一、原因分析
一般而言,slave相对master延迟较大,其根本原因就是slave上的复制线程没办法真正做到并发。简单说,在master上是并发模式(以InnoDB引擎为主)完成事务提交的,而在slave上,复制线程只有一个sql thread用于binlog的apply,所以难怪slave在高并发时会远落后master。
ORACLE MySQL 5.6版本开始支持多线程复制,配置选项 slave_parallel_workers 即可实现在slave上多线程并发复制。不过,它只能支持一个实例下多个 database 间的并发复制,并不能真正做到多表并发复制。因此在较大并发负载时,slave还是没有办法及时追上master,需要想办法进行优化。
另一个重要原因是,传统的MySQL复制是异步(asynchronous)的,也就是说在master提交完后,才在slave上再应用一遍,并不是真正意义上的同步。哪怕是后来的Semi-sync Repication(半同步复制),也不是真同步,因为它只保证事务传送到slave,但没要求等到确认事务提交成功。既然是异步,那肯定多少会有延迟。因此,严格意义上讲,MySQL复制不能叫做MySQL同步(处女座的面试官有可能会在面试时把说成MySQL同步的一律刷掉哦)。
另外,不少人的观念里,slave相对没那么重要,因此就不会提供和master相同配置级别的服务器。有的甚至不但使用更差的服务器,而且还在上面跑多实例。
综合这两个主要原因,slave想要尽可能及时跟上master的进度,可以尝试采用以下几种方法:
采用MariaDB发行版,它实现了相对真正意义上的并行复制,其效果远比ORACLE MySQL好的很多。在我的场景中,采用MariaDB作为slave的实例,几乎总是能及时跟上master。每个表都要显式指定主键,如果没有指定主键的话,会导致在row模式下,每次修改都要全表扫描,尤其是大表就非常可怕了,延迟会更严重,甚至导致整个slave库都被挂起,可参考案例:mysql主键的缺少导致备库hang;
应用程序端多做些事,让MySQL端少做事,尤其是和IO相关的活动,例如:前端通过内存CACHE或者本地写队列等,合并多次读写为一次,甚至消除一些写请求;
进行合适的分库、分表策略,减小单库单表复制压力,避免由于单库单表的的压力导致整个实例的复制延迟;
其他提高IOPS性能的几种方法,根据效果优劣,我做了个简单排序:
更换成SSD,或者PCIe SSD等IO设备,其IOPS能力的提升是普通15K SAS盘的数以百倍、万倍,甚至几十万倍计;
加大物理内存,相应提高InnoDB Buffer Pool大小,让更多热数据放在内存中,降低发生物理IO的频率;
调整文件系统为 XFS 或 ReiserFS,相比ext3可以极大程度提高IOPS能力。在高IOPS压力下,相比ext4有更稳健的IOPS表现(有人认为 XFS 在特别的场景下会有很大的问题,但我们除了剩余磁盘空间少于10%时引发丢数据外,其他的尚未遇到);
调整RAID级别为raid 1+0,它相比raid1、raid5等更能提高IOPS性能。如果已经全部是SSD设备了,可以2块盘做成RAID 1,或者多快盘做成RAID 5(并且可以设置全局热备盘,提高阵列容错性),甚至有些土豪用户直接将多块SSD盘组成RAID 50;
调整RAID的写cache策略为WB或FORCE WB,详情请参考:常用PC服务器阵列卡、硬盘健康监控 以及 PC服务器阵列卡管理简易手册;
调整内核的io scheduler,优先使用deadline,如果是SSD,则可以使用noop策略,相比默认的cfq,个别请客下对IOPS的性能提升至少是数倍的。
二 、如何解决
平时接收的比较多关于主备延时的报警:
|
1 |
|
相信slave 延迟是MySQL dba 遇到的一个老生长谈的问题了。先来分析一下slave延迟带来的风险
a. 异常情况下,主从HA无法切换。HA 软件需要检查数据的一致性,延迟时,主备不一致。
b. 备库复制hang会导致备份失败(flush tables with read lock会900s超时)
c. 以 slave 为基准进行的备份,数据不是最新的,而是延迟。
面对此类问题我们如何解决 ,如何规避?分析一下导致备库延迟的几种原因
1. ROW模式无主键、无索引或索引区分度不高.
有如下特征
a. show slave status 显示position一直没有变
b. show open tables 显示某个表一直是 in_use 为 1
c. show create table 查看表结构可以看到无主键,或者无任何索引,或者索引区分度很差。
解决方法:
a. 找到表区分度比较高的几个字段, 可以使用这个方法判断:
|
1 2 |
|
如果2个查询count(*)的结果差不多,说明可以对这些字段加索引
b. 备库stop slave;
可能会执行比较久,因为需要回滚事务。
c. 备库
|
1 2 |
|
老的版本slave应用binlog时只会选择第一个索引,需要把新加的索引放在最前面,可以先把老的索引删掉,建新的索引,再把老的索引建上。可以放到一个sql中执行。
d. 备库start slave
如果是innodb,可以通过show innodb status来查看 rows_inserted,updated,deleted,selected这几个指标来判断。
如果每秒修改的记录数比较多,说明复制正在以比较快的速度执行。
2 MIXED模式无索引或SQL慢
在从库上show full processlist 查看到正在执行的SQL。
解决方法:
a. SQL比较简单, 则检查是否缺少索引,并添加索引。
b. 另一类是 insert into select from的语句,如果select 里包含group by,多表关联,可能效率会比较低。
这类可以到主库把binlog_format改成row。
3 主库上有大事务,导致从库延时
现象解析binlog 发现类似于下图的情况看
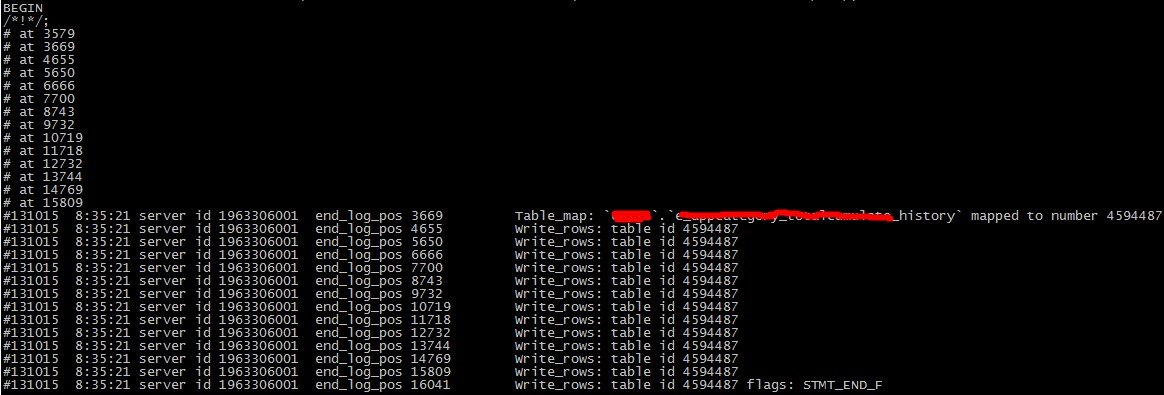
解决方法:
与开发沟通,增加缓存,异步写入数据库,减少直接对db的大量写入。
4. 主库写入频繁,从库压力跟不上导致延时
此类原因的主要现象是数据库的 IUD 操作非常多,slave由于sql_thread单线程的原因追不上主库。
解决方法:
a 升级从库的硬件配置,比如ssd,fio.
b 使用@丁奇的预热工具-relay fetch
在备库sql线程执行更新之前,预先将相应的数据加载到内存中,并不能提高sql_thread线程执行sql的能力,也不能加快io_thread线程读取日志的速度。
c 使用多线程复制 阿里MySQL团队实现的方案--基于行的并行复制。
该方案允许对同一张表进行修改的两个事务并行执行,只要这两个事务修改了表中的不同的行。这个方案可以达到事务间更高的并发度,但是局限是必须使用Row格式的binlog。因为只有使用 Row格式的binlog才可以知道一个事务所修改的行的范围,而使用Statement格式的binlog只能知道修改的表对象。
5. 数据库中存在大量myisam表,在备份的时候导致slave 延迟

由于xtrabackup 工具备份到最后会执行flash tables with read lock ,对数据库进行锁表以便进行一致性备份,然后对于myisam表 锁,会阻碍salve_sql_thread 停滞运行进而导致hang
该问题目前的比较好的解决方式是修改表结构为innodb存储引擎的表。