![]()
1.项目简介
Apache Atlas是Hadoop社区为解决Hadoop生态系统的元数据治理问题而产生的开源项目,它为Hadoop集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。
2.项目架构
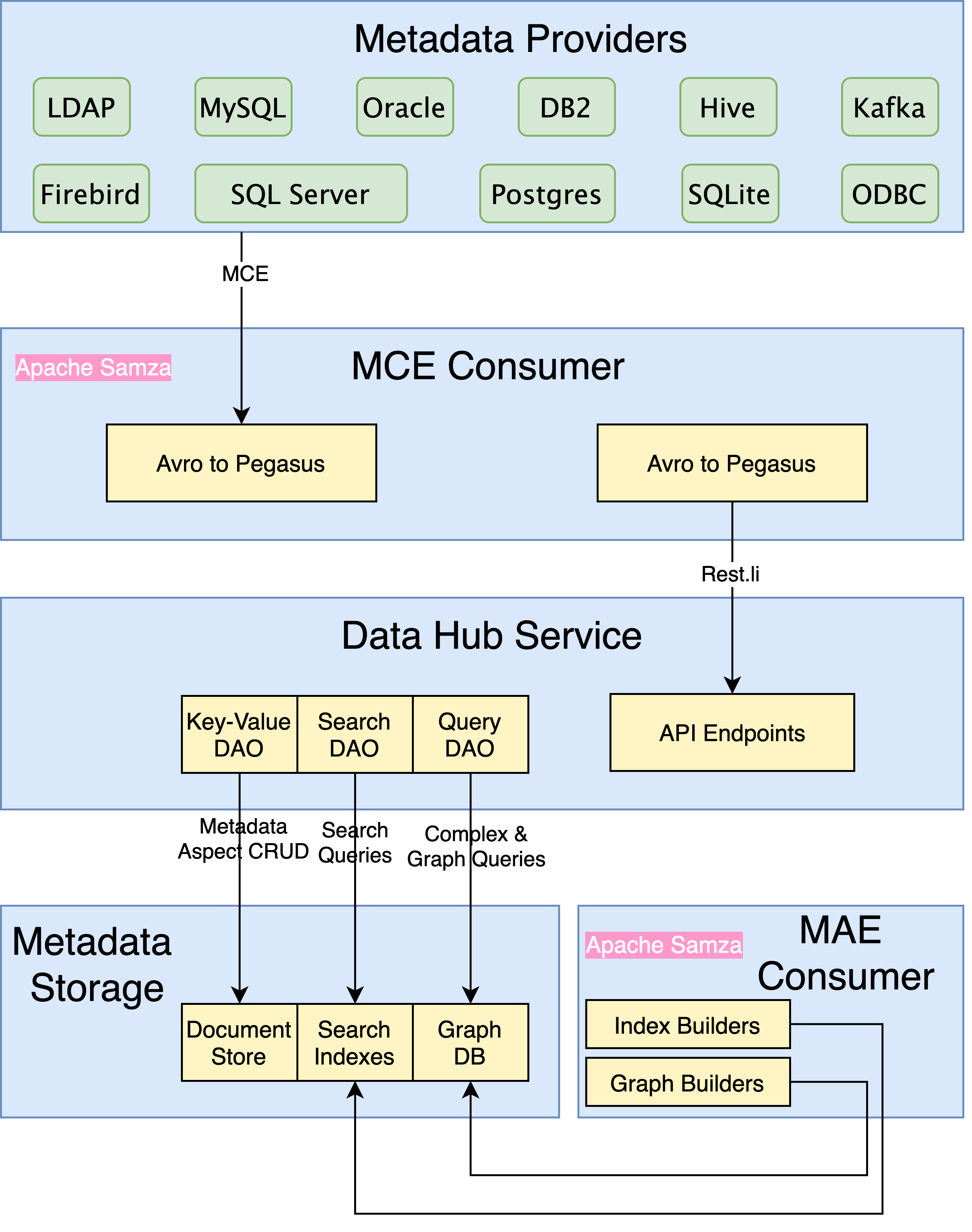
Data Hub使用的是Generalized metadata architecture(GMA),重点面对多种元数据可伸缩性的四项挑战。
- 建模:以对开发人员友好的方式对所有类型的元数据和关系进行建模。
- 摄取:通过API和流大规模摄取大量的元数据更改。
- 服务:大规模服务收集的原始元数据和派生的元数据,以及针对元数据的各种复杂查询。
- 索引:按比例索引元数据,并在元数据更改时自动更新索引。
元数据建模
元数据也是数据:
要对元数据建模,我们需要一种语言,其功能至少应与通用数据建模所使用的语言一样丰富。
元数据是分布式的:
期望所有元数据都来自单一来源是不现实的。例如,管理数据集的访问控制列表(ACL)的系统很可能不同于存储架构元数据的系统。一个好的建模框架应允许多个团队独立地发展其元数据模型,同时提供与数据实体关联的所有元数据的统一视图。
使用Pegasus(一种由LinkedIn创建的开源且完善的数据模式语言)进行元数据建模。
{
"type": "record",
"name": "User",
"fields": [
{
"name": "urn",
"type": "com.linkedin.common.UserUrn",
},
{
"name": "firstName",
"type": "string",
"optional": true
},
{
"name": "lastName",
"type": "string",
"optional": true
},
{
"name": "ldap",
"type": "com.linkedin.common.LDAP",
"optional": true
}
]
}
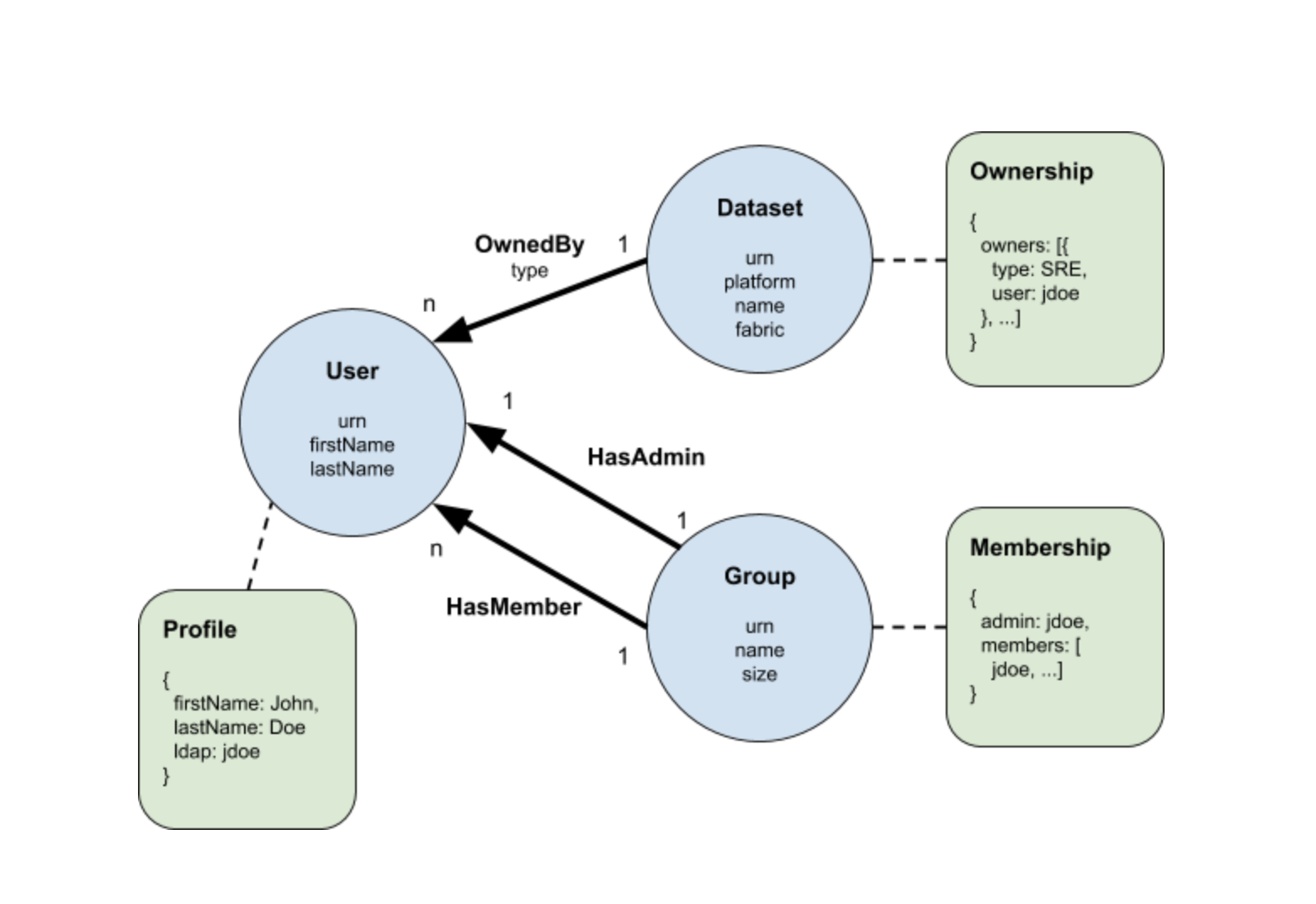
每个实体都必须具有URN形式的全局唯一ID ,可以将其视为类型化的GUID。User实体具有的属性包括名字,姓氏和LDAP,每个属性都映射到User记录中的可选字段。
{
"type": "record",
"name": "OwnedBy",
"fields": [
{
"name": "source",
"type": "com.linkedin.common.Urn",
},
{
"name": "destination",
"type": "com.linkedin.common.Urn",
},
{
"name": "type",
"type": "com.linkedin.common.OwnershipType",
}
],
"pairings": [
{
"source": "com.linkedin.common.urn.DatasetUrn",
"destination": "com.linkedin.common.urn.UserUrn"
}
]
}
每个关系模型自然包含使用其URN指向特定实体实例的“源”和“目的地”字段。模型可以选择包含其他属性字段,在这种情况下,例如“类型”。在这里,我们还引入了一个称为“ pairings”的自定义属性,以将关系限制为特定的源和目标URN类型对。在这种情况下,OwnedBy关系只能用于将数据集连接到用户。
"type": "record",
"name": "Ownership",
"fields": [
{
"name": "owners",
"type": {
"type": "array",
"items": {
"name": "owner",
"type": "record",
"fields": [
{
"name": "type",
"type": "com.linkedin.common.OwnershipType"
},
{
"name": "ldap",
"type": "string"
}
]
}
}
}
]
}
上面是所有权元数据方面的模型。在这里,我们选择将所有权建模为包含type和ldap字段的记录数组。但是,在建模元数据方面时,只要它是有效的PDSC记录,实际上就没有限制。这样就可以满足前面提到的“元数据也是数据”的要求。
元数据摄取
DataHub提供两种形式的元数据摄取:通过直接API调用或Kafka流。前者用于需要写入后读取一致性的元数据更改,而后者更适合于面向事实的更新。
DataHub的API基于Rest.li,这是一种可扩展的强类型RESTful服务架构,已在LinkedIn上广泛使用。由于Rest.li使用Pegasus作为其接口定义,因此可以逐字使用上一节中定义的所有元数据模型。从API到存储需要进行多层模型转换的日子已经一去不复返了-API和模型将始终保持同步。
对于基于Kafka的提取,预计元数据生产者会发出标准化的元数据更改事件(MCE),其中包含由相应实体URN键控的对特定元数据方面的建议更改列表。当MCE的模式位于Apache Avro中时,它是从Pegasus元数据模型自动生成的。
对API和Kafka事件模式使用相同的元数据模型,使我们能够轻松地开发模型,而无需精心维护相应的转换逻辑。但是,为了实现真正的无缝模式演变,我们需要限制所有模式更改以始终向后兼容。这是在构建时通过添加兼容性检查来强制实施的。
在领英,由于生产者和消费者之间的松散耦合,我们倾向于更加依赖Kafka流。每天,我们都会收到来自不同生产者的数百万个MCE,并且随着我们扩大元数据集合的范围,其数量只会呈指数增长。为了构建流元数据获取管道,我们利用Apache Samza作为流处理框架。摄取Samza作业的目的是快速,简单地实现高吞吐量。它只是将Avro数据转换回Pegasus,并调用相应的Rest.li API以完成提取。
元数据服务
一旦摄取并存储了元数据,有效地处理原始和派生的元数据就很重要。DataHub旨在支持对大量元数据的四种常见查询类型:
- 面向文档的查询
- 面向图的查询
- 涉及联接的复杂查询
- 全文搜索
为此,DataHub需要使用多种数据系统,每种数据系统专门用于扩展和服务有限类型的查询。例如,Espresso是LinkedIn的NoSQL数据库,特别适合大规模面向文档的CRUD。同样,Galene可以轻松索引并提供网络规模的全文搜索。当涉及到非平凡的图查询时,毫不奇怪的是,专用图数据库的性能要比基于RDBMS的实现好几个数量级。但是,事实证明,图结构也是表示外键关系的自然方法,从而可以有效地回答复杂的联接查询。
DataHub通过一组通用的数据访问对象(DAO)(例如键值DAO,查询DAO和搜索DAO )进一步抽象底层数据系统。然后,可以在不更改DataHub中任何业务逻辑的情况下轻松地换入和换出DAO的特定于数据系统的实现。这最终将使我们能够使用流行的开源系统的参考实现来开源DataHub,同时仍然充分利用LinkedIn的专有存储技术。
DAO抽象的另一个主要好处是标准化的变更数据捕获(CDC)。无论基础数据存储系统的类型如何,通过键值DAO进行的任何更新操作都将自动发出元数据审核事件(MAE)。每个MAE都包含相应实体的URN,以及特定元数据方面的前后图像。这实现了lambda体系结构,在此体系结构中,MAE可以批量或流式处理。与MCE相似,MAE的架构也可以从元数据模型中自动生成。
元数据索引
最后一个难题是元数据索引管道。该系统将元数据模型连接在一起,并在图形数据库和搜索引擎中创建相应的索引,以促进高效的查询。这些业务逻辑以“索引构建器”和“图形构建器”的形式捕获,并作为处理MAE的Samza作业的一部分执行。每个构建者都在工作中注册了对特定元数据方面的兴趣,并将通过相应的MAE进行调用。然后,构建器返回要应用于搜索索引或图形数据库的幂等更新的列表。
元数据索引管道还具有高度可伸缩性,因为它可以基于每个MAE的实体URN轻松进行分区,以支持对每个实体的有序处理。
DataHub安装记录
clone git项目
安装quickstart
cd datahub/docker/quickstart source ./quickstart.sh此时会开始部署各种docker容器