目录
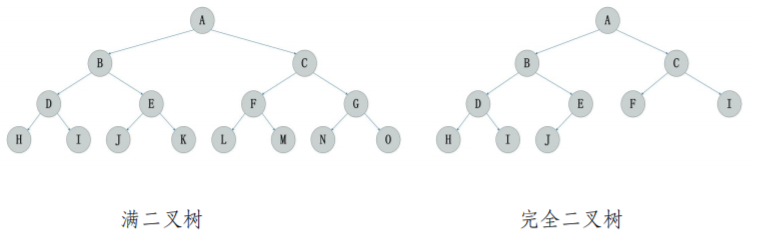
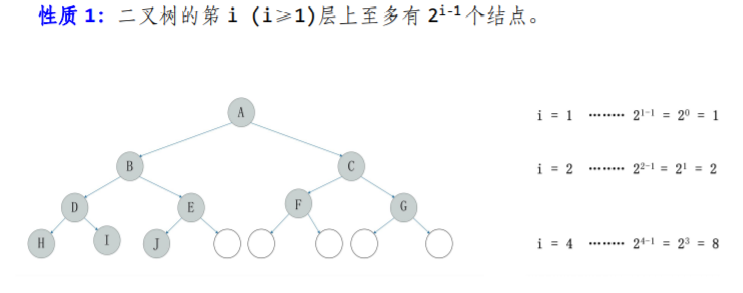
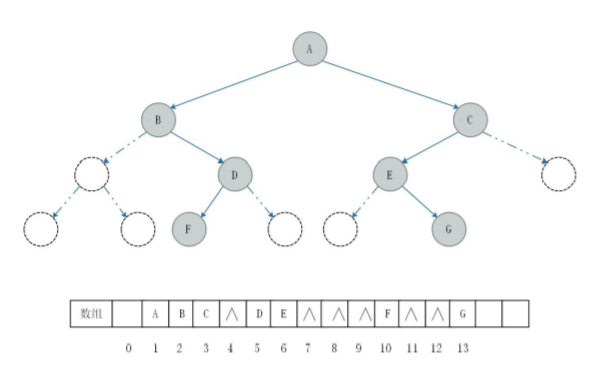
如果一棵树深度为k,有n个结点的二叉树中各节点能与深度为k的顺序编号的满二叉树从1到n标号的节点相对应的二叉树成为完全二叉树,如下图所示


- 线性存储
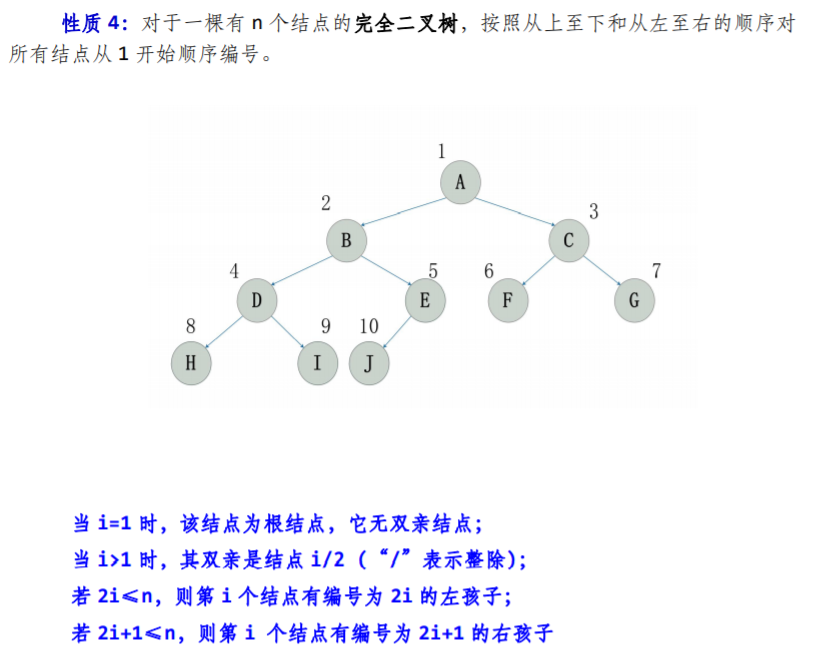
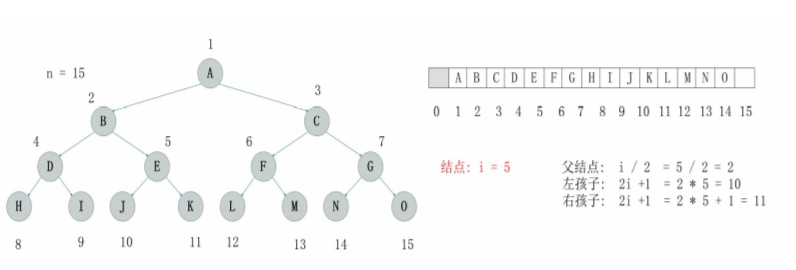
线性存储一般仅用于满二叉树和完全二叉树
-
- 满二叉树的线性存储
-
- 一般二叉树的线性存储
堆是数据结构中的一类,其可以看做是一颗完全二叉树的数组对象。因此,堆必须是完全二叉树,且用数组实现,任一节点是其子树所有节点的最大值或最小值。
最小堆:完全二叉树,每个节点的元素值不大于其他节点的元素值。
最大堆:完全二叉树,每个结点的元素值不小于其子节点的元素值
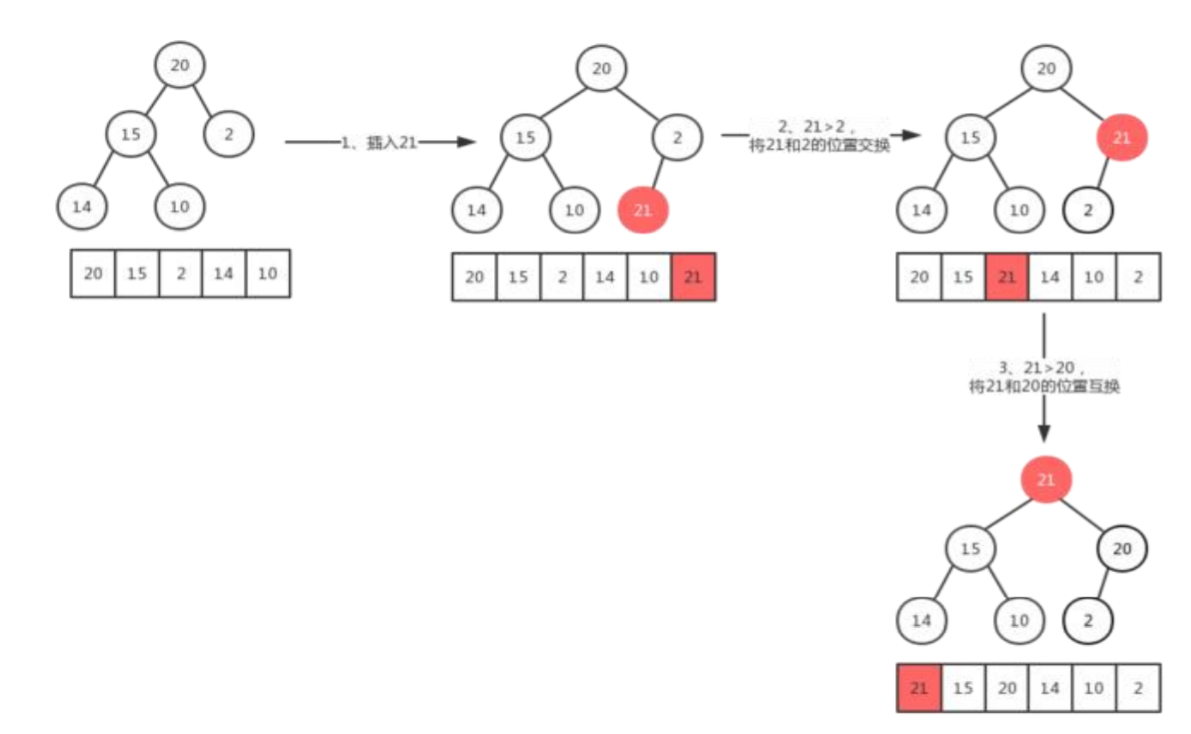
最大堆的插入操作可以简单看成是“结点上浮”。当我们向最大堆中插入一个结点,我们必须满足完全二叉树的标准,那么被插入节点的位置是固定的。而且要满足父节点关键字值不小于子节点关键字值,我们需要移动父节点和子节点的相互位置关系。
最大堆的删除操作,总是从堆的根节点删除元素。同样根元素被删除之后为了能够保证树还是一颗完全二叉树,我们需要移动完全二叉树的最后一个节点,使其继续符合完全二叉树的定义,从这里可以看做是最大堆最后一个节点的下沉。
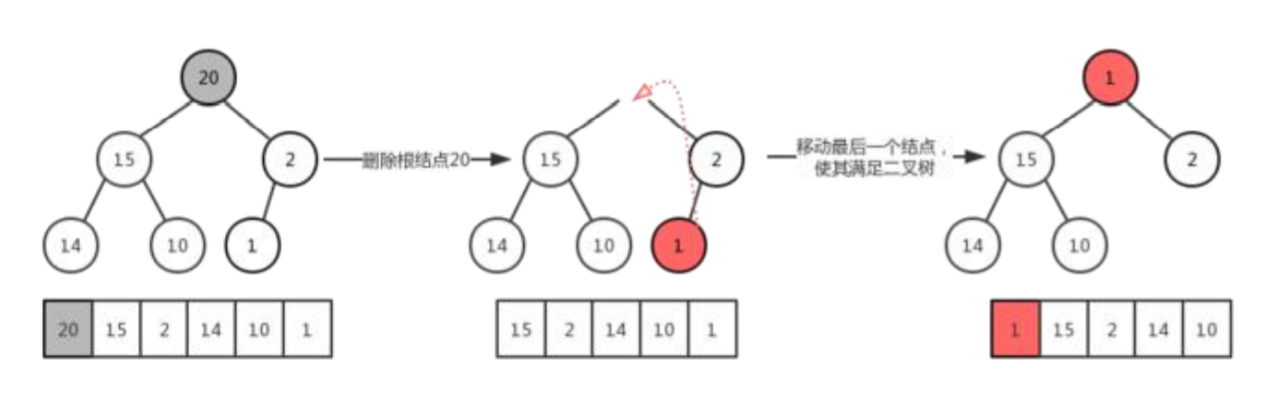
此时是满足完全二叉树的要求,但是仍然不满足根节点是最大值的要求,继续调整如下:
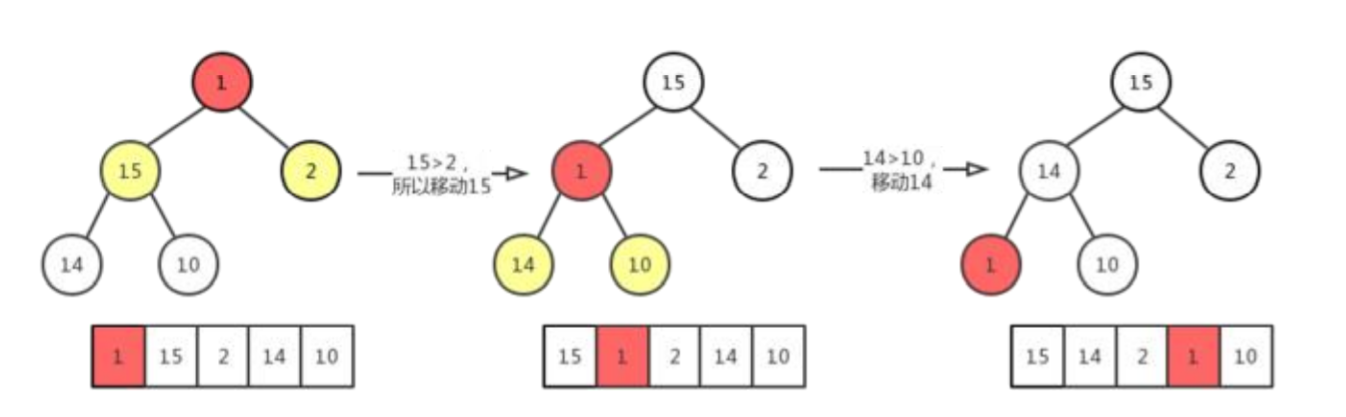
在这里已经确定的最大堆中做删除操作,被删除的元素是固定的,需要被移动的节点也是固定的,这里我说的被移动元素是指最初的移动,即最大堆的最后一个元素,移动方式为从最大的节点开始比较。
我们知道,普通的队列的特点是先进先出。先入队列的元素自然会先出队列。
优先队列将不再遵循先入先出的原则,而是分为两种情况
最大优先队列,无论入队顺序,都是当前最大的元素优先出队列--基于最大堆
最小优先队列,无论入队顺序,都是当前最小的元素优先出队列--基于最小堆
比如有一个最大优先队列,其最大的元素是8,那么虽然元素8不是队首元素,但是出队时仍然让元素8优先出队
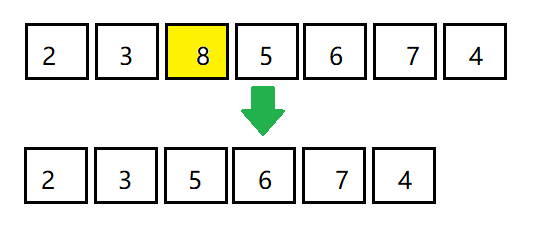
要满足上述需求,利用线性数据结构并非不能实现,但是时间复杂度较高,最坏时间复杂度是O(n)并不是最理想的方式,因此我们使用二叉堆来实现优先队列。
二叉堆的特性
最大堆:堆顶元素是整个堆中最大元素
最小堆:堆顶元素是整个堆中最小元素
入队和出队操作刚刚已经介绍过。
优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出(first in, largest out)的行为特征
priority_queue<Type, Container, Functional>
- type就是数据类型
- Container就是容器类型(Container必须是数组实现的容器,如vector,deque等,但不能用list,STL中默认的是vector)
- Functional就是比较的方式
当需要用自定义的数据类型时才需要传入这三个参数,使用基本数据类型时,只需要传入数据类型,默认是大堆顶
一般是
1 //升序队列,小堆顶 2 priority_queue<int, vector<int>,greater<int> > q; 3 //降序队列,大堆顶 4 priority_queue<int, vector<int>, less<int> > q;
- 基本类型优先队列的例子
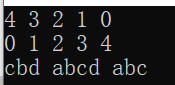
1 #include<iostream> 2 #include <queue> 3 using namespace std; 4 int main() 5 { 6 //对于基础类型 默认是大顶堆 7 priority_queue<int> a; 8 //等同于 priority_queue<int, vector<int>, less<int> > a; 9 10 // 这里一定要有空格,不然成了右移运算符↓↓ 11 priority_queue<int, vector<int>, greater<int> > c; //这样就是小顶堆 12 priority_queue<string> b; 13 14 for (int i = 0; i < 5; i++) 15 { 16 a.push(i); 17 c.push(i); 18 } 19 while (!a.empty()) 20 { 21 cout << a.top() << ' '; 22 a.pop(); 23 } 24 cout << endl; 25 26 while (!c.empty()) 27 { 28 cout << c.top() << ' '; 29 c.pop(); 30 } 31 cout << endl; 32 33 b.push("abc"); 34 b.push("abcd"); 35 b.push("cbd"); 36 while (!b.empty()) 37 { 38 cout << b.top() << ' '; 39 b.pop(); 40 } 41 cout << endl; 42 return 0; 43 }
运行结果如下:
- 用pair做优先队列元素的例子
规则:pair的比较,先比较第一个元素,若第一个相等比较第二个
1 #include <iostream> 2 #include <queue> 3 #include <vector> 4 using namespace std; 5 int main() 6 { 7 priority_queue<pair<int, int> > a; 8 pair<int, int> b(1, 2); 9 pair<int, int> c(1, 3); 10 pair<int, int> d(2, 5); 11 a.push(d); 12 a.push(c); 13 a.push(b); 14 while (!a.empty()) 15 { 16 cout << a.top().first << ' ' << a.top().second << ' '; 17 a.pop(); 18 } 19 }
运行结果

- 问题分析
首先建立一个哈希表,统计非空数组中每个元素出现的次数
建立一个最小堆,最小堆尺寸大于k时,则将堆顶元素出栈
由于最小堆是从小到大,因此要一次输出出现频率前k高的元素,倒序打印
- 代码分析
1 class Solution { 2 public: 3 class mycomparison{ 4 public: 5 bool operator()(const pair<int,int>& fsh,const pair<int,int> &ssh) 6 { 7 return fsh.second>ssh.second; 8 } 9 }; 10 vector<int> topKFrequent(vector<int>& nums, int k) { 11 vector<int> B(k); 12 if(nums.empty()) 13 return B; 14 //首先建立一个哈希表,统计非空数组中每个元素出现的次数 15 unordered_map<int,int> map; 16 for(int i=0;i<nums.size();++i) 17 { 18 map[nums[i]]++; 19 } 20 //建立一个最小堆,最小堆尺寸大于k是则将堆顶元素出栈 21 priority_queue<pair<int,int>,vector<pair<int,int>>,mycomparison> pri_que; 22 for(unordered_map<int,int>::iterator it=map.begin();it!=map.end();++it) 23 { 24 pri_que.push(*it); 25 if(pri_que.size()>k) 26 pri_que.pop(); 27 } 28 //由于最小堆是从小到大,因此要一次输出出现频率前k高的元素,倒序打印 29 for(int i=k-1;i>=0;--i) 30 { 31 B[i]=pri_que.top().first; 32 pri_que.pop(); 33 } 34 return B; 35 } 36 };
- 问题分析
为了找到前k个高频单词,采用算法如下:
首先统计字符串数组中每个字符串出现的次数。
建立最小堆,维护一个大小为k的最小堆,优先级小的元素在堆顶,每当某个新来的元素的优先级高于小顶堆的优先级时,将这个元素进堆,然后pop掉优先级最小的元素,堆的大小还是k。
优先级的判定需要重载()(注意一定要重载这个括号运算符而不是其他,因为末尾的greater<T>和less<T>里面也是重载的()),这里我们需要的是greater的功能,也就是说,需要优先级小的元素在堆顶。
- 代码参考
1 class Solution { 2 public: 3 struct compare{ 4 public: 5 bool operator() (const pair<int,string> &a,const pair<int,string> &b) 6 { 7 return (a.first>b.first||a.first==b.first&&a.second<b.second); 8 } 9 }; 10 vector<string> topKFrequent(vector<string>& words, int k) { 11 vector<string> B(k); 12 if(words.empty()||k<=0) 13 return B; 14 unordered_map<string,int> map; 15 compare ord; 16 //首先统计每个单词出现的次数 17 for(int i=0;i<words.size();++i) 18 { 19 map[words[i]]++; 20 } 21 priority_queue<pair<int,string>,vector<pair<int,string>>,compare > q; 22 for(auto it:map) 23 { 24 pair<int,string> temp{it.second,it.first}; 25 q.push(temp); 26 if(q.size()>k) 27 q.pop(); 28 } 29 for(int i=k-1;i>=0;--i) 30 { 31 B[i]=q.top().second; 32 q.pop(); 33 } 34 return B; 35 } 36 };

- 问题分析
要找到最小的K个数,可以使用最小堆来实现,依次弹出K个堆顶元素即可找到最小的k个元素
- 代码参考
1 class Solution { 2 public: 3 vector<int> getLeastNumbers(vector<int>& arr, int k) { 4 vector<int> B(k); 5 if(arr.empty()) 6 return B; 7 priority_queue<int,vector<int>,greater<int> > pri_que; 8 for(int i=0;i<arr.size();++i) 9 { 10 pri_que.push(arr[i]); 11 } 12 for(int i=0;i<k;++i) 13 { 14 B[i]=pri_que.top(); 15 pri_que.pop(); 16 } 17 return B; 18 } 19 };
- Solution 1:使用常规方法
- 问题分析1
丑数应该是另一个丑数乘以2,3,5的结果。对于乘以2而言,肯定存在一个丑数T2,排在他之前的每个丑数乘以2得到的结果都会小于已有最大的丑数,在他之后的丑数乘以2得到的结果都会太大,我们只需要记下这个丑数的位置,每次生成新的丑数的时候去更新这个T2即可
-
- 代码参考1
1 class Solution { 2 public: 3 //最小的丑数是2,3,5,后面的丑数一定是丑数乘以2,3,5,取最小的得到的 4 int Min(int a,int b,int c) 5 { 6 int min=a<b?a:b; 7 min=min<c?min:c; 8 return min; 9 } 10 int nthUglyNumber(int n) { 11 if(n<=0) 12 return 0; 13 int *uglynumbers=new int [n+1]; 14 uglynumbers[0]=1; 15 int *M2=uglynumbers; 16 int *M3=uglynumbers; 17 int *M5=uglynumbers; 18 int nextuglynumbers=1; 19 while(nextuglynumbers<n) 20 { 21 int min=Min(*M2*2,*M3*3,*M5*5); 22 uglynumbers[nextuglynumbers]=min; 23 while(*M2*2<=min) 24 ++M2; 25 while(*M3*3<=min) 26 ++M3; 27 while(*M5*5<=min) 28 ++M5; 29 ++nextuglynumbers; 30 } 31 int ugly=uglynumbers[nextuglynumbers-1]; 32 delete[]uglynumbers; 33 return ugly; 34 } 35 };
- Solution2 利用最小堆实现
- 问题分析2
由于丑数都是另一个丑数乘以2,3,5得到的,可以利用优先队列实现自动排序功能。
每次去除队头元素,存入队头元素*2,队头元素*3,队头元素*5
但是需要去重,因为想12这个元素,可以由3*4得到,也可以由2*6得到
-
- 代码参考2
1 class Solution { 2 public: 3 int nthUglyNumber(int n) { 4 if(n<=0) 5 return 0; 6 priority_queue<double,vector<double>,greater<double> >q; 7 double answer=1; 8 for(int i=1;i<n;++i) 9 { 10 q.push(answer*2); 11 q.push(answer*3); 12 q.push(answer*5); 13 answer=q.top(); 14 q.pop(); 15 while(!q.empty()&&answer==q.top()) 16 q.pop(); 17 } 18 return answer; 19 } 20 };

- Solution 1--利用数组特性来做
- 问题分析1
分析超级丑数和丑数的区别是:超级丑数的因子为质数列表primes中的元素,数组长度是未定的
在循环的过程中,可以先设置一个变量mini保存指针在uglynumbers中的位置对应的值x自身prime值的最小值,接着再循环一次将所有的指针位置进行更新
-
- 代码参考1
1 class Solution { 2 public: 3 int nthSuperUglyNumber(int n, vector<int>& primes) { 4 if(n<=0) 5 return 0; 6 int k=primes.size(); 7 vector<int> uglynumbers(n); 8 vector<int> kv(k,0);//用来记录这k个数的指针位置,初始化为0 9 int nextuglynumber=1; 10 uglynumbers[0]=1; 11 while(nextuglynumber<n) 12 { 13 int mini=INT_MAX; 14 for(int j=0;j<k;++j) 15 { 16 mini=min(mini,uglynumbers[kv[j]]*primes[j]); 17 } 18 uglynumbers[nextuglynumber]=mini; 19 for(int j=0;j<k;++j) 20 { 21 if(mini==uglynumbers[kv[j]]*primes[j]) 22 kv[j]++; 23 } 24 ++nextuglynumber; 25 } 26 return uglynumbers[nextuglynumber-1]; 27 } 28 };
- solution 2--利用堆
- 问题分析2
由于丑数都是另一个丑数乘以primes[i]得到的,可以利用优先队列实现自动排序功能。
每次去除队头元素,存入队头元素*primes[i];
但是需要去重
-
- 代码参考2
1 class Solution { 2 public: 3 int nthSuperUglyNumber(int n, vector<int>& primes) { 4 if(n<=0) 5 return 0; 6 priority_queue<long long,vector<long long>,greater<long long> >pq; 7 long long answer=1; 8 int k=primes.size(); 9 for(int i=1;i<n;++i) 10 { 11 for(int i=0;i<k;++i) 12 { 13 pq.push(answer*primes[i]); 14 15 } 16 answer=pq.top(); 17 pq.pop(); 18 while(!pq.empty()&&answer==pq.top()) 19 pq.pop(); 20 } 21 return answer; 22 } 23 };
- 问题分析
这道题类似于丑数的算法,我们将要找到的数称为丑数要得到有序的丑数数组,我们可以用前面的丑数乘以3,5,7,取最小值放入丑数数组即可。
1 class Solution { 2 public: 3 int Min(int a,int b,int c) 4 { 5 int min=a<b?a:b; 6 min=min<c?min:c; 7 return min; 8 } 9 int getKthMagicNumber(int k) { 10 if(k<=0) 11 return 0; 12 int *uglynumbers=new int[k+1]; 13 uglynumbers[0]=1; 14 int *M3=uglynumbers; 15 int *M5=uglynumbers; 16 int *M7=uglynumbers; 17 int nextuglynumbers=1; 18 while(nextuglynumbers<k) 19 { 20 int mini=Min(*M3*3,*M5*5,*M7*7); 21 uglynumbers[nextuglynumbers]=mini; 22 while(*M3*3<=mini) 23 ++M3; 24 while(*M5*5<=mini) 25 ++M5; 26 while(*M7*7<=mini) 27 ++M7; 28 ++nextuglynumbers; 29 } 30 return uglynumbers[nextuglynumbers-1]; 31 } 32 };
- 问题分析2
也可以用最小堆来实现,算法如下:
由于丑数都是另一个丑数乘以3,5,7得到的,可以利用优先队列实现自动排序功能。
每次去除队头元素,存入队头元素*3,队头元素*5,队头元素*7
但是需要去重
- 代码参考2
1 class Solution { 2 public: 3 int getKthMagicNumber(int k) { 4 if(k<=0) 5 return 0; 6 priority_queue<double,vector<double>,greater<double> > pq; 7 double answer=1; 8 for(int i=1;i<k;++i) 9 { 10 pq.push(answer*3); 11 pq.push(answer*5); 12 pq.push(answer*7); 13 answer=pq.top(); 14 pq.pop(); 15 //去重 16 while(!pq.empty()&&answer==pq.top()) 17 pq.pop(); 18 } 19 return answer; 20 } 21 };
- solution 1
- 问题分析(使用STL模板)
要实现找到未排序数组中第k个最大的元素,我们可以使用对排序
将数组中的元素建立一个最大堆,堆顶元素是最大的
要找到第k个最大元素,只需要删除k-1次堆顶元素,删除后堆顶元素即为第k个最大值
-
- 代码参考
1 class Solution { 2 public: 3 int findKthLargest(vector<int>& nums, int k) { 4 if(nums.empty()) 5 return 0; 6 //建立一个最大堆,对于第k大元素,删除k-1次后,堆顶元素就是数组排序后第k个最大的元素 7 priority_queue<int> pri_que; 8 for(int i=0;i<nums.size();++i) 9 { 10 pri_que.push(nums[i]); 11 } 12 //删除k-1次堆顶元素 13 for(int i=0;i<k-1;++i) 14 pri_que.pop(); 15 return pri_que.top(); 16 } 17 };
- solution2 (自己实现最大堆,包括最大堆的建堆,调整以及删除)
- 问题分析
-
- 代码参考
1 class Solution { 2 public: 3 //自己实现,要实现三个部分 4 //首先是堆化 5 //完全二叉树中,对于节点i,父节点为i/2,左子节点为i*2+1,右子节点为i*2+2 6 void maxHeapify(vector<int> &a,int i,int heapSize) 7 { 8 //左子节点 9 int l=i*2+1; 10 //右子节点 11 int r=i*2+2; 12 int largest=i; 13 if(l<heapSize&&a[l]>a[largest]) 14 largest=l; 15 if(r<heapSize&&a[r]>a[largest]) 16 largest=r; 17 if(largest!=i) 18 { 19 swap(a[i],a[largest]); 20 maxHeapify(a,largest,heapSize); 21 } 22 } 23 //建立堆 24 void buildMaxHeap(vector<int> &a,int heapSize) 25 { 26 //从第一个非叶子节点为根节点的子树开始,将其调整为最大堆 27 for(int i=heapSize/2;i>=0;--i) 28 { 29 maxHeapify(a,i,heapSize); 30 } 31 } 32 int findKthLargest(vector<int>& nums, int k) { 33 int heapSize=nums.size(); 34 buildMaxHeap(nums,heapSize); 35 for(int i=nums.size()-1;i>=nums.size()-k+1;--i) 36 { 37 swap(nums[0],nums[i]); 38 --heapSize; 39 maxHeapify(nums,0,heapSize); 40 } 41 return nums[0]; 42 43 } 44 };

- solution1--最大堆
- 问题分析1
要找到第k小的元素,一种最常规的做法就是使用优先队列
找第k小的元素,保留k个最小的元素,其中最大的那个就是答案,所以可以使用最大优先队列
遍历矩阵中的元素,将元素添加到队列中,如果队列中元素数目>k,则将堆点最大的元素弹出
遍历结束后弹出堆顶元素,就是最小的k个元素中最大的,即第k小的元素
-
- 代码参考1
1 class Solution {
2 public:
3 int kthSmallest(vector<vector<int>>& matrix, int k) {
4 if(matrix.empty())
5 return 0;
6 priority_queue<int> pri_que;
7 for(int i=0;i<matrix.size();++i)
8 {
9 for(int j=0;j<matrix[0].size();++j)
10 {
11 pri_que.push(matrix[i][j]);
12 if(pri_que.size()>k)
13 pri_que.pop();
14 }
15 }
16 return pri_que.top();
17 }
18 };
- solution2 --二分查找
- 问题分析2
方法1的方式没有用上矩阵的有序性,因此我们可以思考使用二分查找的方法
对于有序矩阵中,左上角元素是最小元素,右下角元素是最大元素
因此我们可以使用二分查找的方法,left=左上角元素,right=右下角元素
mid=left+(right-left)/2;统计大于mid的个数
如果小于mid的元素个数小于k,则比mid大的数可能是第k小元素
如果小于mid的元素个数大于k,则比mid小的数可能是第k小元素
在这里我们使用upper_bound来统计小于mid的元素个数
upper_bound()
upper_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
-
- 代码参考2
1 class Solution { 2 public: 3 int kthSmallest(vector<vector<int>>& matrix, int k) { 4 //有序矩阵中,左上角元素是最小的,右下角元素是最大的 5 /* 6 left=matrix[0][0],right=matrix[n][n],mid=left+(left-right)/2 7 统计大于mid的个数, 8 如果小于mid的元素个数小于k,则比mid大的数可能是第k小元素 9 如果小于mid的元素个数大于k,则比mid小的数可能是第k小元素 10 */ 11 if(matrix.empty()) 12 return 0; 13 int n=matrix.size()-1; 14 int left=matrix[0][0]; 15 int right=matrix[n][n]; 16 int mid; 17 18 while(left<right) 19 { 20 int ans=0; 21 mid=left+(right-left)/2; 22 for(int i=0;i<matrix.size();++i) 23 { 24 ans+=upper_bound(matrix[i].begin(),matrix[i].end(),mid)-matrix[i].begin(); 25 } 26 if(ans<k) 27 left=mid+1; 28 else 29 right=mid; 30 } 31 return left; 32 } 33 };

- 问题分析
有题意,最大堆即可解决问题,弹出最大的两个数据,若两个数据之差为0,则不用再次压入最大堆,否则将二者之差压入最大堆
- 代码参考
1 class Solution { 2 public: 3 int lastStoneWeight(vector<int>& stones) { 4 if(stones.empty()) 5 return 0; 6 priority_queue<int> pri_que(stones.begin(),stones.end()); 7 while(pri_que.size()>1) 8 { 9 int biggest=pri_que.top(); 10 pri_que.pop(); 11 int second=pri_que.top(); 12 pri_que.pop(); 13 int substraction=biggest-second; 14 if(substraction>0) 15 pri_que.push(substraction); 16 } 17 if(pri_que.size()>0) 18 return pri_que.top(); 19 else 20 return 0; 21 } 22 };
- 问题分析
要给字符串中的字符按照出现频率升降排序,可以采用以下算法
首先统计字符串中所有字符出现的次数,存储在哈希表中
根据字符串中所有字符出现的次数构造最大堆
依次输出
- 代码参考
1 class Solution { 2 public: 3 string frequencySort(string s) { 4 if(s.empty()) 5 return ""; 6 unordered_map<char,int> map; 7 //首先统计每个字符出现的次数 8 for(int i=0;i<s.size();++i) 9 { 10 map[s[i]]++; 11 } 12 //根据每个字符出现的次数,建立一个最大堆 13 priority_queue<pair<int,char>> pri_que; 14 for(auto &m:map) 15 { 16 pri_que.push({m.second,m.first}); 17 } 18 string res; 19 while(!pri_que.empty()) 20 { 21 auto t=pri_que.top(); 22 pri_que.pop(); 23 res.append(t.first,t.second); 24 } 25 return res; 26 } 27 };

- 问题分析
要找到数组中最小的k个数,可以使用大堆顶来实现,将数组中的每个元素都压栈入大堆顶,如果最大堆的元素个数大于k,则将最大堆的堆顶元素删除
- 代码参考
1 class Solution { 2 public: 3 vector<int> smallestK(vector<int>& arr, int k) { 4 vector<int> B; 5 if(arr.empty()||k<=0) 6 return B; 7 priority_queue<int,vector<int>,less<int> >q; 8 for(int i=0;i<arr.size();++i) 9 { 10 q.push(arr[i]); 11 if(q.size()>k) 12 q.pop(); 13 } 14 while(!q.empty()) 15 { 16 B.push_back(q.top()); 17 q.pop(); 18 } 19 20 return B; 21 } 22 };
- 问题分析
要判断是否可以重构字符串,可以采用算法如下
首先构建哈希表统计字符串中每个字符出现的次数,如果字符串中某个字符出现的次数超过字符串长度的一半,则不能重构字符串
然后构建一个最大堆,将哈希表中的键值对根据出现次数构建成一个最大堆
然后按照字母数量降序顺序,当队列不为空时,一次按照堆顶元素,隔着往原始字符串中插入当前字符,下标从0开始,每次插入下标+2,当超过数组大小时,变为1
- 代码参考
1 class Solution { 2 public: 3 string reorganizeString(string S) { 4 //哈希表+最大堆 5 /* 6 构造一个哈希表,其首先统计字符串中每个字符出现的次数 7 将哈希表字符及字符出现的次数压入大顶堆中 8 依次插入一个长度与S等长的字符串中 9 */ 10 if(S.empty()) 11 return ""; 12 //首先统计字符串中每个字符出现的次数,并将其存储在哈希表中 13 unordered_map<char,int> map; 14 for(int i=0;i<S.size();++i) 15 { 16 map[S[i]]++; 17 if(map[S[i]]>(S.size()+1)/2) 18 return ""; 19 } 20 21 22 //构造一个大顶堆存储哈希表 23 priority_queue<pair<int,char>,vector<pair<int,char>>> pq; 24 for(auto item:map) 25 { 26 pq.push({item.second,item.first}); 27 } 28 int i=0; 29 string res=S; 30 while(!pq.empty()) 31 { 32 char ch=pq.top().second; 33 int cnt=pq.top().first; 34 pq.pop(); 35 while(cnt--) 36 { 37 i=i>=S.size()?1:i; 38 res[i]=ch; 39 i=i+2; 40 } 41 } 42 return res; 43 } 44 };


- 问题分析
要实现找到最接近原点的K个点,我们可以构造一个大小为K的最大堆,当最大堆的尺寸大于K时,将堆顶元素弹出,因此最后最大堆中剩下的就是距离原点最小的K个点
构建的最大堆每次输入为一个长度为2的vector数组,此时不是基本类型,因此需要重载运算符()
- 代码参考
1 class Solution { 2 public: 3 //最大堆,因此需要重载() 4 class compare{ 5 public: 6 bool operator()(const vector<int>&a,const vector<int>&b) 7 { 8 return pow((pow(a[0],2)+pow(a[1],2)),0.5)<pow((pow(b[0],2)+pow(b[1],2)),0.5); 9 } 10 }; 11 vector<vector<int>> kClosest(vector<vector<int>>& points, int K) { 12 vector<vector<int>> B; 13 if(points.empty()) 14 return B; 15 //构建最大堆 16 priority_queue<vector<int>,vector<vector<int>>,compare> pq; 17 for(int i=0;i<points.size();++i) 18 { 19 int distance=pow(pow(points[i][0],2)+pow(points[i][1],2),0.5); 20 vector<int> temp={points[i][0],points[i][1]}; 21 pq.push(temp); 22 if(pq.size()>K) 23 pq.pop(); 24 } 25 for(int i=0;i<K;++i) 26 { 27 B.push_back(pq.top()); 28 pq.pop(); 29 } 30 return B; 31 } 32 };

- 问题分析
要查找和最小的K对数字,我们可以将nums1的第i个元素和nums2的第j个元素相加,并将数据对存储在长度为K的最大堆上
- 代码参考
1 class Solution { 2 public: 3 class compare{ 4 public: 5 bool operator()(const pair<int,int> &a,pair<int,int> &b) 6 { 7 return (a.first+a.second)<(b.first+b.second); 8 } 9 }; 10 vector<vector<int>> kSmallestPairs(vector<int>& nums1, vector<int>& nums2, int k) { 11 vector<vector<int>> B; 12 if(nums1.empty()||nums2.empty()) 13 return B; 14 15 priority_queue<pair<int,int>,vector<pair<int,int>>,compare> pq; 16 for(int i=0;i<nums1.size();++i) 17 { 18 for(int j=0;j<nums2.size();++j) 19 { 20 pq.push({nums1[i],nums2[j]}); 21 if(pq.size()>k) 22 pq.pop(); 23 } 24 } 25 while(!pq.empty()) 26 { 27 pair<int,int> top=pq.top(); 28 pq.pop(); 29 B.push_back({top.first,top.second}); 30 } 31 return B; 32 } 33 };