前言
上一节我们讨论了视图中的一些限制以及建议等,这节我们讲讲关于在UDF和视图中使用SCHEMABINDING的问题,简短的内容,深入的理解,Always to review the basics。
SCHEMABINDING
在上节中我们讲到在视图创建索引时必须指定SCHEMABINDING,所以我们有必要先去了解下这个知识点再继续往下讲解。SCHEMABINDING到底是什么呢?在视图和UDF中有这个选项,如果在视图和UDF函数中指定了这个选项,那么说明会将视图和UDF严格绑定到数据库对象中去,一来指定此选项可以将其严格绑定到数据库对象中去,二来可以提高查询计划执行的性能。下面我们来看看关于SCHEMABINDING在UDF和视图中的使用。
在UDF中的使用
创建UDF函数有三种方式,我们一一来过一遍。
(1)创建TVF内嵌表值函数
USE TSQL2012 GO IF OBJECT_ID('dbo.GetOrderId') IS NOT NULL DROP FUNCTION dbo.GetOrderId; GO CREATE FUNCTION dbo.GetOrderId (@custid INT) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT orderid FROM Sales.Orders WHERE custid = @custid GO
上述UDF是通过TVF的方式来创建,当需要在里面声明一个临时变量并返回时我们需要像如下操作。
(2)创建标量值函数
USE TSQL2012 GO IF OBJECT_ID('dbo.GetOrderId') IS NOT NULL DROP FUNCTION dbo.GetOrderId; GO CREATE FUNCTION dbo.GetOrderId (@custid INT) RETURNS INT WITH SCHEMABINDING AS BEGIN DECLARE @tempID INT SELECT @tempID = orderid FROM Sales.Orders WHERE custid = @custid; RETURN @tempID; END;
当利用UDF来对查询出来的数据进行插入到临时表中时,我们可以像如下操作
(3)创建多语句TVF内嵌表值函数
USE TSQL2012 GO CREATE FUNCTION [UDF] (@PageNum int, @PageSize int) RETURNS @TestTable TABLE (RowNumber INT, ID INT, Name VARCHAR(20)) AS BEGIN declare @RowNumber int ;WITH C As ( SELECT 'RowNumber' = ROW_NUMBER() OVER(ORDER BY id DESC), orderid, shipname FROM Sales.Orders ) INSERT @TestTable SELECT rownumber, orderid, shipname from C RETURN END
好了我们过了一遍关于UDF创建的几种方式,我们回到主题,我们创建一个如下UDF
USE TSQL2012 GO IF OBJECT_ID('dbo.GetId') IS NOT NULL DROP FUNCTION dbo.GetId; GO CREATE FUNCTION dbo.GetId (@id INT) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT val1 FROM compare.t_inner WHERE id = @id GO
此时我们在对应数据库中的表值函数文件夹下能看到我们创建的函数

因为上述我们是查询表compare.t_inner中的值,此时我们删除该表看看。
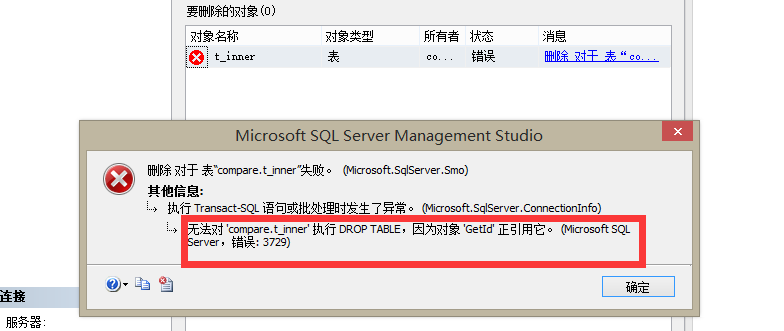
此时我们会发现该表无法删除出现上述错误。因为我们上述创建的UDF依赖于compare.t_inner表,所以现在无法删除该表,该表引用了自定义函数GetId。下面我们修改上述我们在UDF中查询的列val1为val3看看
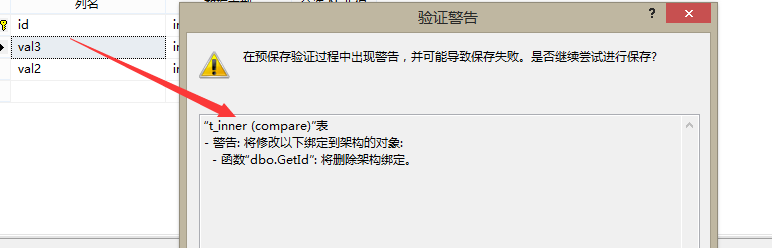
在VIEW中的使用
USE TSQL2012 GO IF OBJECT_ID('dbo.GetId') IS NOT NULL DROP FUNCTION dbo.GetId; GO CREATE VIEW GetId WITH SCHEMABINDING AS SELECT val1 FROM compare.t_inner
此时删除表compare.t_inner依然会出现和UDF中的错误。在使用SCHEMABINDING约束时不能进行*操作,会出现如下图错误:
USE TSQL2012 GO IF OBJECT_ID('dbo.GetId') IS NOT NULL DROP FUNCTION dbo.GetId; GO CREATE VIEW GetId WITH SCHEMABINDING AS SELECT * FROM compare.t_inner

下面再看其他情况利用视图到跨数据库进行查询,我们创建两个数据库并分别在对应数据库创建一个测试表。
CREATE DATABASE TEST1 CREATE DATABASE TEST2 GO -- Table1 USE Test1 GO CREATE TABLE TABLE1 (ID INT) GO USE Test2 GO -- Table2 CREATE TABLE TABLE2 (ID INT) GO USE Test1 GO
接下来通过执行SCHEMABINDING来创建视图
CREATE VIEW CrossDBView WITH SCHEMABINDING AS SELECT t1.ID AS t1id, t2.ID AS t2id FROM Test1.dbo.Table1 t1 INNER JOIN Test2.dbo.Table2 t2 ON t1.ID = t2.ID GO

上述指定SCHEMABINDING出现错误也就是说在跨数据库查询时会出现错误,对于引用对象仅限于两部分名称。到这里我们为在视图和UDF中使用SCHEMABINDING作出如下结论:
(1)在视图和UDF中使用SCHEMABINDING时必须满足两个要求,第一个是不允许在SELECT子句中使用*,第二个则是当引用对象时必须使用架构限定的两部分名称。
(2)在视图上创建索引时必须指定SCHEMABINDING。
如上讲了这么多关于SCHEMABINDING使用的限制,可以算是缺点吧,难道就没优点了么,如果没优点我们也不会讲了,当然也没必要给出SCHEMABINDING的使用了。当指定SCHEMABINDING时能提高UDF和视图的查询性能,当对象指定架构对象时,在查询计划中不会产生不必要的Spoll操作。我们看如下例子:
CREATE FUNCTION dbo.ComputeNum(@i int) RETURNS int BEGIN RETURN @i * 2 + 50 END
上述我们没有提供SCHEMABINDING选项,此时UDF不会访问任何数据库对象,当一个函数和视图没有SCHEMABINDING选项时就无法确保底层的数据库对象是什么,所以此时会去访问每个正在执行的UDF,为了避免这种性能问题,我们通过指定SCHEMABINDING是安全的并且不会去遍历访问每一个正在运行的UDF。所以在视图和UDF中一般建议指定SCHEMABINDING选项。
总结
本节我们讨论了在UDF和视图中指定SCHEMABINDING的问题,其实对视图查询还是有诸多限制,大部分情况下利用常规查询和存储过程来实现更加灵活。我们下节看看APPLY运算符的使用,简短的内容,深入的理解,我们下节再会。