一下笔记来源
##一、SQLite3 数据库
SQLite3 可使用 sqlite3 模块与 Python 进行集成,一般 python 2.5 以上版本默认自带了sqlite3模块,因此不需要用户另外下载。
在 学习基本语法之前先来了解一下数据库是使用流程吧 ↓↓↓
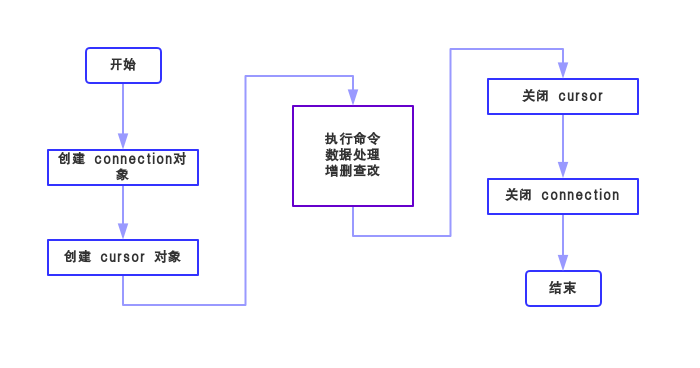
所以,首先要创建一个数据库的连接对象,即connection对象,语法如下:
sqlite3.connect(database [,timeout,其他可选参数])
function: 此API打开与SQLite数据库文件的连接。如果成功打开数据库,则返回一个连接对象。
database: 数据库文件的路径,或 “:memory:” ,后者表示在RAM中创建临时数据库。
timeout: 指定连接在引发异常之前等待锁定消失的时间,默认为5.0(秒)
有了connection对象,就能创建游标对象了,即cursor对象,如下:
connection.cursor([cursorClass])
function: 创建一个游标,返回游标对象,该游标将在Python的整个数据库编程中使用。
接下来,看看connection对象 和 cursor对象的 “技能” 吧 ↓↓↓
| 方法 | 说明 |
| connect.cursor() | 上述,返回游标对象 |
| connect.execute(sql [,parameters]) | 创建中间游标对象执行一个sql命令 |
| connect.executemany(sql [,parameters]) | 创建中间游标对象执行一个sql命令 |
| connect.executescript(sql_script) | 创建中间游标对象, 以脚本的形式执行sql命令 |
| connect.total_changes() | 返回自打开数据库以来,已增删改的行的总数 |
| connect.commit() | 提交当前事务,不使用时为放弃所做的修改,即不保存 |
| connect.rollback() | 回滚自上次调用commit()以来所做的修改,即撤销 |
| connect.close() | 断开数据库连接 |
| 方法 | 说明 |
| cursor.execute(sql [,parameters]) | 执行一个sql命令 |
| cursor.executemany(sql,seq_of_parameters) | 对 seq_of_parameters 中的所有参数或映射执行一个sql命令 |
| cursor.executescript(sql_script) | 以脚本的形式一次执行多个sql命令 |
| cursor.fetchone() | 获取查询结果集中的下一行,返回一个单一的序列,当没有更多可用的数据时,则返回 None。 |
| cursor.fetchmany([size=cursor.arraysize]) | 获取查询结果集中的下一行组,返回一个列表。当没有更多的可用的行时,则返回一个空的列表。size指定特定行数。 |
| cursor.fetchall() | 获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。 |
##
个人实践
首先爬取信息并存为csv文件
# -*- coding: utf-8 -*-
"""
Created on Wed May 29 12:14:18 2019
爬取中国最好大学排名
@author: lenovo
"""
import requests
from bs4 import BeautifulSoup
import pandas
# 1. 获取网页内容
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except Exception as e:
print("Error:", e)
return ""
# 2. 分析网页内容并提取有用数据
def fillTabelList(soup): # 获取表格的数据
tabel_list = [] # 存储整个表格数据
Tr = soup.find_all('tr')
for tr in Tr:
Td = tr.find_all('td')
if len(Td) == 0:
continue
tr_list = [] # 存储一行的数据
for td in Td:
tr_list.append(td.string)
tabel_list.append(tr_list)
return tabel_list
# 3. 可视化展示数据
def PrintTableList(tabel_list, num):
# 输出前num行数据
print("{1:^2}{2:{0}^10}{3:{0}^5}{4:{0}^5}{5:{0}^8}".format(chr(12288), "排名", "学校名称", "省市", "总分", "生源质量"))
for i in range(num):
text = tabel_list[i]
print("{1:{0}^2}{2:{0}^10}{3:{0}^5}{4:{0}^8}{5:{0}^10}".format(chr(12288), *text))
# 4. 将数据存储为csv文件
def saveAsCsv(filename, tabel_list):
FormData = pandas.DataFrame(tabel_list)
FormData.columns = ["排名", "学校名称", "省市", "总分", "生源质量", "培养结果", "科研规模", "科研质量", "顶尖成果", "顶尖人才", "科技服务", "产学研合作", "成果转化"]
FormData.to_csv(filename, encoding='utf-8', index=False)
if __name__ == "__main__":
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html"
html = getHTMLText(url)
soup = BeautifulSoup(html, features="html.parser")
data = fillTabelList(soup)
saveAsCsv("D:\daxuepaiming.csv", data)
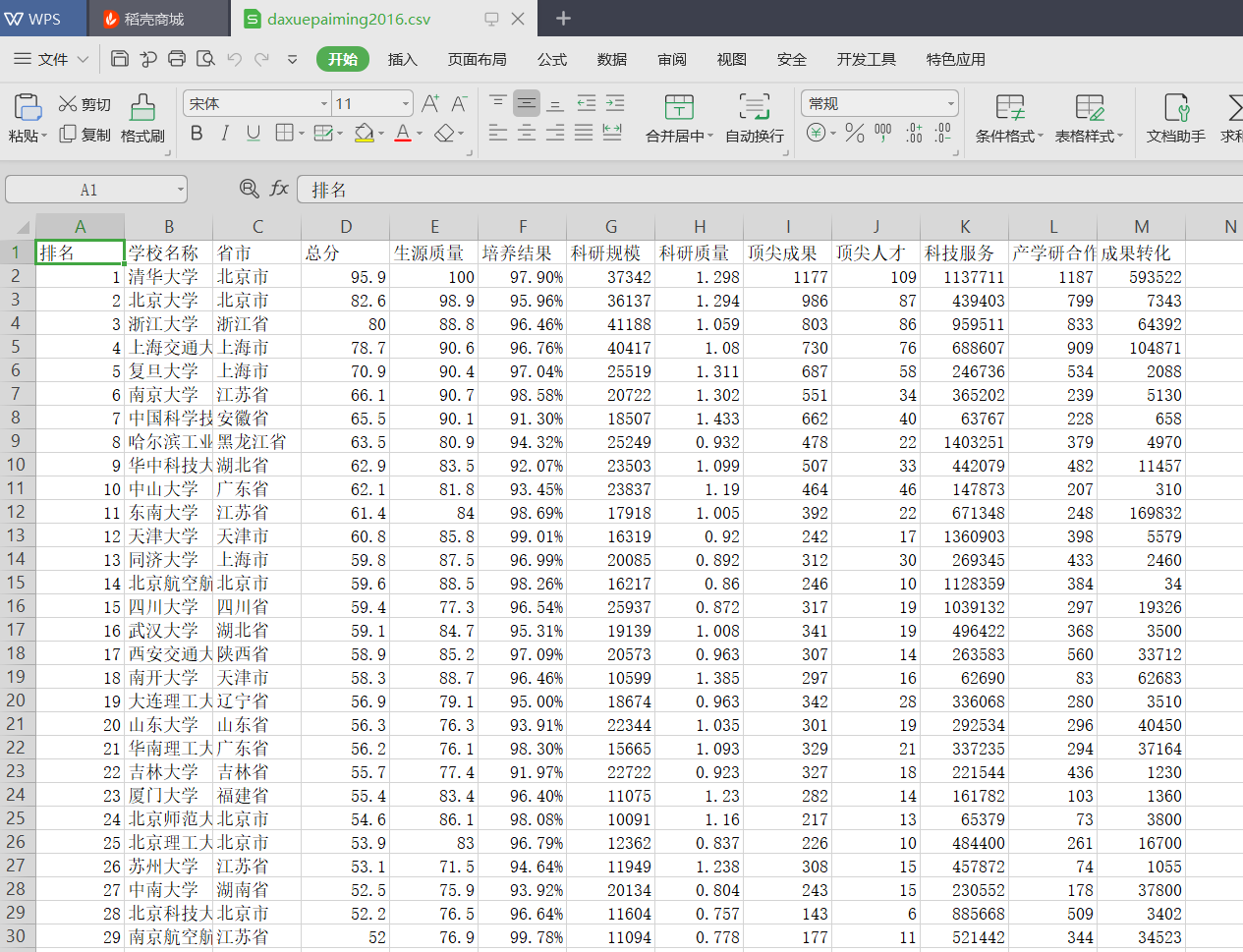
csv文件部分展示
然后将CSV文件写入数据库
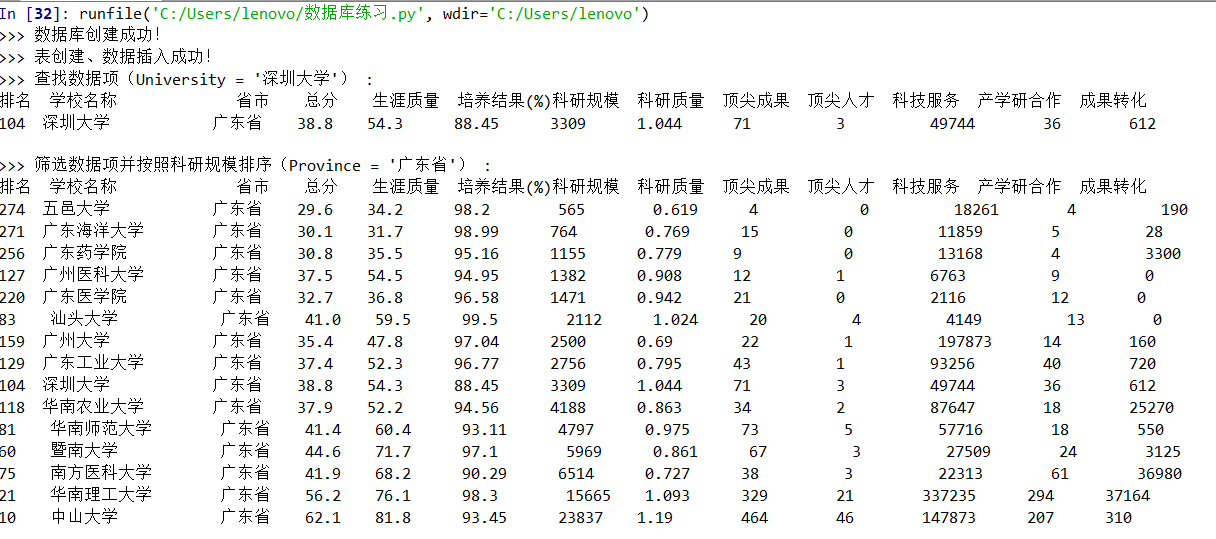
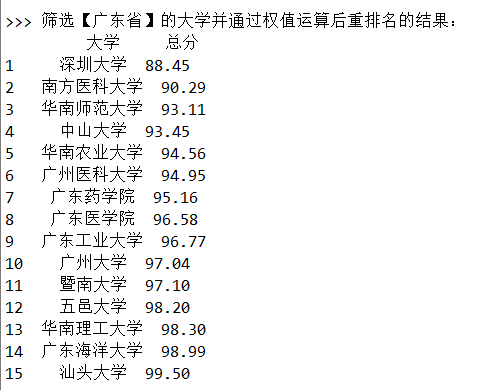
# -*- coding: utf-8 -*- """ Created on Wed May 29 22:15:35 2019 数据库操作 @author: lenovo """ import sqlite3 from pandas import DataFrame class SQL_method: ''' function: 可以实现对数据库的基本操作 ''' def __init__(self, dbName, tableName, data, columns, COLUMNS, Read_All=True): ''' function: 初始化参数 dbName: 数据库文件名 tableName: 数据库中表的名称 data: 从csv文件中读取且经过处理的数据 columns: 用于创建数据库,为表的第一行 COLUMNS: 用于数据的格式化输出,为输出的表头 Read_All: 创建表之后是否读取出所有数据 ''' self.dbName = dbName self.tableName = tableName self.data = data self.columns = columns self.COLUMNS = COLUMNS self.Read_All = Read_All def creatTable(self): ''' function: 创建数据库文件及相关的表 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 创建表 connect.execute("CREATE TABLE {}({})".format(self.tableName, self.columns)) # 提交事务 connect.commit() # 断开连接 connect.close() def destroyTable(self): ''' function: 删除数据库文件中的表 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 删除表 connect.execute("DROP TABLE {}".format(self.tableName)) # 提交事务 connect.commit() # 断开连接 connect.close() def insertDataS(self): ''' function: 向数据库文件中的表插入多条数据 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 插入多条数据 connect.executemany("INSERT INTO {} VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?)".format(self.tableName), self.data) #for i in range(len(self.data)): # connect.execute("INSERT INTO university VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?)", data[i]) # 提交事务 connect.commit() # 断开连接 connect.close() def getAllData(self): ''' function: 得到数据库文件中的所有数据 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 创建游标对象 cursor = connect.cursor() # 读取数据 cursor.execute("SELECT * FROM {}".format(self.tableName)) dataList = cursor.fetchall() # 断开连接 connect.close() return dataList def searchData(self, conditions, IfPrint=True): ''' function: 查找特定的数据 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 创建游标 cursor = connect.cursor() # 查找数据 cursor.execute("SELECT * FROM {} WHERE {}".format(self.tableName, conditions)) data = cursor.fetchall() # 关闭游标 cursor.close() # 断开数据库连接 connect.close() if IfPrint: self.printData(data) return data def deleteData(self, conditions): ''' function: 删除数据库中的数据 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 插入多条数据 connect.execute("DELETE FROM {} WHERE {}".format(self.tableName, conditions)) # 提交事务 connect.commit() # 断开连接 connect.close() def printData(self, data): print("{1:{0}^3}{2:{0}<11}{3:{0}<4}{4:{0}<4}{5:{0}<5}{6:{0}<5}{7:{0}^5}{8:{0}^5}{9:{0}^5}{10:{0}^5}{11:{0}^5}{12:{0}^6}{13:{0}^5}".format(chr(12288), *self.COLUMNS)) for i in range(len(data)): print("{1:{0}<4.0f}{2:{0}<10}{3:{0}<5}{4:{0}<6}{5:{0}<7}{6:{0}<8}{7:{0}<7.0f}{8:{0}<8}{9:{0}<7.0f}{10:{0}<6.0f}{11:{0}<9.0f}{12:{0}<6.0f}{13:{0}<6.0f}".format(chr(12288), *data[i])) def run(self): try: # 创建数据库文件 self.creatTable() print(">>> 数据库创建成功!") # 保存数据到数据库 self.insertDataS() print(">>> 表创建、数据插入成功!") except: print(">>> 数据库已创建!") # 读取所有数据 if self.Read_All: self.printData(self.getAllData()) def get_data(fileName): ''' function: 读取获得大学排名的数据 并 将结果返回 ''' data = [] # 打开文件 f = open(fileName, 'r', encoding='utf-8') # 按行读取文件 for line in f.readlines(): # 替换掉其中的换行符和百分号 替换百分号是为了方便之后的排序和运算 line = line.replace(' ', '') line = line.replace('%','') # 将字符串按照 ',' 分割为列表 line = line.split(',') for i in range(len(line)): # 使用 异常处理 避开 出现中文无法转换 的错误 try: # 将空值填充为 0 if line[i] == '': line[i] = '0' # 将数字转换为数值 line[i] = eval(line[i]) except: continue data.append(tuple(line)) # EN_columns、CH_columns 分别为 用于数据库创建、数据的格式化输出 EN_columns = "Rank real, University text, Province text, Grade real, SourseQuality real, TrainingResult real, ResearchScale real, ReserchQuality real, TopResult real, TopTalent real, TechnologyService real, Cooperation real, TransformationResults real" CH_columns = ["排名", "学校名称", "省市", "总分", "生涯质量", "培养结果(%)", "科研规模", "科研质量", "顶尖成果", "顶尖人才", "科技服务", "产学研合作", "成果转化"] return data[1:], EN_columns, CH_columns if __name__ == "__main__": # =================== 设置和得到基本数据 =================== fileName = "D:\daxuepaiming2016.csv" data, EN_columns, CH_columns = get_data(fileName) dbName = "02daxuepaiming2016.db" tableName = "daxuepaiming2016" # ================= 创建一个SQL_method对象 ================== SQL = SQL_method(dbName, tableName, data, EN_columns, CH_columns, False) # =================== 创建数据库并保存数据 =================== SQL.run() # =================== 在数据库中查找数据项 =================== # 查找记录并输出结果 print(">>> 查找数据项(University = '深圳大学') :") SQL.searchData("University = '深圳大学'", True) # ================= 在数据库中筛选数据项并排序 ================== # 将选取广东省的数据 并 对科研规模大小排序 print(" >>> 筛选数据项并按照科研规模排序(Province = '广东省') :") SQL.searchData("Province = '广东省' ORDER BY ResearchScale", True) # =============== 对数据库中的数据进行重新排序操作 ================ # 定义权值 Weight = [0, 1, 0, 0, 0, 0, 0, 0, 0] value, sum = [], 0 # 获取 Province = '广东省' 的所有数据 sample = SQL.searchData("Province = '广东省'", False) # 按照权值求出各个大学的总得分 for i in range(len(sample)): for j in range(len(Weight)): sum += sample[i][4+j] * Weight[j] value.append(sum) sum = 0 # 将结果通过 pandas 的 DataFrame 方法组成一个二维序列 university = [university[1] for university in sample] uv, tmp = [], [] for i in range(len(university)): tmp.append(university[i]) tmp.append(value[i]) uv.append(tmp) tmp = [] df = DataFrame(uv, columns=list(("大学", "总分"))) df = df.sort_values('总分') df.index = [i for i in range(1, len(uv)+1)] # 输出结果 print(" >>> 筛选【广东省】的大学并通过权值运算后重排名的结果: ", df) # ===================== 在数据库中删除数据项 ===================== SQL.deleteData("Province = '北京市'") SQL.deleteData("Province = '广东省'") SQL.deleteData("Province = '山东省'") SQL.deleteData("Province = '山西省'") SQL.deleteData("Province = '江西省'") SQL.deleteData("Province = '河南省'") print(" >>> 数据删除成功!") SQL.printData(SQL.getAllData()) # ====================== 在数据库中删除表 ======================== SQL.destroyTable() print(">>> 表删除成功!")
效果: