《Python创建线程》一节中,介绍了 2 种创建线程的方法,通过分析线程的执行过程我们得知,当程序中包含多个线程时,CPU 不同一直被特定的线程霸占,而是轮流执行各个线程。
那么,CPU 在轮换执行线程过程中,线程都经历了什么呢?线程从创建到消亡的整个过程,可能会历经 5 种状态,分别是新建、就绪、运行、阻塞和死亡,如图 1 所示。
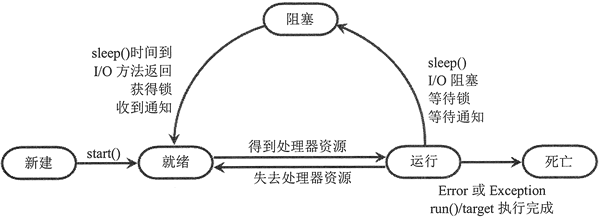
图 1 线程状态转换图
线程的新建和就绪状态
无论是通过 Thread 类直接实例化对象创建线程,还是通过继承自 Thread 类的子类实例化创建线程,新创建的线程在调用 start() 方法之前,不会得到执行,此阶段的线程就处于新建状态。
从图 1 可以看出,只有当线程刚刚创建,且未调用 start() 方法时,该线程才处于新建状态,而一旦线程调用 start() 方法之后,线程将无法再回到新建状态。
当位于新建状态的线程调用 start() 方法后,该线程就转换到就绪状态。所谓就绪,就是告诉 CPU,该线程已经可以执行了,但是具体什么时候执行,取决于 CPU 什么时候调度它。换句话说,如果一个线程处于就绪状态,只能说明此线程已经做好了准备,随时等待 CPU 调度执行,并不是说执行了 start() 方法此线程就会立即被执行。
值得注意的一点是,start() 方法只能由处于新建状态的线程调用,而一旦调用 start() 方法,线程状态就会由新建状态转为就绪状态。这意味着,每一个线程最多只能调用一次 start() 方法。如果多次调用,则 Python 解释器将抛出 RuntimeError 异常。
另外,线程由新建状态转到就绪状态,只有一个办法,就是调用 start() 方法。有读者可能会问,直接调用 Thread 类构造方法中 target 参数指定的函数,或者直接调用 Thread 子类中的 run() 实例方法,不可以吗?当然不可以,这 2 种方法是可以执行目标代码,但是由主线程 MianThread 负责执行,而不是由新创建的子线程负责执行。
原因很简单,一方面 Python解释器会将它们看做是普通的函数调用和类方法调用。另一方面,由于新建的线程属于新建状态而不是就绪状态,因此不会得到 CPU 的调度。
线程的运行和阻塞状态
当位于就绪状态的线程得到了 CPU,并开始执行 target 参数执行的目标函数或者 run() 方法,就表明当前线程处于运行状态。
但如果当前有多个线程处于就绪状态(等待 CPU 调度)时,处于运行状态的线程将无法一直霸占 CPU 资源,为了使其它线程也有执行的机会,CPU 会在一定时间内强制当前运行的线程让出 CPU 资源,以供其他线程使用。而对于获得 CPU 调度却没有执行完毕的线程,就会进入阻塞状态。
目前几乎所有的桌面和服务器操作系统,都采用的是抢占式优先级调度策略。即 CPU 会给每一个就绪线程一段固定时间来处理任务,当该时间用完后,系统就会阻止该线程继续使用 CPU 资源,让其他线程获得执行的机会。而对于具体选择那个线程上 CPU,不同的平台采用不同的算法,比如先进先出算法(FIFO)、时间片轮转算法、优先级算法等,每种算法各有优缺点,适用于不同的场景。
除此之外,如果处于运行状态的线程发生如下几种情况,也将会由运行状态转到阻塞状态:
- 线程调用了 sleep() 方法;
- 线程等待接收用户输入的数据;
- 线程试图获取某个对象的同步锁(后续章节会详细讲解)时,如果该锁被其他线程所持有,则当前线程进入阻塞状态;
- 线程调用 wait() 方法,等待特定条件的满足;
以上几种情况都会导致线程阻塞,只有解决了线程遇到的问题之后,该线程才会有阻塞状态转到就绪状态,继续等待 CPU 调度(如图 1 所示)。以上 4 种可能发生线程阻塞的情况,解决措施分别如下:
- sleep() 方法规定的时间已过;
- 线程接收到了用户输入的数据;
- 其他线程释放了该同步锁,并由该线程获得;
- 调用 set() 方法发出通知;
以上涉及到的线程方法以及它们的含义和用法,会在后续章节做详细讲解。
线程死亡状态
对于获得 CPU 调度却未执行完毕的线程,它会转入阻塞状态,待条件成熟之后继续转入就绪状态,重复争取 CPU 资源,直到其执行结束。执行结束的线程将处于死亡状态。
线程执行结束,除了正常执行结束外,如果程序执行过程发生异常(Exception)或者错误(Error),线程也会进入死亡状态。
对于处于死亡状态的线程,有以下 2 点需要注意:
- 主线程死亡,并不意味着所有线程全部死亡。也就是说,主线程的死亡,不会影响子线程继续执行;反之也是如此。
- 对于死亡的线程,无法再调用 start() 方法使其重新启动,否则 Python 解释器将抛出 RuntimeError 异常。