import pandas as pd
from matplotlib import pyplot as plt
csv_file_name = "C:\Users\dgd71\Desktop\datas.csv"
def you_want_matrix(start,end,begin,stop): #自定义一个获取CSV矩阵的函数
matrix = df_my_data.iloc[start:end,begin:stop]
print(matrix)
def scatter_diagram(line,row,color,marker): #自定义一个画散点图的函数
x = df_my_data[line] # pandas DataFrame 中的取列的方法
y = df_my_data[row] # pandas DataFrame 中的取列的方法
plt.xlabel("Name") #给x轴命名
plt.ylabel("StudyGarde") #y轴命名
plt.title("StudyTestPicture") #给散点图命名
plt.xlim([0, 100]) #x轴长度
plt.ylim([0, 100])
plt.xticks(range(0, 101, 5)) #x轴划分刻度
plt.scatter(x, y, c=color, marker=marker, linewidths=1) #散点图函数的运用
plt.show()
def cake_picture (row): #自定义一个画饼图的函数
a = []
b = []
c = []
d = []
test_data = df_my_data[row]
datas = list(test_data)
for i in range(len(datas)):
if datas[i] >= 90:
a.append(datas[i])
elif datas[i] >= 85:
b.append(datas[i])
elif datas[i] >= 80:
c.append(datas[i])
else:
d.append(datas[i])
my_datas = [len(a) / len(datas), len(b) / len(datas), len(c) / len(datas), len(d) / len(datas)]
#通过列表长度来计算百分比
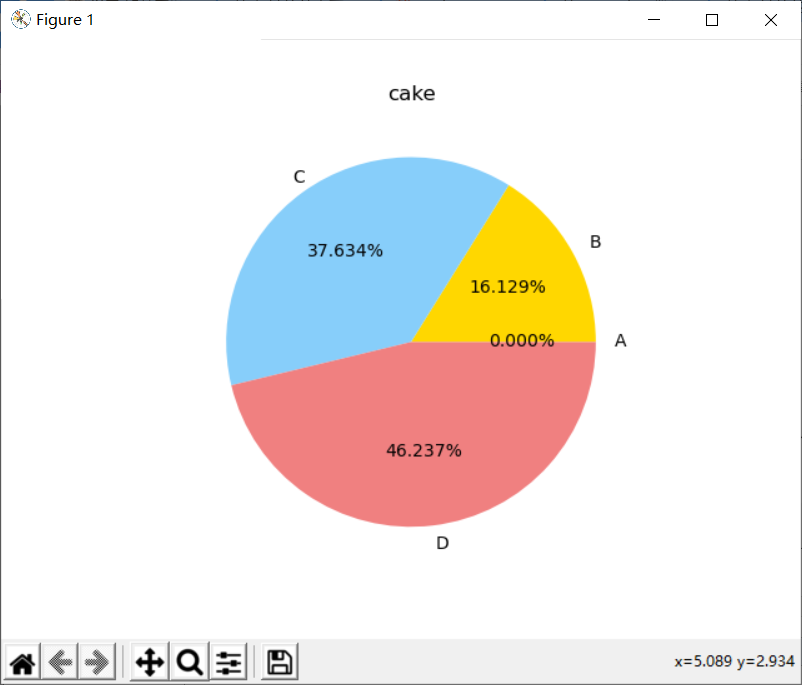
labels = ["A", "B", "C", "D"] #标签
colors = ['yellowgreen','gold','lightskyblue','lightcoral'] #每个标签所对应的颜色
plt.axes(aspect='equal') #将横、纵坐标轴标准化处理,保证饼图是一个正圆,否则为椭圆
plt.xlim(0, 8)
plt.ylim(0, 8)
plt.pie(x=my_datas, labels=labels, colors=colors, autopct='%.3f%%', center=(4, 4), radius=1)
plt.xticks(()) #不显示X轴、Y轴的刻度值
plt.yticks(())
plt.title('cake')
plt.show()
def hist(line): #自定义直方图函数
x_data = df_my_data[line]
plt.hist(x=x_data,bins=10)
plt.show()
if __name__== "__main__": #代码更高效的运转
try:
my_data = pd.read_csv(csv_file_name,encoding="gbk") #read csv data
df_my_data = pd.DataFrame(data=my_data) # 把data装入DataFrame数据框架中操作
scatter_diagram("姓名","智育成绩","blue",".")
scatter_diagram("姓名","基础素质","red","*")
cake_picture("智育成绩")
hist("智育成绩")
except FileNotFoundError:
print("文件打开错误!")