在上一篇文章中,针对服务器单点、单例、单机存在的问题:
- 单点故障
- 容量有限
- 可支持的连接有限(性能不足)
提出了解决的办法:根据AKF原则搭建集群,大意是先X轴拆分,创建单机的镜像,组成主主、主备、主从模型,然后Y轴拆分,根据业务将不同的访问分配在不同的业务Redis上,对于同一业务的Redis,如果还不足以支撑并发访问,那么可以继续Z轴拆分,也就是根据数据拆分,详细情况参照:Redis集群拆分原则之AKF
结合上面提出一个新问题,如果一个服务,业务数据没法拆分,或者说不容易拆分呢?也就是没办法沿着Y-Z轴拆解,那么如何集群呢?
解决思路:
一致性Hash
哈希槽
一致性Hash
说到一致性Hash,就得先搞明白为什么要有一致性Hash,介绍一致性Hash算法之前,先简单回顾一下分布式以及Hash算法,便于理解为什么要有一致性Hash算法。
分布式
当我们也无需求很复杂时,单台机器IO以及带宽等都会成为瓶颈,所以对业务进行拆分,部署在不同的机器上,当有请求访问时,根据某些特点将这些请求分散到各个服务器上,这所有的服务器组成的网络,我们称之为集群,这能提高服务器的性能以及利用率。
如果有一个请求过来存数据,调度器将数据存在了A服务器上,下次客户端再来请求这份数据,该如何迅速判断数据存在哪台服务器呢?这时候引出了哈希的概念。
哈希函数
对于一个函数:
如果两个哈希值是不相同的,那么这两个哈希值的原始输入也是不相同的。这个特性是哈希函数具有确定性的结果,具有这种性质的哈希函数称为单向哈希函数。
但另一方面,哈希函数的输入和输出不是唯一对应关系的,如果两个哈希值相同,两个输入值很可能是相同的,但也可能不同,如果值相同称为“哈希碰撞(collision)”,这通常是两个不同长度的输入值,刻意计算出相同的输出值。输入一些数据计算出哈希值,然后部分改变输入值,一个具有强混淆特性的哈希函数会产生一个完全不同的哈希值。哈希函数是不可逆的,也就是没法根据哈希值来反推输入值。
那么对于集群而言,每一个请求都有一个标识ID,如果构造标识到服务器的哈希函数,就可以让同一请求固定的达到服务器,因为ID是不变的:
为了均匀分布在不同的服务器上,这是一个跟服务器数量N有关的哈希函数,常见的有取模运算,即:
但是这时候有个问题,由于是集群,那么服务器数量可能会有变化,例如今天请求量非常大要增加服务器数量,N变大之后,原有的Hash值就失效了,需要重新对存储的请求值做哈希,由于请求值是一个庞大的数据集.这样造成了巨大的不便,需要改进我们的Hash算法。这时候引出了一致性Hash的思路。
一致性Hash
一致性哈希的思路是,将哈希函数与服务器数量解绑,如果我们用16个二进制标识哈希值,那么哈希值有一个范围区间([0,65536]),我们将这个区间65536平均分成N份,N是服务器数量,然后将这些服务器节点等距离安排在一个圆环上
假设服务器数量是4,那么对于所有请求,哈希值必定是介于([0,65536])之间,当节点计算哈希后对应环上某一个点,这时候顺时针寻找离自己最近的服务节点作为存储节点,例如:当请求哈希值介于([0,16384])之间时,将请求分配到Server 1,如果请求哈希值介于((16384,32768])之间时,将请求分配到Server 2,后面同理,这样做有一个什么好处呢,如果这时候需要新增加一个服务器,假设是Server 5:

那么需要重新计算Hash值的仅仅为([0,8192])这部分请求,将其分配到Server 5上。

这地方有两点要注意,很多博客都没有提到:
一是原有节点信息本应该归server 2 存储,新增加了Server 5 之后根据新的规则会映射到Server 5上,那么之前存储在Server 1 上的数据需要重新取出来放在Server 5 上吗?
答案是否定的,只需要查找数据,在最近的点没找到,往下(顺时针)再查找一个点就行了,也可以再查找两个点(防止插入了两台新的服务节点)
二是,删除某个服务器节点
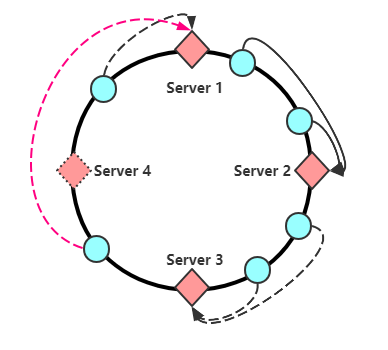
如图,删除服务器Server 4 之后,会将原有分布在Server4 上的请求全都压在Server1上,如果Server1 hold不住,那么可能挂掉,挂掉之后数据又转移给Server2,如此循环会造成所有节点崩溃,也就是雪崩的情况。这种雪崩可以靠下面的虚拟节点引入解决
虚拟节点的引入
我们已经知道,添加和删除节点都会影响缓存数据的分布。尽管hash算法具有分布均匀的特性,但是当集群中server数量很少时,他们可能在环中的分布并不是特别均匀,进而导致缓存数据不能均匀分布到所有的server上,例如都分配在某一个或几个哈希区间,那么有很多服务器可能就没在这个分布式系统中提供作用。
为解决这个问题,需要使用虚拟节点, 虚拟节点的思想:为每个物理节点(server)在环上分配100~200个点,这样环上的节点较多,就能抑制分布不均匀。当为cache定位目标server时,如果定位到虚拟节点上,就表示cache真正的存储位置是在该虚拟节点代表的实际物理server上。另外,如果每个实际server节点的负载能力不同,可以赋予不同的权重,根据权重分配不同数量的虚拟节点。定位算法不变,只是多了一步虚拟节点到真实节点映射的过程
为什么说这样能解决雪崩的发生呢,因为即使一台服务器挂了,他应对的虚拟节点也会消失,那也就是新来的数据依旧可在原区间内随机或者根据某种规律分配到其他节点上。
注意:真实节点不放置到哈希环上,只有虚拟节点才会放上去。
另外没法做数据库用(待补充)
哈希槽
了解哈希槽前景知识还是普通哈希,前面讲了哈希存在的问题是,当服务节点变化时,假如是增加到N+1,要对所有数据重新对服务器数量N+1取模,这在分布式中是难以接受的,太浪费时间。
那么,可不可以先假设我将来会有很多机器,例如一万台,对一万台取模,然后构建映射将取模值(哈希值)分区呢?Redis 集群的哈希槽就是这种思路:
用我们的Key值,对12取模,那么范围是在([0,11])之间,这儿的([0,11])就是我们所说的槽值,然后将这个范围区间切割成N份,N为服务器数量,如图:

之后如果新增了Redis服务器,只需要将映射的槽值对应的数据移动去新服务器就行了:
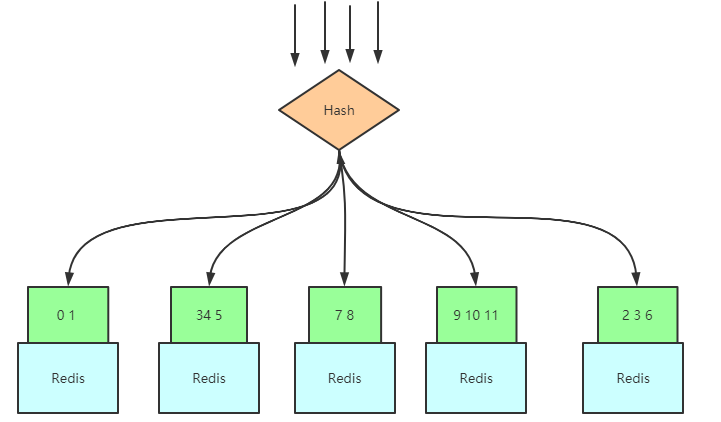
基于哈希槽的cluster集群
当客户端来获取数据时,随便连接到哪一个服务器上,服务器内置上面说的Hash算法,对请求Id进行Hash得到哈希值,每一个服务器内置一个表,这个表将哈希值对应的哈希槽与数据存储服务节点做一个映射,也就是请求压到任一台服务器,有数据的话会返回数据,没有的话会返回存储所需数据的服务器节点位置:

哈希槽与一致性哈希区别
它并不是闭合的,key的定位规则是根据CRC-16(key)%16384的值来判断属于哪个槽区,从而判断该key属于哪个节点,而一致性哈希是根据hash(key)的值来顺时针找第一个hash(ip)的节点,从而确定key存储在哪个节点。
一致性哈希是创建虚拟节点来实现节点宕机后的数据转移并保证数据的安全性和集群的可用性的。redis cluster是采用master节点有多个slave节点机制来保证数据的完整性的,master节点写入数据,slave节点同步数据。当master节点挂机后,slave节点会通过选举机制选举出一个节点变成master节点,实现高可用。但是这里有一点需要考虑,如果master节点存在热点缓存,某一个时刻某个key的访问急剧增高,这时该mater节点可能操劳过度而死,随后从节点选举为主节点后,同样宕机,一次类推,造成缓存雪崩。