今天处理到一个比较棘手的问题。就是一张统计表中“工资及工资性费用”中要减去“部门奖金(2017年奖金)”,“奖金(其他)”这两个项目的和。
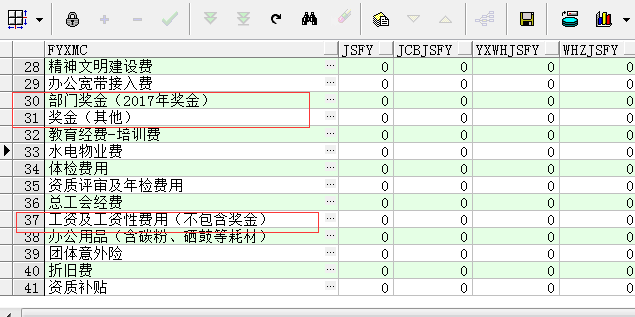
由于不是相邻两行或者相邻两列之间做差,所以没有普遍性。
思路就是:
首先查询出排除“工资及工资性费用”的集合。(SELECT * FROM XXX WHERE FYXMC NOT LIKE '%工资及工资性费用%' ) T1
然后,将标号为30和31的两行数据每个字段用SUM一次就和,分组字段就是除名称之外的所有字段。 其中REPLACE和TRIM的作用是去除左右两边的空格,包括全角的空格。
SELECT
REPLACE(REPLACE(TRIM(BOTH FROM FYXMC),' '),' ') FYXMC,SUM(JSFY) JSFY,SUM(JCBJSFY) JCBJSFY,SUM(YXWHJSFY) YXWHJSFY,SUM(WHZJSFY) WHZJSFY,SUM(HYSYJSFY) HYSYJSFY,
SUM(GZBJSFY) GZBJSFY,SUM(JSZCJSFY) JSZCJSFY,SUM(GSCMJSFY) GSCMJSFY,SUM(XMJSJSFY) XMJSJSFY,SUM(SWWZJSFY) SWWZJSFY,SUM(CPFHJSFY) CPFHJSFY,
SUM(JGGLJSFY) JGGLJSFY,SUM(CWJSFY) CWJSFY,SUM(RLZYJSFY) RLZYJSFY,SUM(BGSJSFY) BGSJSFY
FROM
GROUP BY REPLACE(REPLACE(TRIM(BOTH FROM FYXMC),' '),' '),T.JSFY,T.JCBJSFY,T.YXWHJSFY,T.WHZJSFY,T.HYSYJSFY,T.GZBJSFY,
T.JSZCJSFY,T.GSCMJSFY,T.XMJSJSFY,T.SWWZJSFY,T.CPFHJSFY,T.JGGLJSFY,T.CWJSFY,T.RLZYJSFY,T.BGSJSFY。
其次,以左外关联 LEFT JOIN的方式进行关联,T2每一个字段减去T4的每一个字段:
(SELECT '工资及工资性费用(不包含奖金)' FYXMC ,
T2.JSFY-T4.JSFY JSFY,T2.JCBJSFY-T4.JCBJSFY JCBJSFY,T2.YXWHJSFY-T4.YXWHJSFY YXWHJSFY,T2.WHZJSFY-T4.WHZJSFY WHZJSFY,T2.HYSYJSFY-T4.HYSYJSFY HYSYJSFY,
T2.GZBJSFY-T4.GZBJSFY GZBJSFY,T2.JSZCJSFY-T4.JSZCJSFY JSZCJSFY,T2.GSCMJSFY-T4.GSCMJSFY GSCMJSFY,T2.XMJSJSFY-T4.XMJSJSFY XMJSJSFY,T2.SWWZJSFY-T4.SWWZJSFY SWWZJSFY,
T2.CPFHJSFY-T4.CPFHJSFY CPFHJSFY,T2.JGGLJSFY-T4.JGGLJSFY JGGLJSFY,T2.CWJSFY-T4.CWJSFY CWJSFY,T2.RLZYJSFY-T4.RLZYJSFY RLZYJSFY,T2.BGSJSFY-T4.BGSJSFY BGSJSFY
FROM
T2
LEFT JOIN T4 ON T4.FYXMC=T2.FYXMC ) T3
最后,将处理过后的结果T1和T3用UNION ALL合并成最终结果集。
举一反三
如果有其他的特殊需求,比如其中特定的一行减去另外一行的每一列的数据,也可以用这种思路进行操作。
