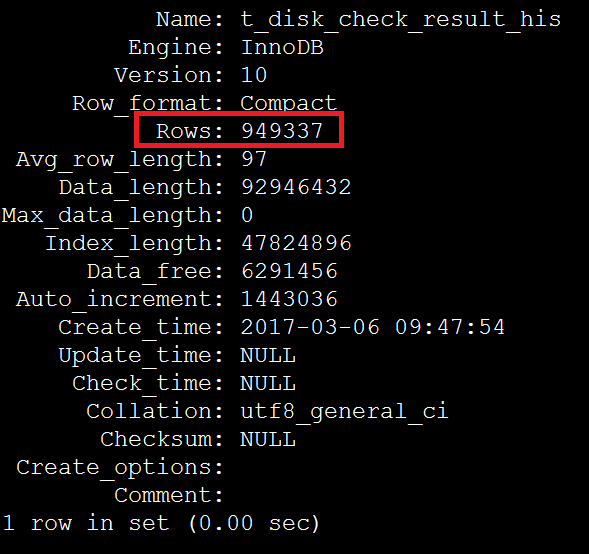
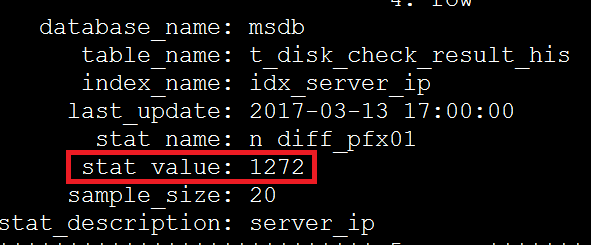
SELECT *
FROM innodb_index_stats
WHERE table_name='t_disk_check_result_his'G
3、查看SQK执行计划
DESC SELECT *
FROM t_disk_check_result_his
WHERE server_ip IN(
'1.1.1.1',
'1.1.1.2',
'1.1.1.3',
);
调整IN条件中的值数量,查看影响行数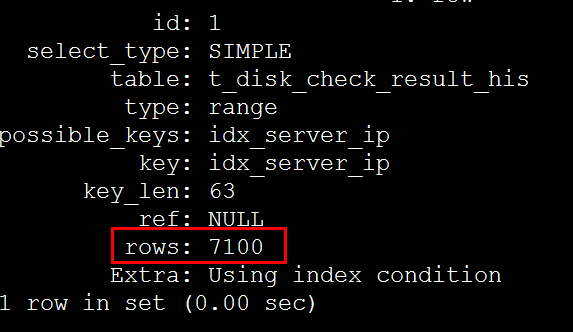
经过多次测试,得到以下数据:
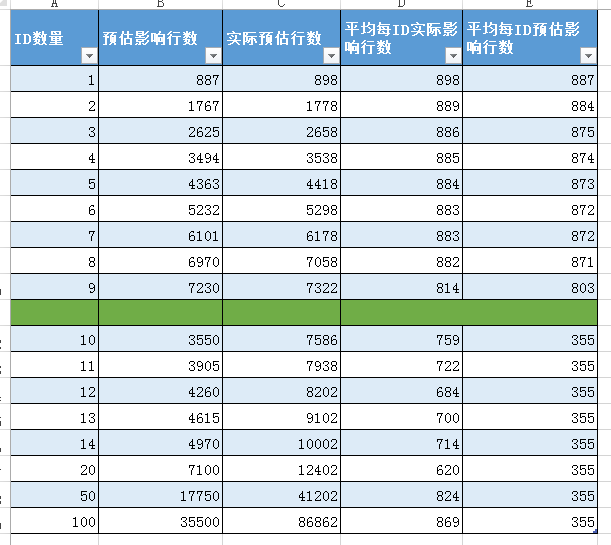
根据步骤2在索引上获得的数据,949337/2674=355 恰好等于超过eq_range_index_dive_limit参数阀值的平均影响行数,
实际执行发现,对于低于eq_range_index_dive_limit参数阀值的查询,预估影响行数和实际影响行数相差不多,较为准确。
========================================
使用profiling来查看, IN条件中包含9个server_ip时,即使用index dive方式消耗如下:
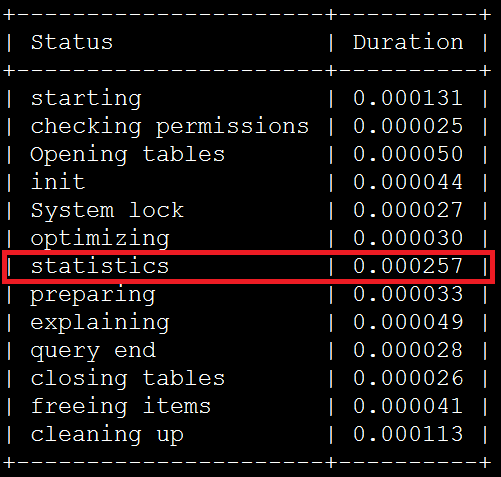
IN条件中包含11个server_ip时,即使用index dive方式消耗如下:
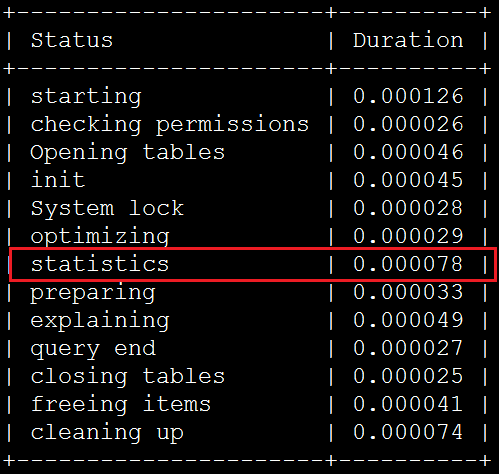
在statistics步骤中,使用index dive方式消耗的时间约是index statistics方式的3.3倍。
========================================
将eq_range_index_dive_limit参数设置为10,来测试IN条件中包含100个server_ip的资源消耗:
将eq_range_index_dive_limit参数设置为200,来测试IN条件中包含100个server_ip的资源消耗:
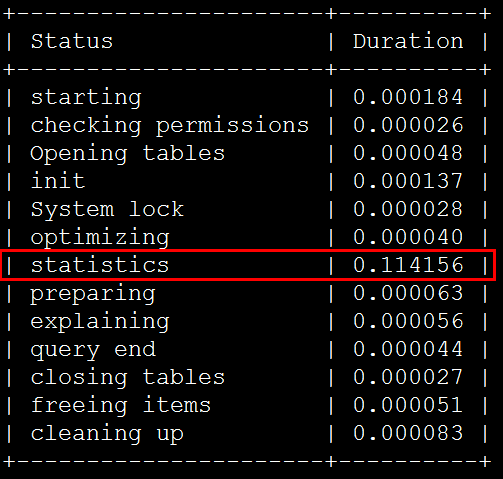
IN条件中包含100个server_ip的相同条件下,使用index dive方式消耗的时间约是index statistics方式的213倍
========================================
结论:
在使用IN或者OR等条件进行查询时,MySQL使用eq_range_index_dive_limit参数来判断使用index dive还是使用index statistics方式来进行预估:
1、当低于eq_range_index_dive_limit参数阀值时,采用index dive方式预估影响行数,该方式优点是相对准确,但不适合对大量值进行快速预估。
2、当大于或等于eq_range_index_dive_limit参数阀值时,采用index statistics方式预估影响行数,该方式优点是计算预估值的方式简单,可以快速获得预估数据,但相对偏差较大。
=======================================
参考连接:
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html
http://www.cnblogs.com/zhiqian-ali/p/6113829.html
http://blog.163.com/li_hx/blog/static/18399141320147521735442/
MYSQL 5.6 5.7处理数据分布不均的问题(eq_range_index_dive_limit参数)
处理数据分布不均,orace数据库使用额外的统计数据直方图来完成,而MYSQL
中统计数据只有索引的不同值这样一个统计数据,那么我们制出如下数据:
mysql> select * from test.testf;
+------+----------+
| id | name |
+------+----------+
| 1 | gaopeng |
| 2 | gaopeng1 |
| 3 | gaopeng1 |
| 4 | gaopeng1 |
| 5 | gaopeng1 |
| 6 | gaopeng1 |
| 7 | gaopeng1 |
| 8 | gaopeng1 |
| 9 | gaopeng1 |
| 10 | gaopeng1 |
+------+----------+
10 rows in set (0.00 sec)
name 上有一个普通二级索引
mysql> analyze table test.testf;
+------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+------------+---------+----------+----------+
| test.testf | analyze | status | OK |
+------------+---------+----------+----------+
1 row in set (0.21 sec)
分别作出如下执行计划:
mysql> explain select * from test.testf where name='gaopeng';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | testf | NULL | ref | name | name | 63 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from test.testf where name='gaopeng1';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | testf | NULL | ALL | name | NULL | NULL | NULL | 10 | 90.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可以看到执行计划是正确的,name='gaopeng'的只有一行选择了索引,name='gaopeng1'的有9行走了全表。
按理说如果只是记录不同的那么这两个语句的选择均为1/2,应该会造成执行计划错误,而MYSQL 5.6 5.7中
都做了正确的选择,那是为什么呢?
其实原因就在于 eq_range_index_dive_limit这个参数,我们来看一下trace
T@2: | | | | | | | | | | | opt: (null): "gaopeng1 <= name <= | T@3: | | | | | | | | | | | opt: (null): "gaopeng <= name <= g
T@2: | | | | | | | | | | | opt: ranges: ending struct | T@3: | | | | | | | | | | | opt: ranges: ending struct
T@2: | | | | | | | | | | | opt: index_dives_for_eq_ranges: 1 | T@3: | | | | | | | | | | | opt: index_dives_for_eq_ranges: 1
T@2: | | | | | | | | | | | opt: rowid_ordered: 1 | T@3: | | | | | | | | | | | opt: rowid_ordered: 1
T@2: | | | | | | | | | | | opt: using_mrr: 0 | T@3: | | | | | | | | | | | opt: using_mrr: 0
T@2: | | | | | | | | | | | opt: index_only: 0 | T@3: | | | | | | | | | | | opt: index_only: 0
T@2: | | | | | | | | | | | opt: rows: 9 | T@3: | | | | | | | | | | | opt: rows: 1
T@2: | | | | | | | | | | | opt: cost: 11.81 | T@3: | | | | | | | | | | | opt: cost: 2.21
我们可以看到 index_dives_for_eq_ranges均为1,rows: 9 rows: 1都是正确的,那么可以确定是index_dives_for_eq_ranges的作用,实际上
这是一个参数eq_range_index_dive_limit来决定的(equality range optimization of many-valued comparisions),默认为
mysql> show variables like '%eq%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| eq_range_index_dive_limit | 200 |
在官方文档说这个取值是等值范围比较的时候有多少个需要比较的值
如:
id=1 or id=2 or id=3 那么他取值就是3+1=4
而这种方法会得到精确的数据,但是增加的是时间成本,如果将
eq_range_index_dive_limit 设置为1:则禁用此功能
eq_range_index_dive_limit 设置为0:则始终开启
eq_range_index_dive_limit 设置为N:则满足N-1个这样的域。
那么我们设置为eq_range_index_dive_limit=1 后看看
mysql> explain select * from test.testf where name='gaopeng1';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | testf | NULL | ref | name | name | 63 | const | 5 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from test.testf where name='gaopeng';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | testf | NULL | ref | name | name | 63 | const | 5 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
可以看到执行计划已经错误 name='gaopeng1' 明显不应该使用索引,我们再来看看trace
T@3: | | | | | | | | | | | opt: ranges: ending struct
T@3: | | | | | | | | | | | opt: index_dives_for_eq_ranges: 0
T@3: | | | | | | | | | | | opt: rowid_ordered: 1
T@3: | | | | | | | | | | | opt: using_mrr: 0
T@3: | | | | | | | | | | | opt: index_only: 0
T@3: | | | | | | | | | | | opt: rows: 5
T@3: | | | | | | | | | | | opt: cost: 7.01
index_dives_for_eq_ranges: 0 rows: 5这个5就是10*1/2导致的,而index_dives_for_eq_ranges=0就是禁用了
在5.7官方文档 p1231页也有相应说明