一 步骤
1、Cope一个模板(collection1),修改目录名称
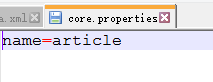
2、修改索引库名称:core.properties
3、配置自定义的业务字段:schema.xml文件
4、如果solr中方法不满足需求时,那么可以去配置。
1.创建cyan索引库:复制collection1 修改名称为cyan
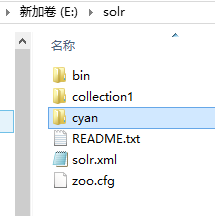
2 修改索引库名称为article
3 修改schema.xml文件
article :字段
- id 不切词 String类型 为主键
- title 切词 text_general类型
- content 切词 text_general类型
- keywords 切词 text_general类型 且允许多值 multiValued="true" (将title 和content 字段拷贝到keywords)
<?xml version="1.0" encoding="UTF-8" ?> <schema name="example" version="1.5"> <field name="_version_" type="long" indexed="true" stored="true"/> <field name="_root_" type="string" indexed="true" stored="false"/> <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="title" type="text_general" indexed="true" stored="true" required="true" multiValued="false" /> <field name="content" type="text_general" indexed="true" stored="true" required="true" multiValued="false" /> <field name="keywords" type="text_general" indexed="true" stored="true" required="true" multiValued="true" /> <uniqueKey>id</uniqueKey> <copyField source="title" dest="keywords"/> <copyField source="content" dest="keywords"/> <fieldType name="string" class="solr.StrField" sortMissingLast="true" /> <fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> </schema>
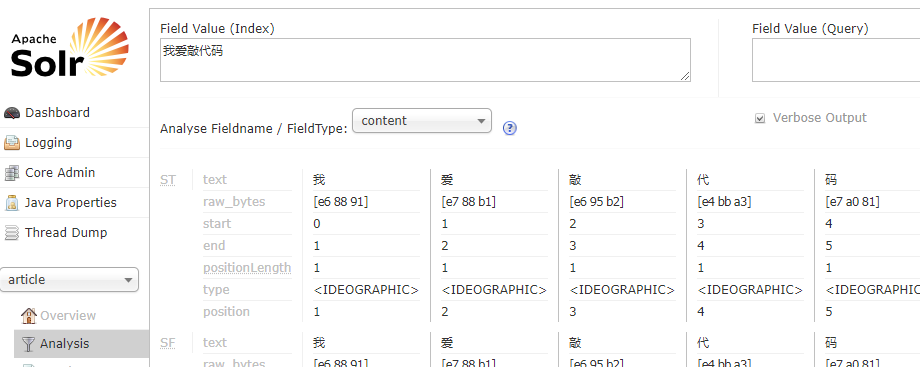
启动tomcat 访问 http://localhost/solr/ 选择索引库article 测试分词, 可以看到把'' 我爱敲代码'' 切分成一个一个的词 . 需要配置第三方中文分词器
二 配置 IK中文分词器
1、导入ik的jar放到solr服务器中;
IKAnalyzer2012FF_u1.jar

2、自定义字段类型: text_ik 修改schema.xml
<?xml version="1.0" encoding="UTF-8" ?> <schema name="example" version="1.5"> <field name="_version_" type="long" indexed="true" stored="true"/> <field name="_root_" type="string" indexed="true" stored="false"/> <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="title" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" /> <field name="content" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" /> <field name="keywords" type="text_ik" indexed="true" stored="true" required="true" multiValued="true" /> <uniqueKey>id</uniqueKey> <copyField source="title" dest="keywords"/> <copyField source="content" dest="keywords"/> <fieldType name="string" class="solr.StrField" sortMissingLast="true" /> <fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="text_ik" class="solr.TextField" > <analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> </schema>
再次开启tomcat 访问 solr
输入"我爱敲代码" 测试
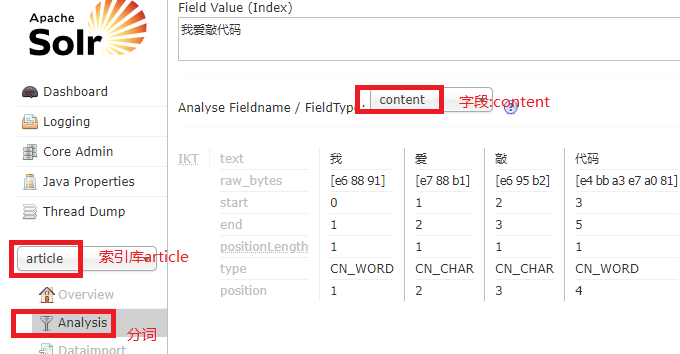
这样就完成了自定义索引库了