Hive部分函数解析
Hive里的exists ,in ,not exists ,not in 相关函数
表数据准备:
1.选择指定数据库 eg: use bg_database1;
2. 创建表
drop table demo0919 ; create table demo0919( name string ,age int ,sex int ) row format delimited fields terminated by '�01';
3.插入表数据
insert overwrite table demo0919 values('zs',18,1);
insert into table demo0919 values('ls',18,1);
insert into table demo0919 values('nisa',19,0);
insert into table demo0919 values('rina',22,0);
insert into table demo0919 values('zhaoxi',25,1);
4. 根据原表 demo0919 再创建一张表 demo0919_1,用于比对数据。
create table demo0919_1 as select *from demo0919;
5.查看表数据
select *from demo0919;
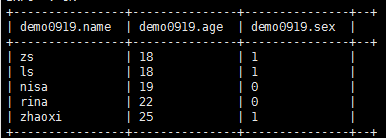
函数测试
in:
in的简单使用(ok,支持):
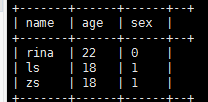
select name,age,sex from demo0919 where age in (18,22);
in 里面嵌套子查询 (error ,不支持)
select name,age,sex from demo0919 where age in (select a.age from demo0919_1 a );

not in :
not in 的简单使用(ok, 支持)
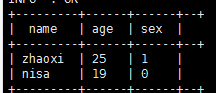
select name,age,sex from demo0919 where age not in (18,22);
not in 里面嵌套子查询 (error ,不支持)
select name,age,sex from demo0919 where age not in (select a.age from demo0919_1 a);

exists:
exists 基本使用(ok)
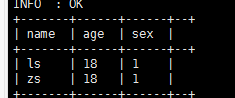
select name,age,sex from demo0919 where exists (select 1 from demo0919_1 a where a.age=18 and demo0919.name = a.name);
exists子查询里面使用了 外表demo0919中的字段 不等于(> , < , >= , <= , <>) 子查询表中的字段(error 不支持)
select name,age,sex from demo0919 where exists (select 1 from demo0919_1 a where a.age>demo0919.age and demo0919.name = a.name);

处理方案:
根据此段我们可以借助left outer join,left semi join 来实现类似功能 前者允许右表的字段在select或where子句中引用,而后者不允许。
(left semi join :需要注意 使用left semi join时 右侧的表不能被使用,只能在on后面作为条件筛选)
select d.name,d.age,d.sex from demo0919 d left outer join demo0919_1 a on d.name = a.name where a.age>d.age;
exists子查询里面未使用 外表demo0919中的字段 不等于(> , < , >= , <= , <>) 子查询表中的字段(ok 支持)
select name,age,sex from demo0919 where exists (select 1 from demo0919_1 a where a.age>18 and demo0919.name = a.name);
not exists 与 exist雷同。
Hive数据类型转换函数:
daycount string; daycount表示耗时数据信息,原来定义为string类型
cast(daycount AS FLOAT) 将string类型数据转换为FLOAT类型
Hive日期类型转换函数:
unix_timestamp(countdate) :将日期转换为时间戳, countdate为日期字段
from_unixtime(unix_timestamp(countdate),'yyyy-MM-dd HH:mm:ss') :格式化当前时间
Hive的group by :(这里是因为我们在使用group by时用到了带时分秒的日期字段,hive精确到了毫秒级别,mysql中精确到秒,带有日期字段的数据一起dsitinct 或 group by的时候 数据就会有差异)
因为hive保留了 毫秒位数据,故结果数据会比mysql多
例如: 2019-09-19 12:12:12.1 2019-09-19 12:12:12.2
在hive里面 distinct后这是两个不同的日期 2019-09-19 12:12:12.1 2019-09-19 12:12:12.2
在mysql里面 distinct后 这就是相同的日期了 2019-09-19 12:12:12