自编码器是一种无监督的神经网络模型,其核心的作用是能够学习到输入数据的深层表示。
当前自编码器的主要应用有两个方面:一是特征提取;另一个是非线性降维,用于高维数据的可视化,与流行学习关系密切。
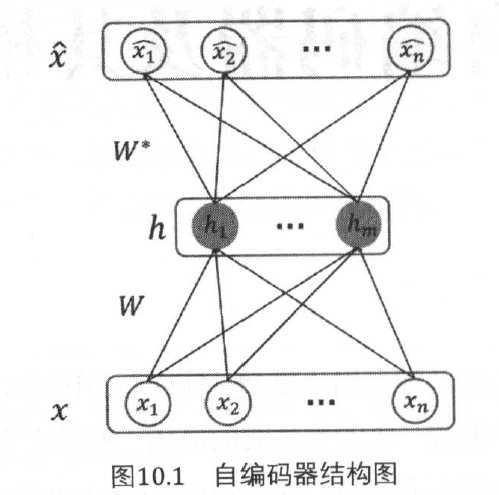
自编码器(AutoEncoder,AE):最原始的AE网络是一个三层的前馈神经网络结构,由输入层、隐藏层和输出层构成。
对于二值神经网络,也就是输入层的每个神经元只能取值0或1,那么损失函数通常由交叉熵来定义;
对于输入神经元是一个任意实数,则通常采用均方误差来定义损失函数。
自编码器的核心设计是隐藏层,隐藏层的设计有两种方式:
1. 当隐藏层神经元个数小于输入层神经元个数时,称为undercomplete。该隐藏层设计使得输入层到隐藏层的变化本质上是一种降维的操作,网络试图以更小的维度去描述原始数据而尽量不损失数据信息,从而得到输入层的压缩表示。当隐藏层的激活函数采用线性函数时,自编码器也称为线性自编码器,其效果等价于主成分分析。
2. 当隐藏层神经元个数大于输入层神经元个数时,称为overcomplete。该隐藏层设计一般用于稀疏编码器,可以获得稀疏的特征表示,也就是隐藏层中有大量的神经元取值为0。
自编码器的相关模型:
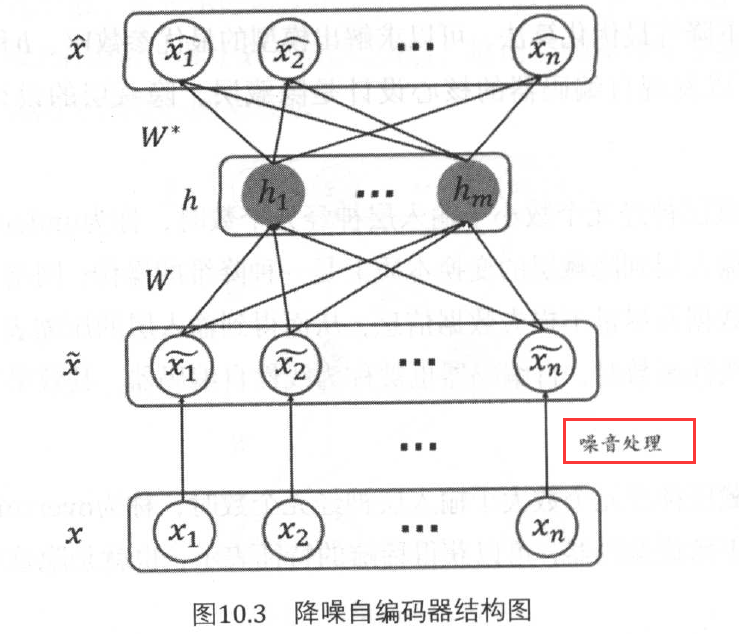
1. 降噪自编码器(Denoising Autoencoders,DAE):其目的是增强自编码器的鲁棒性。自编码器的目标是期望重构后的结果输出与输入数据相同,也就是能够学习到输入层的正确数据分布。但当输入层数据受到噪音的影响时,可能会使得获得的输入数据本身就不服从原始的分布。在这种情况下,利用自编码器得到的结果也将是不正确的,为了解决这种由于噪音产生的数据偏差问题,提出DAE网络结构。
2. 栈式自编码器(Stacked Autoencoders,SAE):也称为堆栈自编码器、堆叠自编码器等。就是将多个自编码器进行叠加。利用上一层的隐藏层便是作为下一层的输入,得到更抽象的表示。

SAE的一个很重要的应用是通过逐层预训练来初始化网络权重参数,从而提升深层网络的收敛速度和减缓梯度消失的影响。
SAE通过下面两个阶段作用于整个网络。
阶段1:逐层预训练:是指用过自编码器来训练每一层的参数,作为神经网络的初始化参数。利用逐层预训练的方法,首先构建多个自编码器,每一个自编码器对应于一个隐藏层。从左到右逐层训练每一个自编码器,用训练后的最优参数作为神经网络的初始化参数。如果考虑到模型的鲁棒性,防止数据受噪音的影响,可以将AE变位DAE,这样由多个DAE叠加的栈式自编码器,也称为栈式降噪自编码器。
阶段2:微调:经过第一步的逐层预训练后,得到了网络权重参数更加合理的初始化估算,就可以像训练普通的深层网络一样,通过输出层的损失函数,利用梯度下降等方法来迭代求解最优参数。
3. 稀疏编码器:由于稀疏编码器能够学习到输入的数据的稀疏特征表示,因此当前被广泛应用于无监督的特征提取学习中。特点:隐藏层向量是稀疏的,尽可能多的零元素。