粘贴复制于:https://blog.csdn.net/lzwglory/article/details/79978788
集合是编程中最常用的数据结构。而谈到并发,几乎总是离不开集合这类高级数据结构的支持。比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap)。这篇文章主要分析jdk1.5的3种并发集合类型(concurrent,copyonright,queue)中的ConcurrentHashMap,让我们从原理上细致的了解它们,能够让我们在深度项目开发中获益非浅。
V get(Object key, int hash) { if (count != 0) { // read-volatile HashEntry e = getFirst(hash); while (e != null) { if (e.hash == hash && key.equals(e.key)) { V v = e.value; if (v != null) return v; return readValueUnderLock(e); // recheck } e = e.next; } } return null; } V readValueUnderLock(HashEntry e) { lock(); try { turn e.value; } finally { unlock(); } }
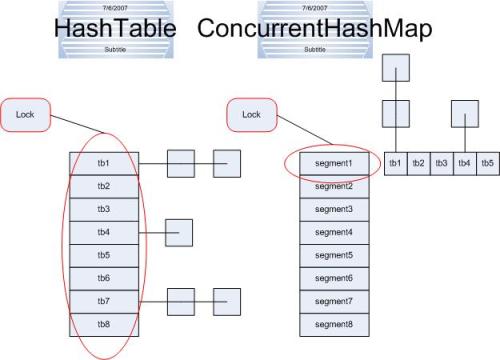
put操作一上来就锁定了整个segment,这当然是为了并发的安全,修改数据是不能并发进行的,必须得有个判断是否超限的语句以确保容量不足时能够rehash,而比较难懂的是这句int index = hash & (tab.length - 1),原来segment里面才是真正的hashtable,即每个segment是一个传统意义上的hashtable,如上图,从两者的结构就可以看出区别,这里就是找出需要的entry在table的哪一个位置,之后得到的entry就是这个链的第一个节点,如果e!=null,说明找到了,这是就要替换节点的值(onlyIfAbsent == false),否则,我们需要new一个entry,它的后继是first,而让tab[index]指向它,什么意思呢?实际上就是将这个新entry插入到链头,剩下的就非常容易理解了。
V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); try { int c = count; if (c++ > threshold) // ensure capacity rehash(); HashEntry[] tab = table; int index = hash & (tab.length - 1); HashEntry first = (HashEntry) tab[index]; HashEntry e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue; if (e != null) { oldValue = e.value; if (!onlyIfAbsent) e.value = value; } else { oldValue = null; ++modCount; tab[index] = new HashEntry(key, hash, first, value); count = c; // write-volatile } return oldValue; } finally { unlock(); } }
remove操作非常类似put,但要注意一点区别,中间那个for循环是做什么用的呢?(*号标记)从代码来看,就是将定位之后的所有entry克隆并拼回前面去,但有必要吗?每次删除一个元素就要将那之前的元素克隆一遍?这点其实是由entry的不变性来决定的,仔细观察entry定义,发现除了value,其他所有属性都是用final来修饰的,这意味着在第一次设置了next域之后便不能再改变它,取而代之的是将它之前的节点全都克隆一次。至于entry为什么要设置为不变性,这跟不变性的访问不需要同步从而节省时间有关,关于不变性的更多内容,请参阅之前的文章《线程高级---线程的一些编程技巧》
V remove(Object key, int hash, Object value) { lock(); try { int c = count - 1; HashEntry[] tab = table; int index = hash & (tab.length - 1); HashEntry first = (HashEntry)tab[index]; HashEntry e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue = null; if (e != null) { V v = e.value; if (value == null || value.equals(v)) { oldValue = v; // All entries following removed node can stay // in list, but all preceding ones need to be // cloned. ++modCount; HashEntry newFirst = e.next; for (HashEntry p = first; p != e; p = p.next) newFirst = new HashEntry(p.key, p.hash, newFirst, p.value); tab[index] = newFirst; count = c; // write-volatile } } return oldValue; } finally { unlock(); } } static final class HashEntry { final K key; final int hash; volatile V value; final HashEntry next; HashEntry(K key, int hash, HashEntry next, V value) { this.key = key; this.hash = hash; this.next = next; this.value = value; } }
以上,分析了几个最简单的操作,限于篇幅,这里不再对rehash或iterator等实现进行讨论,有兴趣可以参考src。