一、Python2与Python3的区别
1、从宏观上考虑,Python2重复代码太多,错误率高,不够规范。Python崇尚的是语言简洁、优美、清晰。Python3更加规范,重复代码少;
2、Python2默认的编码是ASCII码,无法正确识别中文,而Python3默认的代码是utf-8,能够正确识别中文;
3、Python2中print打印时后面可以不用加(),但是Python3中print打印时必须加上(),否则会报错;
4、Python2中有range和xrange(生成器),但是Python3中只有range ;
5、Python3中的input,在Python2中是raw_input。
二、“=”、“==”与“is”的区别
1、“=” :赋值 把后面的值赋给前面
2、“==” :比较前后的值是否相等
3、“is” :比较的是前后的变量内存地址
4、id : 显示的是内存地址
li1 = [1,2,3] li2 = li1 li3 = li2 print(id(li1),id(li2))
三、数字和字符串
小数据池:在一定范围内当多个变量被赋值的是一个相同的数值时,其占用的内存地址是一样的。
int里面有小数据概念,范围是-5------- 256
i1 = 6 i2 = 6 print(id(i1),id(i2)) i1 = 300 i2 = 300 print(id(i1),id(i2))
字符串也有小数据池概念,不过没有什么具体准确的标准,暂时只发现两个规律
1、不能含有特殊字符;
2、s*20 还是同一个地址,s*21以后都是两个地址
剩下的list、dict、tuple、set都没有小数据池概念。
四、编码
ASCII码:一个字符用8位来表示,共1个字节;
unicode码:有16位和32位的两种,现在大部分用的是32位来表示一个字符,共4个字节;
utf-8码:最少用8位来表示一个字符,英文时是8位来表示的,共1个字节,中文是用24位来表示的,共3个字节,欧洲其他国家文字是用16未来表示的,共2个字节。
gbk码:表示英文时是用8位来表示的,共1个字节,中文是用16位来表示的,共2个字节。
注意:
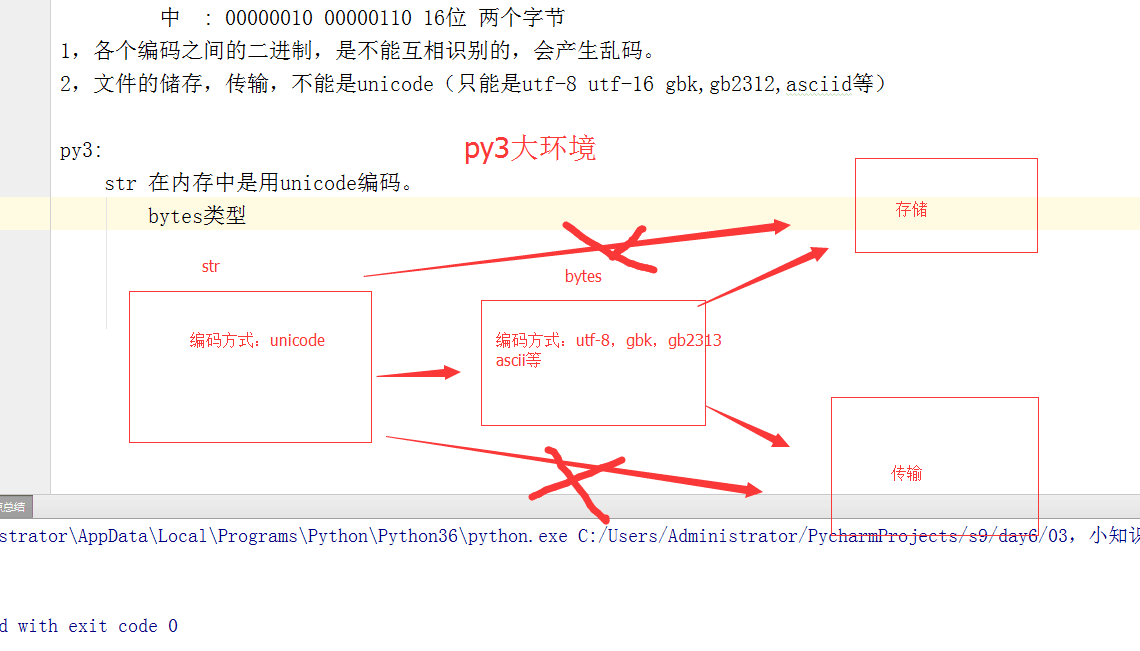
1、各个编码之间的二进制是不能互相识别的,会产生乱码;
2、文件的储存、传输不能是unicode(只能是utf-8、utf-16、gbk、gb2312,ascii等)
s11 = s1.encode('utf-8') s11 = s1.encode('gbk') print(s11) s2 = '中国' s22 = s2.encode('utf-8') s22 = s2.encode('gbk') print(s22)
bytes类型
对于英文:
str :表现形式:s = 'alex' 编码方式: 010101010 unicode
bytes :表现形式:s = b'alex' 编码方式: 000101010 utf-8 gbk。。。。
对于中文:
str :表现形式:s = '中国' 编码方式: 010101010 unicode
bytes :表现形式:s = b'xe91e91e01e21e31e32' 编码方式: 000101010 utf-8 gbk。。。。