总评一句:Dinic算法的基本思想比较好理解,就是它的当前弧优化的思想,网上的资料也不多,所以对于当前弧的优化,我还是费了很大的功夫的,现在也一知半解,索性就写一篇博客,来发现自己哪里的算法思想还没理解透彻,并解决他
https://www.cnblogs.com/SYCstudio/p/7260613.html
这篇博客对于Dinic的算法思想介绍的非常详细,一些专有名词什么的也是很专业
网络流:在一个有向图上选择一个源点,一个汇点,每一条边上都有一个流量上限(以下称为容量),即经过这条边的流量不能超过这个上界,同时,除源点和汇点外,所有点的入流和出流都相等,而源点只有流出的流,汇点只有汇入的流。这样的图叫做网络流。
就相当于生活中的排水或管道运输,我一次性运输的绝对不能超过任何一节管道的限流大小,所以一次性的,所有店的入流和出流都相等
我们定义:
源点:只有流出去的点
汇点:只有流进来的点
流量:一条边上流过的流量
容量:一条边上可供流过的最大流量
残量:一条边上的容量-流量
残量也就是一个边上再不超过限制的情况下还能流的大小,生活中也是如此,1 - 2边限制为5,2 - 3边限制为4管道相连的方向我可以从1 - 2 - 3 流量为 4,我还可以1 - 2 - 4 流量为1,所以这个并不是一个边只能用一次。每次用完我们可能会记录参量,并进行其他的相关操作
最大流的求解:
网络流的所有算法都是基于一种增广路的思想,下面首先简要的说一下增广路思想,其基本步骤如下:
1.找到一条从源点到汇点的路径,使得路径上任意一条边的残量>0(注意是小于而不是小于等于,这意味着这条边还可以分配流量),这条路径便称为增广路 2.找到这条路径上最小的F[u][v](我们设F[u][v]表示u->v这条边上的残量即剩余流量),下面记为flow 3.将这条路径上的每一条有向边u->v的残量减去flow,同时对于起反向边v->u的残量加上flow(为什么呢?我们下面再讲) 4.重复上述过程,直到找不出增广路,此时我们就找到了最大流
这个算法是基于增广路定理(Augmenting Path Theorem): 网络达到最大流当且仅当残留网络中没有增广路(由于笔者知识水平不高,暂且不会证明)
举个例子:
为什么要连反向边
我们知道,当我们在寻找增广路的时候,在前面找出的不一定是最优解,如果我们在减去残量网络中正向边的同时将相对应的反向边加上对应的值,我们就相当于可以反悔从这条边流过。 比如说我们现在选择从u流向v一些流量,但是我们后面发现,如果有另外的流量从p流向v,而原来u流过来的流量可以从u->q流走,这样就可以增加总流量,其效果就相当于p->v->u->q,用图表示就是:
图中的蓝色边就是我们首次增广时选择的流量方案,而实际上如果是橘色边的话情况会更优,那么我们可以在v->u之间连一条边容量为u->v减去的容量,那我们在增广p->v->u->q的时候就相当于走了v->u这条"边",而u->v的流量就与v->u的流量相抵消,就成了中间那幅图的样子了。 如果是v->u时的流量不能完全抵消u->v的,那就说明u还可以流一部分流量到v,再从v流出,这样也是允许的。
一个小技巧
虽然说我们已经想明白了为什么要加反向边,但反向边如何具体实现呢?笔者在学习网络流的时候在这里困扰了好久,现在简要的总结在这里。 首先讲一下邻接矩阵的做法,对于G[u][v],如果我们要对其反向边进行处理,直接修改G[v][u]即可。 但有时会出现u->v和v->u同时本来就有边的情况,一种方法是加入一个新点p,使u->v,而v->u变成v->p,p->u。 另一种方法就是使用邻接表,我们把边从0开始编号,每加入一条原图中的边u->v时,加入边v->u流量设为0,那么这时对于编号为i的边u->v,我们就可以知道i^1就是其反向边v->u。
朴素算法的低效之处
虽然说我们已经知道了增广路的实现,但是单纯地这样选择可能会陷入不好的境地,比如说这个经典的例子:
我们一眼可以看出最大流是999(s->v->t)+999(s->u->t),但如果程序采取了不恰当的增广策略:s->v->u->t
我们发现中间会加一条u->v的边
而下一次增广时:
若选择了s->u->v->t
然后就变成
这是个非常低效的过程,并且当图中的999变成更大的数时,这个劣势还会更加明显。 怎么办呢? 这时我们引入Dinic算法
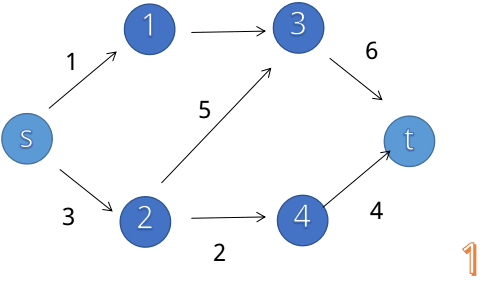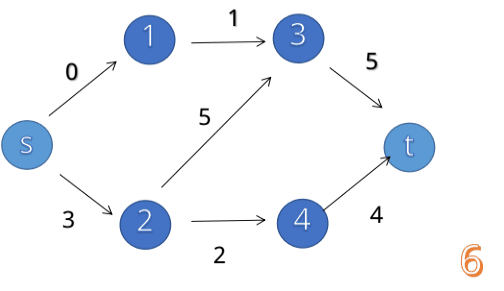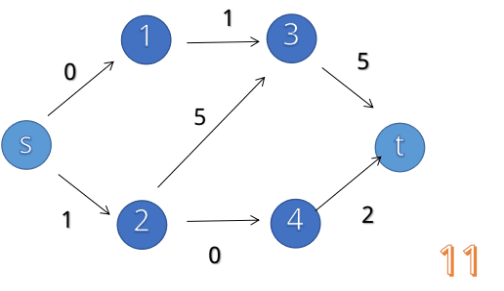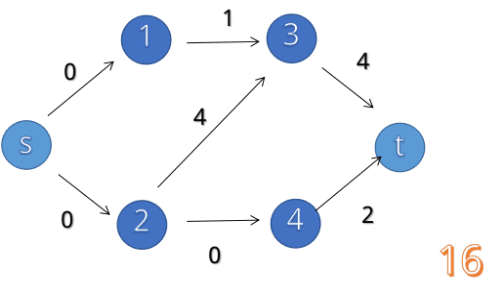
最大流的求法:就是求1 - n的最大总流量(给你已知地图)
Dinic算法是比较高效的解决算法
为了解决我们上面遇到的低效方法,Dinic算法引入了一个叫做分层图的概念。具体就是对于每一个点,我们根据从源点开始的bfs序列,为每一个点分配一个深度,然后我们进行若干遍dfs寻找增广路,每一次由u推出v必须保证v的深度必须是u的深度+1。下面给出代码
一些变量的定义
以下给出的代码,是按我的方式写出并解释的,大家如果想先看看大佬的,那就click here!
#include <iostream>
#include <string.h>
#include <queue>
#include <cstdio>
#define inf 0x3f3f3f3f
using namespace std;
const int maxn = 220;
const int maxm = 4e4 + 4e3;
int m,n;
struct node
{
int pre;
int to,cost;
}edge[maxm];
int id[maxn],cnt;
int flor[maxn];
void init()
{
memset(id,-1,sizeof(id));
cnt = 0;
}
int cur[maxn];
void add(int a,int b,int x)
{
edge[cnt].to = b;
edge[cnt].cost = x;
edge[cnt].pre = id[a];
id[a] = cnt++;
swap(a,b);
edge[cnt].to = b;
edge[cnt].cost = 0;
edge[cnt].pre = id[a];
id[a] = cnt++;
}
这一部分代码比较基础,也没什么算法在里面,第一个就是链式前向星存储边的关系,flor是为了Dinic算法存储结点的层号,cur数组时当前弧的优化,这个我们稍后再谈谈,add时加边炒作,用到了一个反向边的思想,为什么要有反向边上面大佬说的也比较清楚了,我前面ek算法的学习记录也有我自己的理解在里面~~在这就不提了。还要注意的一点就是这样的加边方法,对于正向边edge[i]那么edge[i^1]就是反向边的数据,很是方便,后面会用
在这我直接来想一想带有当前弧优化的Dinic算法
int Dinic(int s,int t)
{
int ret = 0;
while(bfs(s,t))
{
for(int i = 1;i <= n;i++)
{
cur[i] = id[i];
}
ret += dfs(s,t,inf);
}
return ret;
}
大体架构是这样的,先利用bfs为当前图层分层,分完层之后,是当前弧优化的初始化操作,我看见过很多版本,没有一一深究,先理解学习的这一个你可以看到,id数组是链式前向星的每一个点边数据的链尾点,很明显,当前弧的优化肯能要对我存储的边来做做手脚了
然后我对当前分好层的 图进行dfs寻找可行路径,并返回最大流量
先来看看bfs分层,这个还比较中规中矩
int bfs(int s,int t)
{
queue<int>q;
while(q.size())q.pop();
memset(flor,0,sizeof(flor));
flor[s] = 1;
q.push(s);
while(q.size())
{
int now = q.front();q.pop();
if(now == t)return 1;
for(int i = id[now];~i;i = edge[i].pre)
{
int to = edge[i].to;
if(flor[to] == 0 && edge[i].cost > 0)
{
flor[to] = flor[now] + 1;
q.push(to);
//找到一条边就返回
if(to == t)return 1;
}
}
}
return flor[t] != 0;
// return 0;
}
继续bfs寻找的条件是没有被拜访过(flor数组还起到了vis数组的作用,并且该店还有流量,还能走),到了就返回1没到其实返回0就行了
我在1532的样例中过了,我也没觉得有啥问题,我一开始初始化肯定是flor[t] = 0,我只有访问过t才能对flor【t】进行赋值,一旦赋值不久代表to == t 肯定就返回1了,没毛病~~
接下来就是重头戏dfs,本来dfs就是递归,再加上当前弧优化也在这,一团浆糊扔过来我也就只剩浆糊了,但是,但是,我也得弄啊~~
int dfs(int s,int t,int value)
{
int ret = value,a;
if(s == t || value == 0)return value;
//当前弧优化
for(int &i = cur[s];~i;i = edge[i].pre)//每次dfs的时候记录遍历优化到那条边了,如果再次遍历这个点的时候就可以直接取拜访那条边
{
int to = edge[i].to;
if(flor[to] == flor[s] + 1 && (a = dfs(to,t,min(ret,edge[i].cost))))
{
edge[i].cost -= a;
edge[i^1].cost += a;
ret -= a;
if(!ret)break;
}
}
if(ret == value)flor[s] = 0;
return value - ret;
/*for(int i = id[s];~i;i = edge[i].pre)
{
int to = edge[i].to;
int cost = edge[i].cost;
if(flor[s] == flor[to] - 1 && cost > 0 && (int w = dfs(to,t,min(value - ret,cost))))//不加上括号不能识别,会报错
{
edge[i].cost -= w;
edge[i^1].cost += w;
ret += w;
// return ret;
if(ret == value)break;
}
}
if(!ret) d[s] = -1;
return ret;
return 0;*/
}
注释得是本来没有当前弧优化得代码
s是起点,t是终点,value是当前得流量
ret存储value副本,a用来接收递归返回的值,递归结束得条件:到达了终点,或者当前得流量已经为0就直接返回就好——就是1.路通了到了2.路不通没路了,在这两个情况下返回值
接下来我们用到了当前弧得优化,引用cur数组,作用是i变化,cur也变化,就相当与,这个点变关系每一条边在这次所有的dfs中只会出现一次,
当你判断to那个点可行得化,那就dfs递归求区to 到 终点t得value,这样我们会一直递归到t,返回了value,表示这一条通路上的最大流量,由a接着,并回溯对a那条边进行正反边得优化,正向边减限制,反向边增加限制,ret为什么是-a呢
先来看看ret表示得是由起始点s 到当前点to得value,w是加上了(连上了,dfs连上得)终点后的value,有一点1他俩相等,这很好我们就可以直接返回了,最后就是直接返回value去进行后续得边得优化
2.他俩不相等呢(ret > a),就不会退出,会根据to得边的记录继续dfs,这样应该就不会dfs到终点了,但是为什么还要继续dfs就是为了当前弧度得优化,它的记录会让我dfs不会再走一遍,扫完之后还得出来不是,出来后ret表示得就是两个value得差值,就是相当于把w带了出来value - ret = a
if(ret == value)flor[s] = 0;这一个是干什么得呢:也是一个优化,你得看看ret何时 == value
两种可能把;1.到了终点t但是最大流量是0,那么我这个中间点s是不是就废了,已经断流了啊,标记以下,下次dfs不再管它
2.没到终点,走了这么久都没到终点,这个中间的s是不是也废了,下次我也不再走它~~
其实这里还是比较好懂得,对于我,我觉得int &i = cur[s];~i;i = edge[i].pre这个是最难懂的了,想了很久,在这里和大家交流一下,这里得目的都很明确,加上这一条就是表示这一条边我只来一次,可是我就提出反例了
生活中也是如此,1 - 2边限制为5,2 - 3边限制为4管道相连的方向我可以从1 - 2 - 3 流量为 4,我还可以1 - 2 - 4 流量为1,所以这个并不是一个边只能用一次
我上面刚刚说过一个边可能用多次,正好不久和这个冲突了吗,我就想,是不是回溯得时候他做了手脚了,唉,还真有手脚,就是ret,他执行完ret - a得操作后,表示得是什么:(我有点激动,我好像写着写着明白了,我要把我脑子里的图画出来)
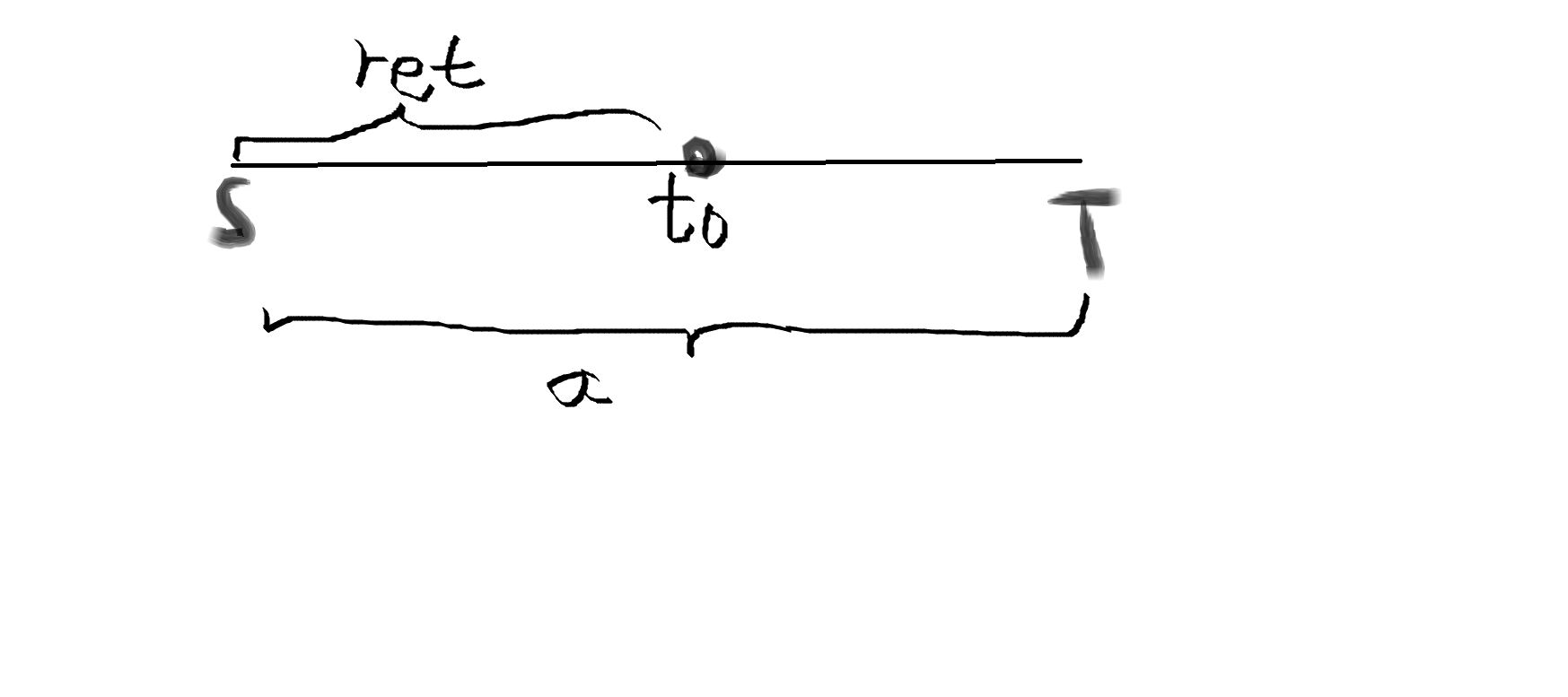
ret表示得是从s到to得最大流量,a呢是目前这个路程得最大流量(ret >= a)注意:T不一定非得是终点,这也就保证了,每一步得回溯使得结果无误
ret - a就是s 到 to点所有点都至少剩余得流量,这就回溯回来了,我们就可以用这个ret继续寻找to得另外得边,看看还有没有别的可行得路
又是两种情况:1.另一条边可行,ret被优化到了0,我们久break,返回值,没什么毛病
2.没有可行边,当前弧继续优化并进行回溯,往回走
我又有了一个问题,就是如果可行了,返回了ret是零,奥,那么对于我前面所有得边得正向边至少都会-value,因为我是一步一步对边进行回溯更新得,这里得操作都市对当前边得优化,对于后续边,如果限制流量满了,那么我就返回value让他取优化,而不必去管他是流了几次才满得,没有满呢,我就会先去尝试还能不能流向别处,如果不行我会先记录该点位费点,然后返回他俩之间得差值,因为我尽力了,他还是没能流满,如果能流向别处,好像又是一波循环了,到此我觉得我算是明白这个算法了,我感觉可以自己想着写一下了
————————————————————————————————————————————————
加油!Butterflier