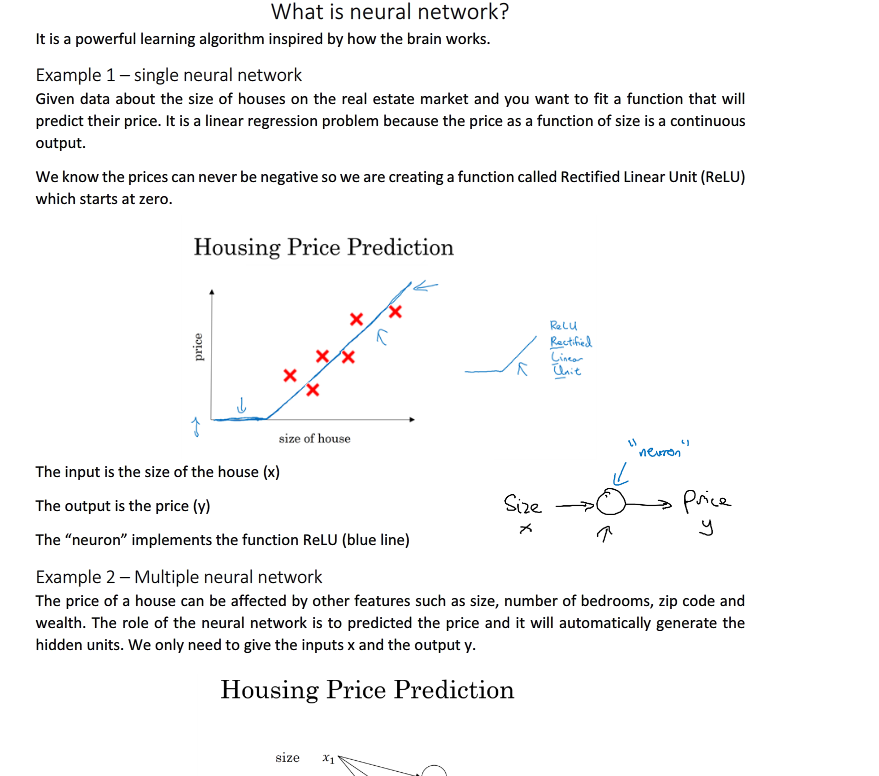
神经网络是一种灵感来自于大脑工作的算法.
举一个例子:假设房子的价格与房子大小有关,为了预测房子的价格,我们可以先可以搜集一批房子价格对有房子大小的数据,为了能够进行分析,我们需要建立一个模型,来实现输入size x时能够输出对应的price y.
将我们所搜集到的数据关系绘制成一个图形表示,他们是一些离散型的点,我们可以通过一条直线拟合这些点
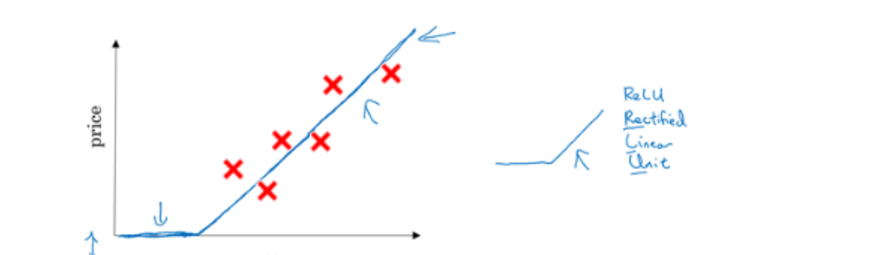
而因为房子的价格不会是负数,所以我们要修正这条直线的前面部分,上图神经元的预测函数(蓝色折线)在神经网络应用中比较常见。我们把这个函数称为ReLU函数,即线性整流函数(Rectified Linear Unit,
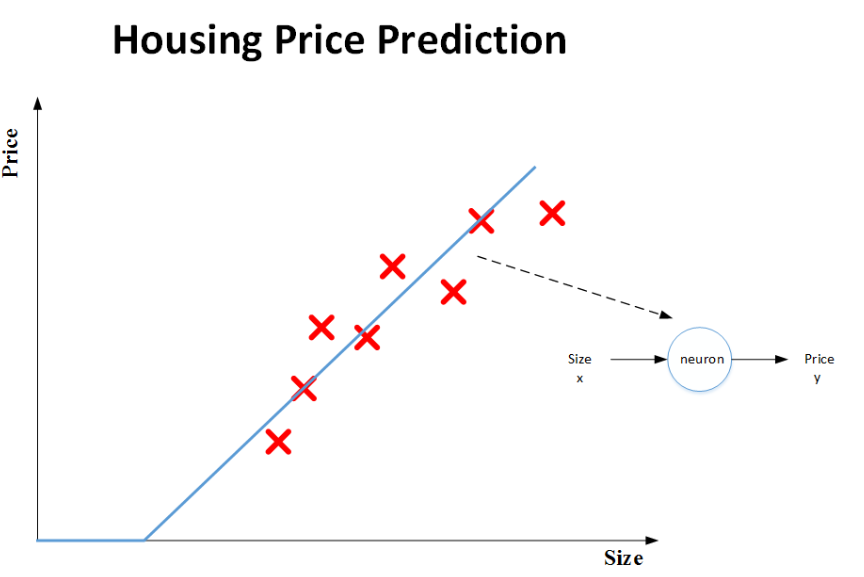
其实这个简单的模型(蓝色折线)就可以看成是一个神经网络,而且几乎是一个最简单的神经网络。我们把该房价预测用一个最简单的神经网络模型来表示,该神经网络的输入x是房屋面积,输出y是房屋价格,中间包含了一个神经元(neuron),即房价预测函数(蓝色折线)。该神经元的功能就是实现函数f(x)的功能。
在实际问题中,房子的价格可能还和许多因素有关,
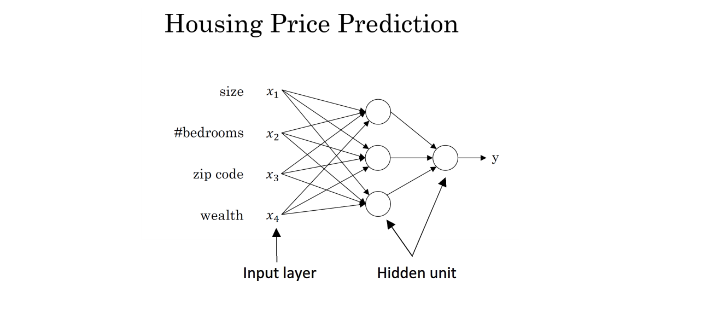
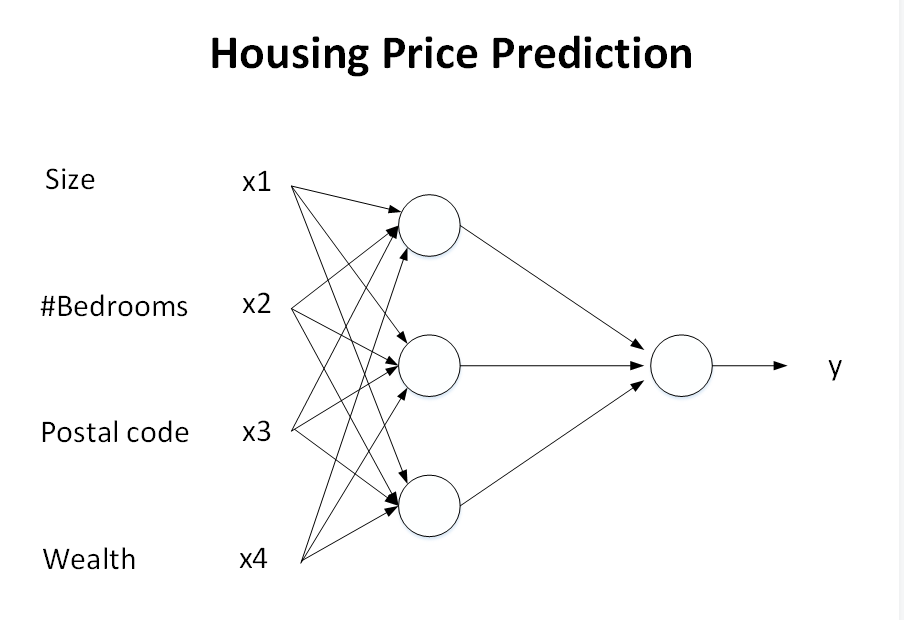
现在,我们把上面举的房价预测的例子变得复杂一些,而不是仅仅使用房屋面积一个判断因素。例如,除了考虑房屋面积(size)之外,我们还考虑卧室数目(#bedrooms)。这两点实际上与家庭成员的个数(family size)有关。还有,房屋的邮政编码(zip code/postal code),代表了该房屋位置的交通便利性,是否需要步行还是开车?即决定了可步行性(walkability)。另外,还有可能邮政编码和地区财富水平(wealth)共同影响了房屋所在地区的学校质量(school quality)。如下图所示,该神经网络共有三个神经元,分别代表了family size,walkability和school quality。每一个神经元都包含了一个ReLU函数(或者其它非线性函数)。那么,根据这个模型,我们可以根据房屋的面积和卧室个数来估计family size,根据邮政编码来估计walkability,根据邮政编码和财富水平来估计school quality。最后,由family size,walkability和school quality等这些人们比较关心的因素来预测最终的房屋价格。
所以,在这个例子中,x是size,#bedrooms,zip code/postal code和wealth这四个输入;y是房屋的预测价格。这个神经网络模型包含的神经元个数更多一些,相对之前的单个神经元的模型要更加复杂。那么,在建立一个表现良好的神经网络模型之后,在给定输入x时,就能得到比较好的输出y,即房屋的预测价
实际上,上面这个例子真正的神经网络模型结构如下所示。它有四个输入,分别是size,#bedrooms,zip code和wealth。在给定这四个输入后,神经网络所做的就是输出房屋的预测价格y。图中,三个神经元所在的位置称之为中间层或者隐藏层(x所在的称之为输入层,y所在的称之为输出层),每个神经元与所有的输入x都有关联(直线相连).
Supervised Learning with Netural Networks

在监督学习中,我们得到了一个数据集,并且已经知道我们的正确输出应该是什么样的,因为我们知道输入和输出之间是有关系的。1监督学习问题被分为“回归”和“分类”问题。在回归问题中,我们试图在连续输出中预测结果,这意味着我们试图将输入变量映射到某个连续函数。在分类问题中,我们试图在一个离散的输出中预测结果。换句话说,我们试图将输入变量映射到离散的类别中。
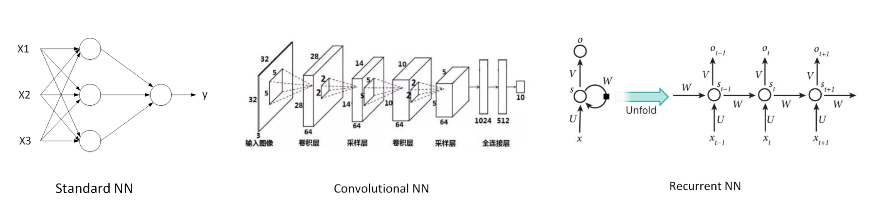
有不同类型的神经网络,例如经常使用的卷积神经网络(CNN)。用于图像应用和递归神经网络(RNN)用于一维序列数据,如将英语翻译成汉语或文本记录等时间组成部分。至于自动驾驶,它是一种混合神经网络架构。CNN和RNN是比较常用的神经网络模型。下图给出了Standard NN,Convolutional NN和Recurrent NN的神经网络结构图。
结构化数据指的是具有定义含义的东西,比如价格、年龄,而非结构化数据指的是像像素这样的东西。原始音频、文本。Structured Data通常指的是有实际意义的数据。例如房价预测中的size,#bedrooms,price等;例如在线广告中的User Age,Ad ID等。这些数据都具有实际的物理意义,比较容易理解。而Unstructured Data通常指的是比较抽象的数据,例如Audio,Image或者Text。以前,计算机对于Unstructured Data比较难以处理,而人类对Unstructured Data却能够处理的比较好,例如我们第一眼很容易就识别出一张图片里是否有猫,但对于计算机来说并不那么简单。现在,值得庆幸的是,由于深度学习和神经网络的发展,计算机在处理Unstructured Data方面效果越来越好,甚至在某些方面优于人类。总的来说,神经网络与深度学习无论对Structured Data还是Unstructured Data都能处理得越来越好,并逐渐创造出巨大的实用价值。我们在之后的学习和实际应用中也将会碰到许多Structured Data和Unstructured Data。
Why is deep learning taking off?
我们可以先画一张图
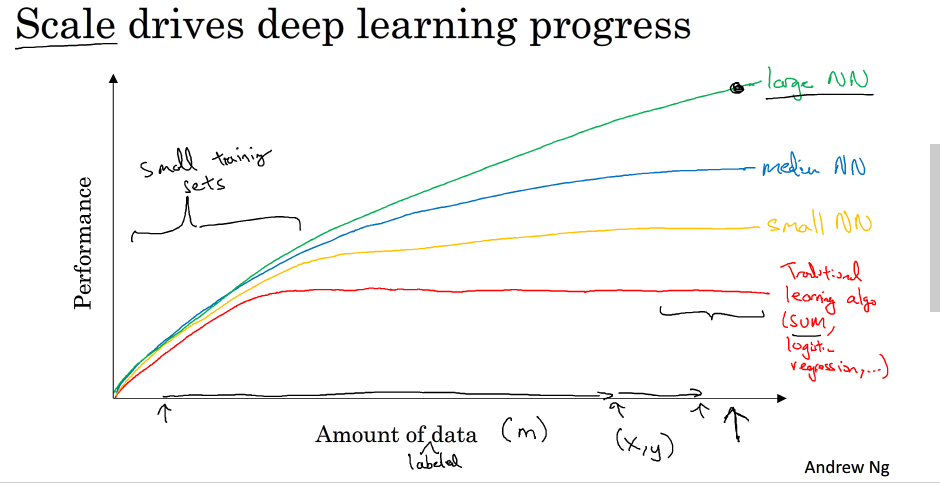
上图共有4条曲线。其中,最底下的那条红色曲线代表了传统机器学习算法的表现,例如是SVM,logistic regression,decision tree等。当数据量比较小的时候,传统学习模型的表现是比较好的。但是当数据量很大的时候,其表现很一般,性能基本趋于水平。红色曲线上面的那条黄色曲线代表了规模较小的神经网络模型(Small NN)。它在数据量较大时候的性能优于传统的机器学习算法。黄色曲线上面的蓝色曲线代表了规模中等的神经网络模型(Media NN),它在在数据量更大的时候的表现比Small NN更好。最上面的那条绿色曲线代表更大规模的神经网络(Large NN),即深度学习模型。从图中可以看到,在数据量很大的时候,它的表现仍然是最好的,而且基本上保持了较快上升的趋势。值得一提的是,近些年来,由于数字计算机的普及,人类进入了大数据时代,每时每分,互联网上的数据是海量的、庞大的。如何对大数据建立稳健准确的学习模型变得尤为重要。传统机器学习算法在数据量较大的时候,性能一般,很难再有提升。然而,深度学习模型由于网络复杂,对大数据的处理和分析非常有效。所以,近些年来,在处理海量数据和建立复杂准确的学习模型方面,深度学习有着非常不错的表现。然而,在数据量不大的时候,例如上图中左边区域,深度学习模型不一定优于传统机器学习算法,性能差异可能并不大。
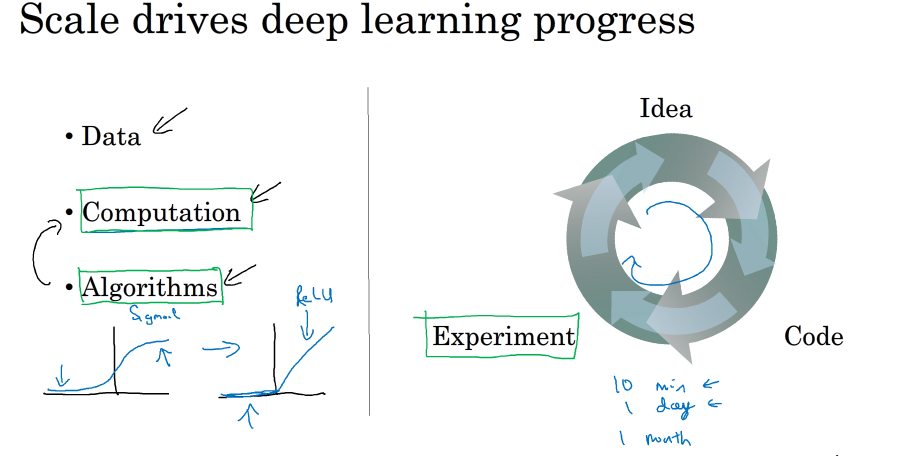
所以说,现在深度学习如此强大的原因归结为三个因素:
-
Data
-
Computation
-
Algorithms
其中,数据量的几何级数增加,加上GPU出现、计算机运算能力的大大提升,使得深度学习能够应用得更加广泛。另外,算法上的创新和改进让深度学习的性能和速度也大大提升。举个算法改进的例子,之前神经网络神经元的激活函数是Sigmoid函数,后来改成了ReLU函数。之所以这样更改的原因是对于Sigmoid函数,在远离零点的位置,函数曲线非常平缓,其梯度趋于0,所以造成神经网络模型学习速度变得很慢。然而,ReLU函数在x大于零的区域,其梯度始终为1,尽管在x小于零的区域梯度为0,但是在实际应用中采用ReLU函数确实要比Sigmoid函数快很多。
构建一个深度学习的流程是首先产生Idea,然后将Idea转化为Code,最后进行Experiment。接着根据结果修改Idea,继续这种Idea->Code->Experiment的循环,直到最终训练得到表现不错的深度学习网络模型。如果计算速度越快,每一步骤耗时越少,那么上述循环越能高效进行。