1 import openpyxl 2 3 class ExceltoExcel(): 4 5 def __init__(self, file): 6 self.universityData = {} 7 self.wb = openpyxl.load_workbook(file) 8 self.wb_new =openpyxl.Workbook() # 新建一个表格来存储生成的数据 9 self.sheet = self.wb.active 10 self.new_sheet = self.wb_new.active # 新表单 11 self.maxrow = self.sheet.max_row 12 self.maxcol = self.sheet.max_column 13 14 15 def todict(self): 16 ''' 17 统计每个大学全部的获奖数量,分别列出是几等奖和对应的数量 18 {'同济大学':{'一等奖':{'team':1,'num'=3},'二等奖':{'team':2,'num'=6},'三等奖':{'team':1,'num'=3},'成功参与奖':{'team':1,'num'=3}}, 19 '清华大学':{'一等奖':{'team':1,'num'=3},'二等奖':{'team':1,'num'=3},'三等奖':{'team':1,'num'=3},'成功参与奖':{'team':1,'num'=3}},...} 20 统计所有人数 21 Fill in universityData with each rewardship‘s popularity 22 ''' 23 # tolal_team = self.maxrow 24 for row in range(2, self.maxrow + 1): 25 # 取每个单元格的数据 26 sheet_col = ['F', 'H', 'J'] 27 rewardcell = self.sheet['D' + str(row)].value # D列奖项 28 rewards = ['一等奖', '二等奖', '三等奖', '成功参与奖'] 29 for k in sheet_col: 30 university = self.sheet[k + str(row)].value # 每列大学的名称 31 # team = self.sheet['C' + str(row)].value # C列队伍 32 # 确定键值 33 self.universityData.setdefault(university, {}) 34 for reward in rewards: 35 if reward == rewardcell: 36 self.universityData[university].setdefault(rewardcell, {'team': 0, 'num': 0}) 37 self.universityData[university][rewardcell]['num'] += 1 # 统计各个奖项的所有人数 38 else: 39 self.universityData[university].setdefault(reward, {'team': 0, 'num': 0}) 40 41 if k == 'F': 42 self.universityData[university][rewardcell]['team'] += 1 # 只统计队长所在大学 43 self.universityData = sorted(self.universityData.items(), key=lambda item: item[0]) # 按照键值排序返回元祖 44 self.universityData = dict(self.universityData) # 将元祖转换成字典 45 # print('universityData', self.universityData) 46 # print(type(self.universityData)) 47 return self.universityData 48 49 # 查找单个键 50 def find(self, target, dictData, notFound='没找到'): 51 # 倒序查找第一个出现的需要查找的键的值 52 queue = [dictData] # 将字典存入列表 53 while len(queue) > 0: 54 data = queue.pop() # data是在queue中取出的最后一个元素,也就是原始字典;此时的queue为空列表[] 55 print('data', data) 56 for key, value in data.items(): 57 if key == target: 58 return value 59 elif type(value) == dict: 60 queue.append(value) 61 return notFound 62 63 # 有多个同名键在字典里时,可以用这个方法 64 def findAll(self, target, dictData, notFound=[]): 65 # 倒序查找所有出现的需要查找的键的值 66 queue = [dictData] 67 result = [] 68 while len(queue) > 0: 69 data = queue.pop() 70 for key, value in data.items(): 71 if key == target: 72 result.append(value) 73 elif type(value) == dict: 74 queue.append(value) 75 if not result: result = notFound 76 return result 77 78 def write_list_to_excel(self, dictData, num_list, team_list): 79 list_slice = [] # 人数切片 80 team_slice = [] # 队伍切片 81 sublist_sum = [] # 每个人数切片的和 82 team_sum = [] # 每个队伍切片的和 83 k = 0 84 row_1 = ['学校名称','一等奖','二等奖','三等奖','成功参与奖','总人数','队伍数量'] 85 for i in range(len(row_1)): 86 self.new_sheet.cell(row=1,column=i+1,value=row_1[i]) 87 university_name = [] 88 for key in dictData.keys(): 89 university_name.append(key) 90 for index, name in enumerate(university_name): 91 self.new_sheet['A'+str(index+2)] = name 92 while k < len(num_list): 93 sub_list = num_list[k:k+4] # 人数子集 94 team_sub = team_list[k:k+4] # 队伍子集 95 list_slice.append(sub_list) # 切片后存入列表 96 team_slice.append(team_sub) 97 sumlist = sum(sub_list) # 计算每个子集的和 98 teamsum = sum(team_sub) 99 sublist_sum.append(sumlist) # 将每个子集的和加入列表 100 team_sum.append(teamsum) 101 k += 4 102 if k > len(num_list): 103 break 104 for row in range(2, len(university_name)+2): 105 for col in range(2, 6): 106 self.new_sheet.cell(column=col, row=row, value=list_slice[row-2][col-2]) 107 self.new_sheet.cell(column=6, row=row, value=sublist_sum[row-2]) 108 self.new_sheet.cell(column=7, row=row, value=team_sum[row - 2]) 109 self.wb_new.save('result.xlsx') 110 print('共有{}支队伍参赛'.format(sum(team_sum))) 111 return university_name, list_slice, sublist_sum 112 113 114 if __name__ == '__main__': 115 excel1 = ExceltoExcel('example_A.xlsx') 116 dictData = excel1.todict() 117 # find_one = excel1.find('team', dictData) 118 find_num = excel1.findAll('num', dictData) 119 find_team = excel1.findAll('team', dictData) 120 find_num.reverse() 121 find_team.reverse() 122 # print(find_num) 123 # print(find_team) 124 university, list_slice, sublist_sum = excel1.write_list_to_excel(dictData,find_num, find_team) 125 # print('university name', university) 126 # print('list_slice', list_slice) 127 # print('sublist_sum', sublist_sum)
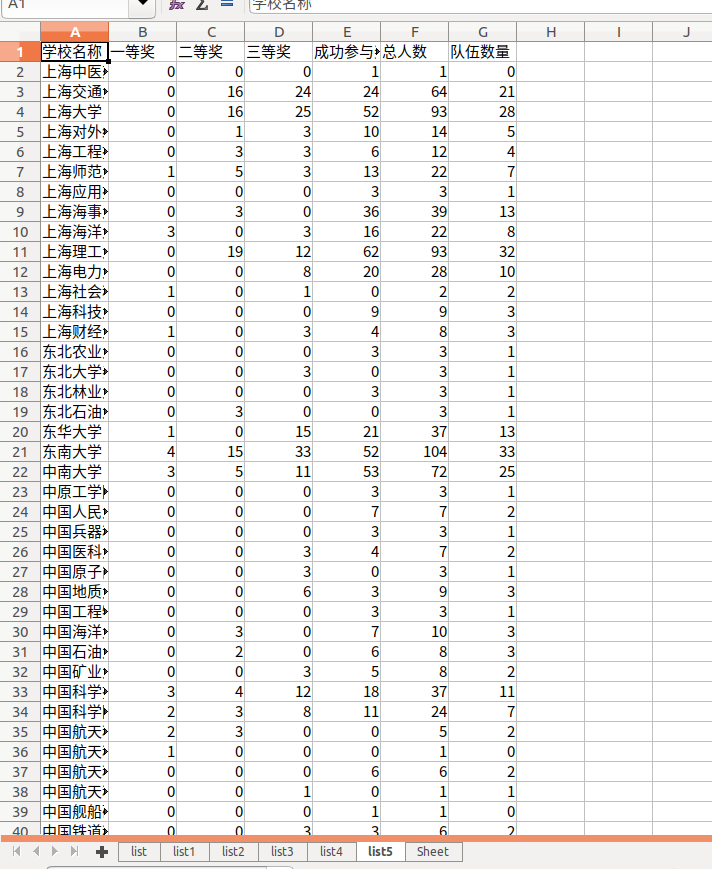
保存新的表格(部分):
统计了一个表格中每个大学每个奖项的获奖人数与队伍数量,队伍只统计队长所在的学校

以下代码读取某一文件夹下的所有Excel表格(比如读取A~F题获奖名单总共6个Excel表格),统计每道题也就是每个表格中每个大学的获奖情况并将其写入同一个Excel结果文件中:
1 import openpyxl 2 import os 3 4 class ExceltoExcel(): 5 6 def __init__(self, file, new_sheet): 7 self.universityData = {} 8 self.wb = openpyxl.load_workbook(file) 9 # self.wb_new =openpyxl.Workbook() # 新建一个表格来存储生成的数据 10 self.sheet = self.wb.active 11 self.new_sheet = new_sheet # 新表单 12 self.maxrow = self.sheet.max_row 13 self.maxcol = self.sheet.max_column 14 15 16 def todict(self): 17 ''' 18 统计每个大学全部的获奖数量,分别列出是几等奖和对应的数量 19 {'同济大学':{'一等奖':{'team':1,'num'=3},'二等奖':{'team':2,'num'=6},'三等奖':{'team':1,'num'=3},'成功参与奖':{'team':1,'num'=3}}, 20 '清华大学':{'一等奖':{'team':1,'num'=3},'二等奖':{'team':1,'num'=3},'三等奖':{'team':1,'num'=3},'成功参与奖':{'team':1,'num'=3}},...} 21 统计所有人数 22 Fill in universityData with each rewardship‘s popularity 23 ''' 24 # tolal_team = self.maxrow 25 for row in range(2, self.maxrow + 1): 26 # 取每个单元格的数据 27 sheet_col = ['F', 'H', 'J'] 28 rewardcell = self.sheet['D' + str(row)].value # D列奖项 29 rewards = ['一等奖', '二等奖', '三等奖', '成功参与奖'] 30 for k in sheet_col: 31 university = self.sheet[k + str(row)].value # 每列大学的名称 32 # team = self.sheet['C' + str(row)].value # C列队伍 33 # 确定键值 34 self.universityData.setdefault(university, {}) 35 for reward in rewards: 36 if reward == rewardcell: 37 self.universityData[university].setdefault(rewardcell, {'team': 0, 'num': 0}) 38 self.universityData[university][rewardcell]['num'] += 1 # 统计各个奖项的所有人数 39 else: 40 self.universityData[university].setdefault(reward, {'team': 0, 'num': 0}) 41 42 if k == 'F': 43 self.universityData[university][rewardcell]['team'] += 1 # 只统计队长所在大学 44 self.universityData = sorted(self.universityData.items(), key=lambda item: item[0]) # 按照键值排序返回元祖 45 self.universityData = dict(self.universityData) # 将元祖转换成字典 46 # print('universityData', self.universityData) 47 # print(type(self.universityData)) 48 return self.universityData 49 50 # 查找单个键 51 def find(self, target, dictData, notFound='没找到'): 52 # 倒序查找第一个出现的需要查找的键的值 53 queue = [dictData] # 将字典存入列表 54 while len(queue) > 0: 55 data = queue.pop() # data是在queue中取出的最后一个元素,也就是原始字典;此时的queue为空列表[] 56 print('data', data) 57 for key, value in data.items(): 58 if key == target: 59 return value 60 elif type(value) == dict: 61 queue.append(value) 62 return notFound 63 64 # 有多个同名键在字典里时,可以用这个方法 65 def findAll(self, target, dictData, notFound=[]): 66 # 倒序查找所有出现的需要查找的键的值 67 queue = [dictData] 68 result = [] 69 while len(queue) > 0: 70 data = queue.pop() 71 for key, value in data.items(): 72 if key == target: 73 result.append(value) 74 elif type(value) == dict: 75 queue.append(value) 76 if not result: result = notFound 77 return result 78 79 def write_list_to_excel(self, dictData, num_list, team_list): 80 list_slice = [] # 人数切片 81 team_slice = [] # 队伍切片 82 sublist_sum = [] # 每个人数切片的和 83 team_sum = [] # 每个队伍切片的和 84 k = 0 85 row_1 = ['学校名称','一等奖','二等奖','三等奖','成功参与奖','总人数','队伍数量'] 86 for i in range(len(row_1)): 87 self.new_sheet.cell(row=1,column=i+1,value=row_1[i]) 88 university_name = [] 89 for key in dictData.keys(): 90 university_name.append(key) 91 for index, name in enumerate(university_name): 92 self.new_sheet['A'+str(index+2)] = name 93 while k < len(num_list): 94 sub_list = num_list[k:k+4] # 人数子集 95 team_sub = team_list[k:k+4] # 队伍子集 96 list_slice.append(sub_list) # 切片后存入列表 97 team_slice.append(team_sub) 98 sumlist = sum(sub_list) # 计算每个子集的和 99 teamsum = sum(team_sub) 100 sublist_sum.append(sumlist) # 将每个子集的和加入列表 101 team_sum.append(teamsum) 102 k += 4 103 if k > len(num_list): 104 break 105 for row in range(2, len(university_name)+2): 106 for col in range(2, 6): 107 self.new_sheet.cell(column=col, row=row, value=list_slice[row-2][col-2]) 108 self.new_sheet.cell(column=6, row=row, value=sublist_sum[row-2]) 109 self.new_sheet.cell(column=7, row=row, value=team_sum[row - 2]) 110 return university_name, list_slice, sublist_sum, team_sum 111 112 113 if __name__ == '__main__': 114 file_path = './file' # excel文件路径 115 files = [] # 存储excel文件名 116 list = os.listdir(file_path) # 列出excel文件路径下所有的文件 117 list.sort(key=lambda x: x[4:5]) # 按照题目顺序排序 118 # print('list', list) 119 for i in range(len(list)): 120 item = os.path.join(file_path, list[i]) 121 files.append(item) 122 # print('files', files) 123 wb_new = openpyxl.Workbook() # 新建一个表格来存储生成的数据 124 f = open('result.txt', 'w') 125 for k,file in enumerate(files): 126 new_sheet = wb_new.create_sheet('list', index=k) # 插入新表单 127 excel = ExceltoExcel(file, new_sheet) 128 dictData = excel.todict() # 得到当前表格排序后的字典 129 # find_one = excel1.find('team', dictData) 130 find_num = excel.findAll('num', dictData) # 查找当前表格每个大学每个奖项的获奖人数 131 find_team = excel.findAll('team', dictData) # # 查找当前表格每个大学每个奖项的获奖队伍数,只统计队长所在的学校 132 find_num.reverse() # 正序排列 133 find_team.reverse() # 正序排列 134 # print(find_num) 135 # print(find_team) 136 _, _, _, team_sum = excel.write_list_to_excel(dictData,find_num, find_team) 137 wb_new.save('result.xlsx') 138 # print('university name', university) 139 # print('list_slice', list_slice) 140 # print('sublist_sum', sublist_sum) 141 title = file.split('/')[2][4:5] # 字符串分割提取题目,原标题为'./file/2019A.xlsx' 142 print('{}题共有{}支队伍获奖'.format(title, sum(team_sum))) 143 f.write('{}题共有{}支队伍获奖 '.format(title, sum(team_sum)))
1 A题共有781支队伍获奖 2 B题共有888支队伍获奖 3 C题共有1057支队伍获奖 4 D题共有4259支队伍获奖 5 E题共有4193支队伍获奖 6 F题共有781支队伍获奖
我这里的F题获奖名单和A题是相同的,所以A和F的统计结果相同。