1.Transformer原理:
一种完全基于Attention机制来加速深度学习训练过程的算法模型;Transformer最大的优势在于其在并行化处理上做出的贡献。
1.1 网络结构
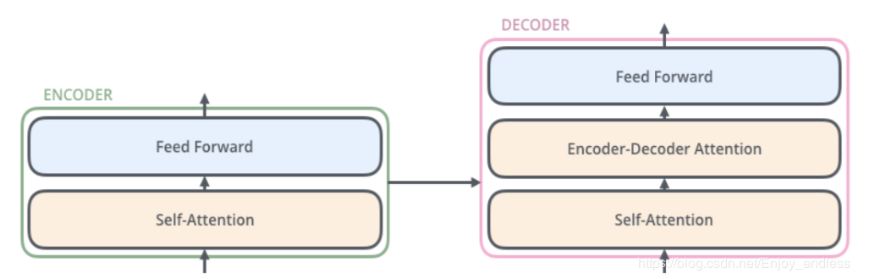
transformer由2个部分组成,一个Encoders和一个Decoders。每个Encoders中分别由6个Encoder组成,而每个Decoders中同样也是由6个Decoder组成。对于Encoders中的每一个Encoder,他们结构都是相同的,但是并不会共享权值。每层Encoder有2个部分组成:
每个Encoder的输入首先会通过一个self-attention层,通过self-attention层帮助Endcoder在编码单词的过程中查看输入序列中的其他单词。
Self-attention的输出会被传入一个全连接的前馈神经网络,每个encoder的前馈神经网络参数个数都是相同的,但是他们的作用是独立的。
每个Decoder也同样具有这样的层级结构,但是在这之间有一个Attention层,帮助Decoder专注于与输入句子中对应的那个单词。
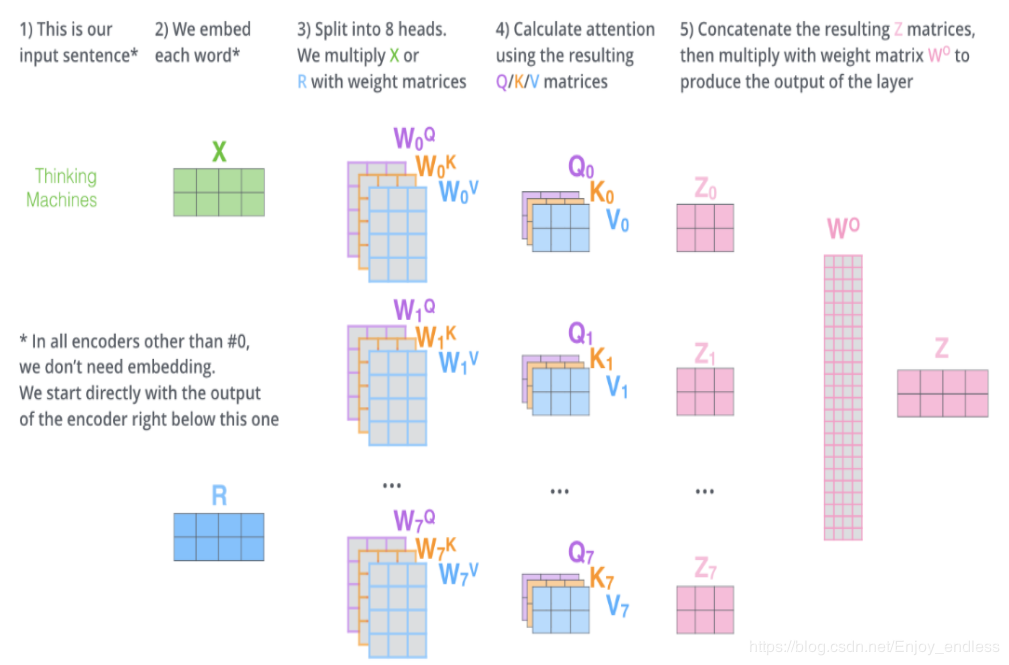
1.2 self attention计算与 Multi-headed
- 将输入进行embedding后变成X|R,将X|R乘以W^{Q}的权重矩阵得到新向量q1,q1既是“query”的向量。同理,最终我们可以对输入句子的每个单词创建“query”,“key”,“value”的新向量表示形式。通过将query向量和key向量做点积来对相应的单词打分。以矩阵的形式即是Q与K相乘。将得分除以8*sqrt{dk},(论文中使用key向量的维度是64维,其平方根=8,这样可以使得训练过程中具有更稳定的梯度。这个sqrt{dk}并不是唯一值,经验所得)。然后再将得到的输出通过softmax函数标准化,使得最后的列表和为1。这个softmax的分数决定了当前单词在每个句子中每个单词位置的表示程度。将每个Value向量乘以softmax后的得分。这里实际上的意义在于保存对当前词的关注度不变的情况下,降低对不相关词的关注。最后是累加加权值的向量。 这会在此位置产生self-attention层的输出Z(对于第一个单词)。
- 通过multi-headed attention,我们为每个“header”都独立维护一套Q/K/V的权值矩阵。还是如之前单词级别的计算过程一样处理这些数据。对上面的例子做同样的self attention计算,因为我们有8头attention,所以会在八个时间点去计算这些不同的权值矩阵,但最后结束时,我们会得到8个不同的Z矩阵。在self-attention后面紧跟着的是前馈神经网络,而前馈神经网络接受的是单个矩阵向量,而不是8个矩阵。所以我们将这8个矩阵连接在一起然后再与一个矩阵W0相乘。得到最后的Z。
1.3 添加位置编码
对于输入序列中单词顺序的考虑还是很有必要的,于是我们可以引入位置编码向量;transformer为每个输入单词的词嵌入上添加了一个新向量-位置向量。
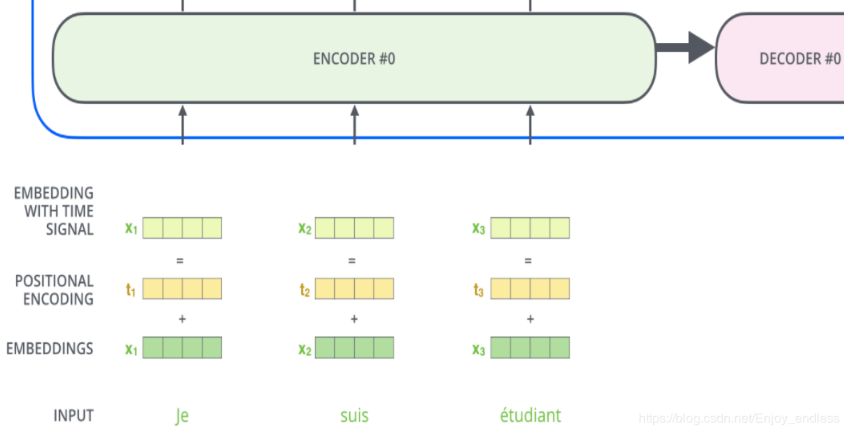
将这些信息也添加到词嵌入中,然后与Q/K/V向量点击,获得的attention就有了距离的信息了。位置编码向量不需要训练,它有一个规则的产生方式。
1.4 接下来 我们看看decode
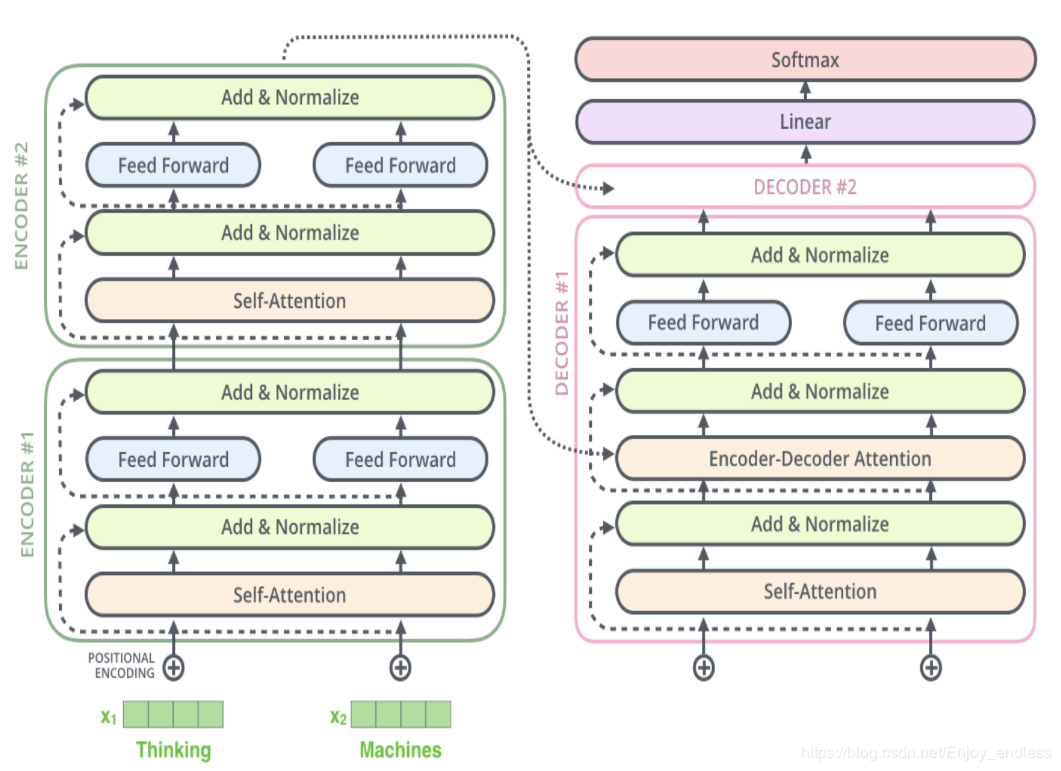
当序列输入时,Encoder开始工作,最后在其顶层的Encoder输出矢量组成的列表,然后我们将其转化为一组attention的集合(K,V)。(K,V)将带入每个Decoder的“encoder-decoder attention”层中去计算。对于decoder的输入不仅仅包含encoder的输出,同时还包含先前的decoder输出。
1.5 decode中的 Linear和softmax层
Decoder的输出是浮点数的向量列表。我们是如何将其变成一个单词的呢?这就是最终的线性层和softmax层所做的工作。
线性层是一个简单的全连接神经网络,它是由Decoder堆栈产生的向量投影到一个更大的向量中,称为对数向量;
在线性层之后是一个softmax层,softmax将这些分数转换为概率。选取概率最高的索引,然后通过这个索引找到对应的单词作为输出。
这篇文章将的还是比较清楚的,推荐看看:https://zhuanlan.zhihu.com/p/98650532
参考出处:https://blog.csdn.net/Enjoy_endless/article/details/88344750
2.Bert与其他预训练语言模型的词表示
这里是目前的研究现状:https://zhuanlan.zhihu.com/p/126312939
这里是基于bert的python实战:https://www.pythonheidong.com/blog/article/327120/
还有两篇,尽快使用bert的详尽的示例文章:
1.https://www.jianshu.com/p/013a92bfd19e
2.https://www.jianshu.com/p/1e28a8dd3b10