AudioTrack是Android中比较偏底层的用来播放音频的接口,它主要被用来播放PCM音频数据,和MediaPlayer不同,它不涉及到文件解析和解码等复杂的流程,比较适合通过它来分析Android系统播放音频数据的过程。下面是https://developer.android.com/reference/android/media/AudioTrack.html 对AudioTrank的描述:

1.应用层使用AudioTrack播放PCM音频数据
//MainActivity.java import android.app.Activity; import android.media.AudioFormat; import android.media.AudioManager; import android.media.AudioRecord; import android.media.AudioTrack; import android.media.MediaRecorder; import android.os.Bundle; import android.util.Log; import android.view.KeyEvent; import android.view.View; import android.widget.Button; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; public class MainActivity extends Activity { private static final String TAG = "VoiceRecord"; private static final int RECORDER_SAMPLERATE = 8000; private static final int RECORDER_CHANNELS_IN = AudioFormat.CHANNEL_IN_MONO; private static final int RECORDER_CHANNELS_OUT = AudioFormat.CHANNEL_OUT_MONO; private static final int RECORDER_AUDIO_ENCODING = AudioFormat.ENCODING_PCM_16BIT; private static final int AUDIO_SOURCE = MediaRecorder.AudioSource.MIC; // Initialize minimum buffer size in bytes. private int bufferSize = AudioRecord.getMinBufferSize(RECORDER_SAMPLERATE, RECORDER_CHANNELS_IN, RECORDER_AUDIO_ENCODING); private AudioRecord recorder = null; private Thread recordingThread = null; private boolean isRecording = false; @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); ((Button) findViewById(R.id.start_button)).setOnClickListener(btnClick); ((Button) findViewById(R.id.stop_button)).setOnClickListener(btnClick); enableButtons(false); } private void enableButton(int id, boolean isEnable) { ((Button) findViewById(id)).setEnabled(isEnable); } private void enableButtons(boolean isRecording) { enableButton(R.id.start_button, !isRecording); enableButton(R.id.stop_button, isRecording); } private void startRecording() { if( bufferSize == AudioRecord.ERROR_BAD_VALUE) Log.e(TAG, "Bad Value for "bufferSize", recording parameters are not supported by the hardware"); if( bufferSize == AudioRecord.ERROR ) Log.e( TAG, "Bad Value for "bufferSize", implementation was unable to query the hardware for its output properties"); Log.e( TAG, ""bufferSize"="+bufferSize); // Initialize Audio Recorder. recorder = new AudioRecord(AUDIO_SOURCE, RECORDER_SAMPLERATE, RECORDER_CHANNELS_IN, RECORDER_AUDIO_ENCODING, bufferSize); // Starts recording from the AudioRecord instance. recorder.startRecording(); isRecording = true; recordingThread = new Thread(new Runnable() { public void run() { writeAudioDataToFile(); } }, "AudioRecorder Thread"); recordingThread.start(); } private void writeAudioDataToFile() { //Write the output audio in byte String filePath = "/sdcard/8k16bitMono.pcm"; byte saudioBuffer[] = new byte[bufferSize]; FileOutputStream os = null; try { os = new FileOutputStream(filePath); } catch (FileNotFoundException e) { e.printStackTrace(); } while (isRecording) { // gets the voice output from microphone to byte format recorder.read(saudioBuffer, 0, bufferSize); try { // writes the data to file from buffer stores the voice buffer os.write(saudioBuffer, 0, bufferSize); } catch (IOException e) { e.printStackTrace(); } } try { os.close(); } catch (IOException e) { e.printStackTrace(); } } private void stopRecording() throws IOException { // stops the recording activity if (null != recorder) { isRecording = false; recorder.stop(); recorder.release(); recorder = null; recordingThread = null; PlayShortAudioFileViaAudioTrack("/sdcard/8k16bitMono.pcm"); } } private void PlayShortAudioFileViaAudioTrack(String filePath) throws IOException{ // We keep temporarily filePath globally as we have only two sample sounds now.. if (filePath==null) return; //Reading the file.. File file = new File(filePath); // for ex. path= "/sdcard/samplesound.pcm" or "/sdcard/samplesound.wav" byte[] byteData = new byte[(int) file.length()]; Log.d(TAG, (int) file.length()+""); FileInputStream in = null; try { in = new FileInputStream( file ); in.read( byteData ); in.close(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } // Set and push to audio track.. int intSize = android.media.AudioTrack.getMinBufferSize(RECORDER_SAMPLERATE, RECORDER_CHANNELS_OUT, RECORDER_AUDIO_ENCODING); Log.d(TAG, intSize+""); AudioTrack at = new AudioTrack(AudioManager.STREAM_MUSIC, RECORDER_SAMPLERATE, RECORDER_CHANNELS_OUT, RECORDER_AUDIO_ENCODING, intSize, AudioTrack.MODE_STREAM); if (at!=null) { at.play(); // Write the byte array to the track at.write(byteData, 0, byteData.length); at.stop(); at.release(); } else Log.d(TAG, "audio track is not initialised "); } private View.OnClickListener btnClick = new View.OnClickListener() { public void onClick(View v) { switch (v.getId()) { case R.id.start_button: { enableButtons(true); startRecording(); break; } case R.id.stop_button: { enableButtons(false); try { stopRecording(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } break; } } } }; // onClick of backbutton finishes the activity. @Override public boolean onKeyDown(int keyCode, KeyEvent event) { if (keyCode == KeyEvent.KEYCODE_BACK) { finish(); } return super.onKeyDown(keyCode, event); } }
<!--activity_main.xml--> <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" android:orientation="vertical"> <Button android:layout_width="match_parent" android:layout_height="wrap_content" android:id="@+id/start_button" android:text="start"/> <Button android:layout_width="match_parent" android:layout_height="wrap_content" android:id="@+id/stop_button" android:text="stop"/> </LinearLayout>
在AndroidManifest.xml中添加权限
<uses-permission android:name="android.permission.RECORD_AUDIO"/> <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
通过上面的例子可以看出,使用AudioTrack播放PCM数据一般的步骤为:
(1)根据音频数据的特性来确定所要分配的缓冲区的最小size
int intSize = android.media.AudioTrack.getMinBufferSize(RECORDER_SAMPLERATE, RECORDER_CHANNELS_OUT, RECORDER_AUDIO_ENCODING);
其中第一个参数为采样率,第二个参数为声道数,第三个参数为采样精度
(2)创建AudioTrack
AudioTrack at = new AudioTrack(AudioManager.STREAM_MUSIC,RECORDER_SAMPLERATE,RECORDER_CHANNELS_OUT, RECORDER_AUDIO_ENCODING, intSize, AudioTrack.MODE_STREAM);
第一个参数为音频流类型,音频流类型的划分和Audio系统对音频的管理策略有关。最后一个参数为数据加载模式分为MODE_STREAM和MODE_STATIC两种:
MODE_STREAM:通过 write 一次次把音频数据写到 AudioTrack 中。这种工作方式每次都需要把数据从用户提供的 buffer 拷贝到 AudioTrack 内部 buffer。
MODE_STATIC:在 play 之前只需要把数据通过一次 write 调用传递到 AudioTrack 内部 buffer。适用于内存占用量小,延迟要求高的文件。
(3)开始播放
at.play();
(4)循环往AudioTrack中写数据
at.write(byteData, 0, byteData.length);
(5)停止播放和释放资源
at.stop();
at.release();
2.Framework层AudioTrack分析
上面我们分析了应用层使用AudioTrack来播放PCM音频数据的主要步骤,所以接下来就来分析一下各个步骤中Android Framework层都做了些什么,以及每一个步骤是怎么一步步调用到底层去的。
2.1创建AudioTrack
在上面应用层使用AudioTrack播放PCM数据的例子里,我们首先根据给出的音频参数通过 android.media.AudioTrack.getMinBufferSize 方法获得了需要分配的最小的缓冲区大小。然后创建了一个AudioTrack对象。整个打开output的流程如下图所示。

在创建AudioTrack对象的时候,不管调用的那个构造方法,最终都会调用到
public AudioTrack(AudioAttributes attributes, AudioFormat format, int bufferSizeInBytes,int mode, int sessionId)
这个构造方法,下面就以这个构造方法为切入点来分析AudioTrack对象的构造过程。
// frameworks/base/media/java/android/media/AudioTrack.java public AudioTrack(AudioAttributes attributes, AudioFormat format, int bufferSizeInBytes,int mode, int sessionId) throws IllegalArgumentException { .... //调用JNI函数 int initResult = native_setup(new WeakReference<AudioTrack>(this), mAttributes, mSampleRate, mChannelMask, mChannelIndexMask, mAudioFormat, mNativeBufferSizeInBytes, mDataLoadMode, session); .... }
在这个构造函数中,首先对传入的参数进行了处理,然后调用了JNI层native_setup()函数,我们就根据这条主线继续跳到JNI层进行分析。
// frameworks/base/core/jni/android_media_AudioTrack.cpp static jint android_media_AudioTrack_setup(JNIEnv *env, jobject thiz, jobject weak_this, jobject jaa,jint sampleRateInHertz, jint channelPositionMask, jint channelIndexMask, jint audioFormat, jint buffSizeInBytes, jint memoryMode, jintArray jSession) { ...... // create the native AudioTrack object sp<AudioTrack> lpTrack = new AudioTrack(); //生成一个Storage对象用来存储音频数据 // initialize the callback information: // this data will be passed with every AudioTrack callback AudioTrackJniStorage* lpJniStorage = new AudioTrackJniStorage(); .... //调用native AudioTrack的set函数!!! status = lpTrack->set( // stream type, but more info conveyed in paa (last argument) AUDIO_STREAM_DEFAULT, sampleRateInHertz, format,// word length, PCM nativeChannelMask, frameCount, AUDIO_OUTPUT_FLAG_NONE, //回调函数 回调数据 audioCallback, &(lpJniStorage->mCallbackData),//callback, callback data (user) 0, lpJniStorage->mMemBase,// shared mem true,// thread can call Java sessionId,// audio session ID AudioTrack::TRANSFER_SYNC, NULL, // default offloadInfo -1, -1, // default uid, pid values paa); ...... }
JNI层函数native_setup创建了一个AudioTrack(native)对象,然后进行各种属性的计算,最后调用AudioTrack(native)对象的set()函数来设置这些属性,对于两种不同的内存模式(MODE_STATIC和MODE_STREAM有不同的处理方式:
对于静态方式set的倒数第三个参数是lpJniStorage->mMemBase,而对于STREAM类型这个参数为null(0)。
首先来看一下native层AudioTrack的无参构造函数
// frameworks/av/media/libmedia/AudioTrack.cpp AudioTrack::AudioTrack() : mStatus(NO_INIT), mIsTimed(false), mPreviousPriority(ANDROID_PRIORITY_NORMAL), mPreviousSchedulingGroup(SP_DEFAULT), mPausedPosition(0), mSelectedDeviceId(AUDIO_PORT_HANDLE_NONE) { mAttributes.content_type = AUDIO_CONTENT_TYPE_UNKNOWN; mAttributes.usage = AUDIO_USAGE_UNKNOWN; mAttributes.flags = 0x0; strcpy(mAttributes.tags, ""); }
可以看出来,在这个构造函数里面只是对参数进行了处理,并没有我们想要看到的那些流程,接下来就来分析这个set()函数。
// frameworks/av/media/libmedia/AudioTrack.cpp status_t AudioTrack::set( audio_stream_type_t streamType, uint32_t sampleRate, audio_format_t format, audio_channel_mask_t channelMask, size_t frameCount, audio_output_flags_t flags, callback_t cbf, void* user, uint32_t notificationFrames, const sp<IMemory>& sharedBuffer, bool threadCanCallJava, int sessionId, transfer_type transferType, const audio_offload_info_t *offloadInfo, int uid, pid_t pid, const audio_attributes_t* pAttributes, bool doNotReconnect) { //放开这个log可以看出创建AudioTrack时设置的参数,从而判断后面选择的output是否正确 ALOGV("set(): streamType %d, sampleRate %u, format %#x, channelMask %#x, frameCount %zu, " "flags #%x, notificationFrames %u, sessionId %d, transferType %d, uid %d, pid %d", streamType, sampleRate, format, channelMask, frameCount, flags, notificationFrames, sessionId, transferType, uid, pid); ...... ALOGV_IF(sharedBuffer != 0, "sharedBuffer: %p, size: %zu", sharedBuffer->pointer(), sharedBuffer->size()); ALOGV("set() streamType %d frameCount %zu flags %04x", streamType, frameCount, flags); // invariant that mAudioTrack != 0 is true only after set() returns successfully if (mAudioTrack != 0) { ALOGE("Track already in use"); return INVALID_OPERATION; } //当AudioTrack没有指明streamType时,程序会设为默认值AUDIO_STREAM_MUSIC // handle default values first. if (streamType == AUDIO_STREAM_DEFAULT) { streamType = AUDIO_STREAM_MUSIC; } if (pAttributes == NULL) { if (uint32_t(streamType) >= AUDIO_STREAM_PUBLIC_CNT) { ALOGE("Invalid stream type %d", streamType); return BAD_VALUE; } mStreamType = streamType; } else { // stream type shouldn't be looked at, this track has audio attributes memcpy(&mAttributes, pAttributes, sizeof(audio_attributes_t)); ALOGV("Building AudioTrack with attributes: usage=%d content=%d flags=0x%x tags=[%s]", mAttributes.usage, mAttributes.content_type, mAttributes.flags, mAttributes.tags); mStreamType = AUDIO_STREAM_DEFAULT; if ((mAttributes.flags & AUDIO_FLAG_HW_AV_SYNC) != 0) { flags = (audio_output_flags_t)(flags | AUDIO_OUTPUT_FLAG_HW_AV_SYNC); } } //采样深度默认为16bit // these below should probably come from the audioFlinger too... if (format == AUDIO_FORMAT_DEFAULT) { format = AUDIO_FORMAT_PCM_16_BIT; } // validate parameters if (!audio_is_valid_format(format)) { ALOGE("Invalid format %#x", format); return BAD_VALUE; } mFormat = format; if (!audio_is_output_channel(channelMask)) { ALOGE("Invalid channel mask %#x", channelMask); return BAD_VALUE; } mChannelMask = channelMask; uint32_t channelCount = audio_channel_count_from_out_mask(channelMask); mChannelCount = channelCount; //flag等参数会影响到选择哪一个output // force direct flag if format is not linear PCM // or offload was requested if ((flags & AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD) || !audio_is_linear_pcm(format)) { ALOGV( (flags & AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD) ? "Offload request, forcing to Direct Output" : "Not linear PCM, forcing to Direct Output"); flags = (audio_output_flags_t) // FIXME why can't we allow direct AND fast? ((flags | AUDIO_OUTPUT_FLAG_DIRECT) & ~AUDIO_OUTPUT_FLAG_FAST); } // force direct flag if HW A/V sync requested if ((flags & AUDIO_OUTPUT_FLAG_HW_AV_SYNC) != 0) { flags = (audio_output_flags_t)(flags | AUDIO_OUTPUT_FLAG_DIRECT); } if (flags & AUDIO_OUTPUT_FLAG_DIRECT) { if (audio_is_linear_pcm(format)) { mFrameSize = channelCount * audio_bytes_per_sample(format); } else { mFrameSize = sizeof(uint8_t); } } else { ALOG_ASSERT(audio_is_linear_pcm(format)); mFrameSize = channelCount * audio_bytes_per_sample(format); // createTrack will return an error if PCM format is not supported by server, // so no need to check for specific PCM formats here } // sampling rate must be specified for direct outputs if (sampleRate == 0 && (flags & AUDIO_OUTPUT_FLAG_DIRECT) != 0) { return BAD_VALUE; } mSampleRate = sampleRate; mOriginalSampleRate = sampleRate; mPlaybackRate = AUDIO_PLAYBACK_RATE_DEFAULT; // Make copy of input parameter offloadInfo so that in the future: // (a) createTrack_l doesn't need it as an input parameter // (b) we can support re-creation of offloaded tracks if (offloadInfo != NULL) { mOffloadInfoCopy = *offloadInfo; mOffloadInfo = &mOffloadInfoCopy; } else { mOffloadInfo = NULL; } //左右声道初始音量都设置成最大 mVolume[AUDIO_INTERLEAVE_LEFT] = 1.0f; mVolume[AUDIO_INTERLEAVE_RIGHT] = 1.0f; mSendLevel = 0.0f; ...... //创 建 track 线 程 if (cbf != NULL) { //AudioTrackThread需要实现两个核心功能: //1.AudioTrack与AudioFlinger间的数据传输,AudioFlinger启动了一个线程专门用于接收客户端的 //音频数据,同理,客户端也需要一个工作线程来“不断”的传送音频数据 //2.用于报告数据的传输状态,AudioTrack中保存了一个callback_t类型的回调函数(即全局变量mCbf) //用于事件发生时进行回传 mAudioTrackThread = new AudioTrackThread(*this, threadCanCallJava); //其实就是调用AudioTrackThread::threadLoop()函数 mAudioTrackThread->run("AudioTrack", ANDROID_PRIORITY_AUDIO, 0 /*stack*/); // thread begins in paused state, and will not reference us until start() } //AudioTrack在AudioFlinger内部是以Track类来管理的,不过因为他们之间是跨进程的关系,自然需要一个 //桥梁来维护(Binder),这个沟通的媒介是IaudioTrack,createTrack_l除了为AudioTrack在AudioFlinger //中申请一个Track外,还会建立两者之间的IAudioTrack桥梁 // create the IAudioTrack status_t status = createTrack_l(); if (status != NO_ERROR) { if (mAudioTrackThread != 0) { mAudioTrackThread->requestExit(); // see comment in AudioTrack.h mAudioTrackThread->requestExitAndWait(); mAudioTrackThread.clear(); } return status; } ...... return NO_ERROR; }
Native层AudioTrack的set函数在对各个参数进行处理之后,调用了creatTrack_l()函数来创建IAudioTrack,与AudioFlinger建立联系。
//frameworks/av/media/libmedia/AudioTrack.cpp // must be called with mLock held status_t AudioTrack::createTrack_l() { //获取AudioFlinger的Binder代理 const sp<IAudioFlinger>& audioFlinger = AudioSystem::get_audio_flinger(); if (audioFlinger == 0) { ALOGE("Could not get audioflinger"); return NO_INIT; } if (mDeviceCallback != 0 && mOutput != AUDIO_IO_HANDLE_NONE) { AudioSystem::removeAudioDeviceCallback(mDeviceCallback, mOutput); } //audio_io_handle_t是一个通过typedef定义在audio.h中的int类型,这个值主要被AudioFlinger使用 //用来表示内部的工作线程的索引号,AudioFlinger会根据情况创建几个工作线程 //AudioSystem::getOutputForAttr会根据流类型等参数选取一个合适的工作线程 //并将它在AF中的索引号保存在output变量中,AudioTrack一般使用混音线程(MixerThread) audio_io_handle_t output; //AUDIO_STREAM_MUSIC audio_stream_type_t streamType = mStreamType; audio_attributes_t *attr = (mStreamType == AUDIO_STREAM_DEFAULT) ? &mAttributes : NULL; status_t status; //根据根据流类型、flag等参数选取一个合适的工作线程(PlaybackThread) status = AudioSystem::getOutputForAttr(attr, &output, (audio_session_t)mSessionId, &streamType, mClientUid, mSampleRate, mFormat, mChannelMask, mFlags, mSelectedDeviceId, mOffloadInfo); if (status != NO_ERROR || output == AUDIO_IO_HANDLE_NONE) { ALOGE("Could not get audio output for session %d, stream type %d, usage %d, sample rate %u, format %#x," " channel mask %#x, flags %#x", mSessionId, streamType, mAttributes.usage, mSampleRate, mFormat, mChannelMask, mFlags); return BAD_VALUE; } ...... size_t temp = frameCount; // temp may be replaced by a revised value of frameCount, // but we will still need the original value also int originalSessionId = mSessionId; //调用createTrack返回AudioFlinger内部的AudioTrack的binder代理 //IAudioTrack是联系AudioTrack和AudioFlinger的关键纽带 sp<IAudioTrack> track = audioFlinger->createTrack(streamType, mSampleRate, mFormat, mChannelMask, &temp, &trackFlags, mSharedBuffer, output, tid, &mSessionId, mClientUid, &status); ALOGE_IF(originalSessionId != AUDIO_SESSION_ALLOCATE && mSessionId != originalSessionId, "session ID changed from %d to %d", originalSessionId, mSessionId); if (status != NO_ERROR) { ALOGE("AudioFlinger could not create track, status: %d", status); goto release; } ALOG_ASSERT(track != 0); // AudioFlinger now owns the reference to the I/O handle, // so we are no longer responsible for releasing it. //获取 track 的共享 buffer //当PlaybackThread创建一个PlaybackThread::Track对象时,所需的缓冲区空间 //就已经分配了,这块空间是可以跨进程共享的,所以AudioTrack可以通过track->getCblk //来获取,到目前为止,AudioTrack已经可以通过IaudioTrack(track变量)来调用 //AudioFlinger提供的服务了 //创建了AudioTrack实例之后,应用实例就可以通过不断写入(AudioTrack::write) //音频数据来回放声音 sp<IMemory> iMem = track->getCblk();//向AudioFlinger申请数据缓冲空间 if (iMem == 0) { ALOGE("Could not get control block"); return NO_INIT; } void *iMemPointer = iMem->pointer(); if (iMemPointer == NULL) { ALOGE("Could not get control block pointer"); return NO_INIT; } // invariant that mAudioTrack != 0 is true only after set() returns successfully if (mAudioTrack != 0) { IInterface::asBinder(mAudioTrack)->unlinkToDeath(mDeathNotifier, this); mDeathNotifier.clear(); } //与AudioFlinger进行通信的中介 mAudioTrack = track; mCblkMemory = iMem; IPCThreadState::self()->flushCommands(); audio_track_cblk_t* cblk = static_cast<audio_track_cblk_t*>(iMemPointer); mCblk = cblk; // note that temp is the (possibly revised) value of frameCount if (temp < frameCount || (frameCount == 0 && temp == 0)) { // In current design, AudioTrack client checks and ensures frame count validity before // passing it to AudioFlinger so AudioFlinger should not return a different value except // for fast track as it uses a special method of assigning frame count. ALOGW("Requested frameCount %zu but received frameCount %zu", frameCount, temp); } frameCount = temp; ...... // Starting address of buffers in shared memory. If there is a shared buffer, buffers // is the value of pointer() for the shared buffer, otherwise buffers points // immediately after the control block. This address is for the mapping within client // address space. AudioFlinger::TrackBase::mBuffer is for the server address space. void* buffers; if (mSharedBuffer == 0) { buffers = cblk + 1; } else { buffers = mSharedBuffer->pointer(); if (buffers == NULL) { ALOGE("Could not get buffer pointer"); return NO_INIT; } } ...... // reset server position to 0 as we have new cblk. mServer = 0; // update proxy if (mSharedBuffer == 0) { mStaticProxy.clear(); //创建 Client Proxy //在 AudioFlinger 调用 mAudioTrackServerProxy = new AudioTrackServerProxy(),创建 Server Proxy。 // Proxy类封装了 track 共享 buffer 的操控接口,实现共享 buffer 的使用 mProxy = new AudioTrackClientProxy(cblk, buffers, frameCount, mFrameSize); } else { mStaticProxy = new StaticAudioTrackClientProxy(cblk, buffers, frameCount, mFrameSize); mProxy = mStaticProxy; } //调用 Proxy 的 set 接口,设置保存 VolumeLR,SampleRate,SendLevel 等参数, //AudioFlinger mixer 线程中会把这些参数取出来实现混音 mProxy->setVolumeLR(gain_minifloat_pack( gain_from_float(mVolume[AUDIO_INTERLEAVE_LEFT]), gain_from_float(mVolume[AUDIO_INTERLEAVE_RIGHT]))); mProxy->setSendLevel(mSendLevel); const uint32_t effectiveSampleRate = adjustSampleRate(mSampleRate, mPlaybackRate.mPitch); const float effectiveSpeed = adjustSpeed(mPlaybackRate.mSpeed, mPlaybackRate.mPitch); const float effectivePitch = adjustPitch(mPlaybackRate.mPitch); mProxy->setSampleRate(effectiveSampleRate); AudioPlaybackRate playbackRateTemp = mPlaybackRate; playbackRateTemp.mSpeed = effectiveSpeed; playbackRateTemp.mPitch = effectivePitch; mProxy->setPlaybackRate(playbackRateTemp); mProxy->setMinimum(mNotificationFramesAct); mDeathNotifier = new DeathNotifier(this); IInterface::asBinder(mAudioTrack)->linkToDeath(mDeathNotifier, this); if (mDeviceCallback != 0) { AudioSystem::addAudioDeviceCallback(mDeviceCallback, mOutput); } return NO_ERROR; } release: AudioSystem::releaseOutput(output, streamType, (audio_session_t)mSessionId); if (status == NO_ERROR) { status = NO_INIT; } return status; }
AudioSystem::getOutputForAttr 最终会调用到AudioPolicyManager::getOutputForAttr它会根据创建AudioTrack时传入的参数创建一个合适的PlaybackThread,并且选择合适的输出设备。我们来看一下AudioPolicyManager::getOutputForAttr这个函数
status_t AudioPolicyManager::getOutputForAttr(const audio_attributes_t *attr, audio_io_handle_t *output, audio_session_t session, audio_stream_type_t *stream, uid_t uid, uint32_t samplingRate, audio_format_t format, audio_channel_mask_t channelMask, audio_output_flags_t flags, audio_port_handle_t selectedDeviceId, const audio_offload_info_t *offloadInfo) { ...... //放开这个log可以看出参数、选择的设备是否正确 ALOGV("getOutputForAttr() usage=%d, content=%d, tag=%s flags=%08x" " session %d selectedDeviceId %d", attributes.usage, attributes.content_type, attributes.tags, attributes.flags, session, selectedDeviceId); *stream = streamTypefromAttributesInt(&attributes); ...... mOutputRoutes.addRoute(session, *stream, SessionRoute::SOURCE_TYPE_NA, deviceDesc, uid); //通过属性获取策略 routing_strategy strategy = (routing_strategy) getStrategyForAttr(&attributes); //通过策略获取输出设备 audio_devices_t device = getDeviceForStrategy(strategy, false /*fromCache*/); if ((attributes.flags & AUDIO_FLAG_HW_AV_SYNC) != 0) { flags = (audio_output_flags_t)(flags | AUDIO_OUTPUT_FLAG_HW_AV_SYNC); } ALOGV("getOutputForAttr() device 0x%x, samplingRate %d, format %x, channelMask %x, flags %x", device, samplingRate, format, channelMask, flags); //通过输出设备选择output线程 *output = getOutputForDevice(device, session, *stream, samplingRate, format, channelMask, flags, offloadInfo); if (*output == AUDIO_IO_HANDLE_NONE) { mOutputRoutes.removeRoute(session); return INVALID_OPERATION; } return NO_ERROR; }
它首先根据各个参数来获取音频策略,然后根据音频策略选择输出设备,最后通过选择的设备选择一个合适的输出线程。前面的两个步骤在AudioPolicy中已经分析过了,所以我们重点来看一下getOutputForDevice这个函数
audio_io_handle_t AudioPolicyManager::getOutputForDevice( audio_devices_t device, audio_session_t session __unused, audio_stream_type_t stream, uint32_t samplingRate, audio_format_t format, audio_channel_mask_t channelMask, audio_output_flags_t flags, const audio_offload_info_t *offloadInfo) { audio_io_handle_t output = AUDIO_IO_HANDLE_NONE; uint32_t latency = 0; status_t status; ...... //最终会调用AudioFlinger::openOutput,返回一个输出线程保存在output变量中 status = mpClientInterface->openOutput(profile->getModuleHandle(), &output, &config, &outputDesc->mDevice, String8(""), &outputDesc->mLatency, outputDesc->mFlags); ...... ALOGV(" getOutputForDevice() returns output %d", output); //返回前面获得的output return output; }
紧接着跟踪进去看一下AudioFlinger::openOutput这个函数
status_t AudioFlinger::openOutput(audio_module_handle_t module, audio_io_handle_t *output, audio_config_t *config, audio_devices_t *devices, const String8& address, uint32_t *latencyMs, audio_output_flags_t flags) { ALOGI("openOutput(), module %d Device %x, SamplingRate %d, Format %#08x, Channels %x, flags %x", module, (devices != NULL) ? *devices : 0, config->sample_rate, config->format, config->channel_mask, flags); if (*devices == AUDIO_DEVICE_NONE) { return BAD_VALUE; } Mutex::Autolock _l(mLock); sp<PlaybackThread> thread = openOutput_l(module, output, config, *devices, address, flags); if (thread != 0) { *latencyMs = thread->latency(); // notify client processes of the new output creation thread->ioConfigChanged(AUDIO_OUTPUT_OPENED); // the first primary output opened designates the primary hw device if ((mPrimaryHardwareDev == NULL) && (flags & AUDIO_OUTPUT_FLAG_PRIMARY)) { ALOGI("Using module %d has the primary audio interface", module); mPrimaryHardwareDev = thread->getOutput()->audioHwDev; AutoMutex lock(mHardwareLock); mHardwareStatus = AUDIO_HW_SET_MODE; mPrimaryHardwareDev->hwDevice()->set_mode(mPrimaryHardwareDev->hwDevice(), mMode); mHardwareStatus = AUDIO_HW_IDLE; } return NO_ERROR; } return NO_INIT; }
它具体的创建PlaybackThread是在openOutput_l函数中完成的
//输入参数中的module是由前面loadNodule来获得的,它是一个audio interface的id号 //可以通过此id在mAudioHwSevs中查找对应的AudioHwDevice对象 //这个方法中会将打开的output加到mPlaybackThreads线程中 sp<AudioFlinger::PlaybackThread> AudioFlinger::openOutput_l(audio_module_handle_t module, audio_io_handle_t *output, audio_config_t *config, audio_devices_t devices, const String8& address, audio_output_flags_t flags) { //1.查找相应的audio interface AudioHwDevice *outHwDev = findSuitableHwDev_l(module, devices); if (outHwDev == NULL) { return 0; } audio_hw_device_t *hwDevHal = outHwDev->hwDevice(); if (*output == AUDIO_IO_HANDLE_NONE) { *output = nextUniqueId(); } mHardwareStatus = AUDIO_HW_OUTPUT_OPEN; // FOR TESTING ONLY: // This if statement allows overriding the audio policy settings // and forcing a specific format or channel mask to the HAL/Sink device for testing. if (!(flags & (AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD | AUDIO_OUTPUT_FLAG_DIRECT))) { // Check only for Normal Mixing mode if (kEnableExtendedPrecision) { // Specify format (uncomment one below to choose) //config->format = AUDIO_FORMAT_PCM_FLOAT; //config->format = AUDIO_FORMAT_PCM_24_BIT_PACKED; //config->format = AUDIO_FORMAT_PCM_32_BIT; //config->format = AUDIO_FORMAT_PCM_8_24_BIT; // ALOGV("openOutput_l() upgrading format to %#08x", config->format); } if (kEnableExtendedChannels) { // Specify channel mask (uncomment one below to choose) //config->channel_mask = audio_channel_out_mask_from_count(4); // for USB 4ch //config->channel_mask = audio_channel_mask_from_representation_and_bits( // AUDIO_CHANNEL_REPRESENTATION_INDEX, (1 << 4) - 1); // another 4ch example } } AudioStreamOut *outputStream = NULL; //2.为设备打开一个输出流,创建Audio HAL的音频输出对象 status_t status = outHwDev->openOutputStream( &outputStream, *output, devices, flags, config, address.string()); mHardwareStatus = AUDIO_HW_IDLE; //3. 根据标志不同创建不同的playbackThread if (status == NO_ERROR) { PlaybackThread *thread; if (flags & AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD) { thread = new OffloadThread(this, outputStream, *output, devices, mSystemReady); ALOGV("openOutput_l() created offload output: ID %d thread %p", *output, thread); } else if ((flags & AUDIO_OUTPUT_FLAG_DIRECT) || !isValidPcmSinkFormat(config->format) || !isValidPcmSinkChannelMask(config->channel_mask)) { thread = new DirectOutputThread(this, outputStream, *output, devices, mSystemReady); ALOGV("openOutput_l() created direct output: ID %d thread %p", *output, thread); } else { //一般是创建混音线程,代表AudioStreamOut对象的output也传递进去了 thread = new MixerThread(this, outputStream, *output, devices, mSystemReady); ALOGV("openOutput_l() created mixer output: ID %d thread %p", *output, thread); } mPlaybackThreads.add(*output, thread);//添加播放线程 return thread; } return 0; }
第一步AudioFlinge会判断是否有合适的HAL interface(primary、a2dp等)已经被加载了,如果没有加载就去加载它,如果加载了就直接使用。第二步openOutputStream最终会调用到hal层的open_output_stream,主要是配置输出PCM设备的一些参数,第三步是去创建PlaybackThread,这里我们具体去分析PlaybackThread是怎么被创建出来的。创建MixerThread的主要流程如下图所示。
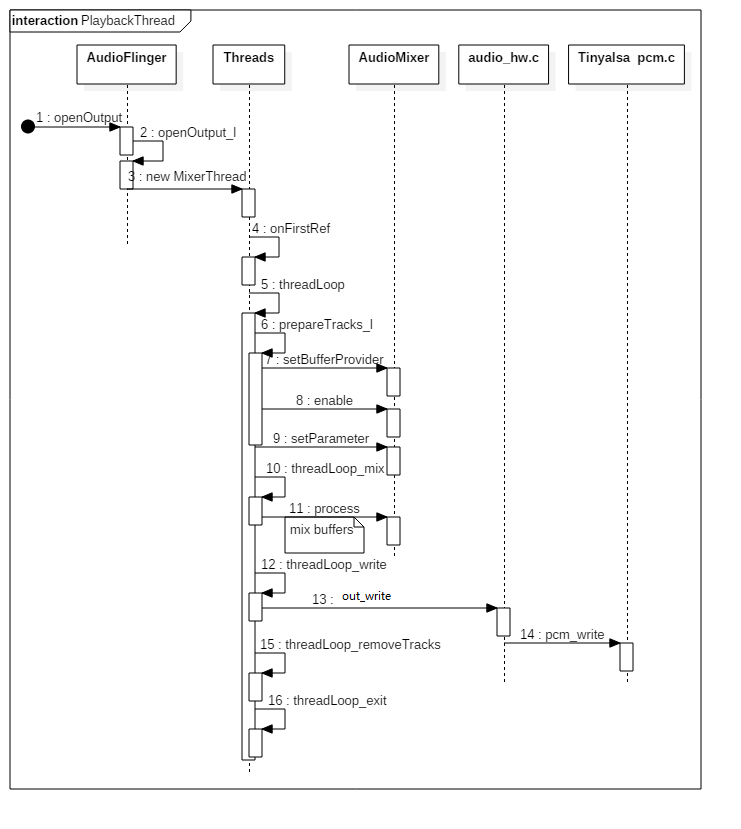
MixerThread在第一次被引用时进入到threadLoop()函数中下面看他做了哪些事
bool AudioFlinger::PlaybackThread::threadLoop() { ...... //准备音频数据 mMixerStatus = prepareTracks_l(&tracksToRemove); //音频数据准备就绪,开始混音 ...... hreadLoop_mix(); ...... //将混音好的数据传递到Audio HAL ret = threadLoop_write(); ...... }
下面我们进入到prepareTracks_l看一下是怎样准备音频数据的
AudioFlinger::MixerThread::prepareTracks_l( Vector< sp<Track> > *tracksToRemove) { ...... //当前活跃的track数量 size_t count = mActiveTracks.size(); ...... //循环处理每一个track for (size_t i=0 ; i<count ; i++) ...... //FastTrack下的处理 if (track->isFastTrack()) ...... //数据块准备 audio_track_cblk_t* cblk = track->cblk(); ........ //为混音器设置BufferProvider和一些参数 mAudioMixer->setBufferProvider(name, track); mAudioMixer->enable(name); mAudioMixer->setParameter(name, param, AudioMixer::VOLUME0, &vlf); ...... }
下面我们回到AudioFlinger::PlaybackThread::threadLoop()函数中进入hreadLoop_mix()函数中看一下音频数据准备好之后AudioMixer是怎样进行混音的
void AudioFlinger::MixerThread::threadLoop_mix() { ...... // mix buffers... mAudioMixer->process(pts); ...... }
进入到AudioMixe::process()函数中
void AudioMixer::process(int64_t pts) { mState.hook(&mState, pts); }
这里面只有一行代码,就是调用了mState.hook,mState是一个state_t结构体类型的变量,state_t结构定义在AudioMixer.h中
typedef void (*process_hook_t)(state_t* state, int64_t pts); // pad to 32-bytes to fill cache line struct state_t { uint32_t enabledTracks; uint32_t needsChanged; size_t frameCount; process_hook_t hook; // one of process__*, never NULL int32_t *outputTemp; int32_t *resampleTemp; NBLog::Writer* mLog; int32_t reserved[1]; track_t tracks[MAX_NUM_TRACKS] __attribute__((aligned(32))); };
可以看出hook是一个函数指针,我们就是通过这个函数指针指向的函数来处理音频数据的,它有好几种实现
process__calidate:根据当前的具体情况,进一步将hook导向下面几个函数
process__OneTrack16BitsStereoNoResampling:只有一路Track,16比特立体声,不重采样
process__GenericNoResampling:两路(包含)以上Track不重采样
process__GenericResampling:两路(包含)以上Track重采样
......
AudioMixer::process是外部程序调用hook的入口
下面我们以process_NoResampleOneTrack为例进行分析
void AudioMixer::process_NoResampleOneTrack(state_t* state, int64_t pts) { ....... t->bufferProvider->getNextBuffer(&b, outputPTS); ...... t->bufferProvider->releaseBuffer(&b); ...... }
上面的的BufferProvider是上面MixerThread::prepareTracks_l函数中我们为AudioMixter设置参数传进来的
mAudioMixer->setBufferProvider(name, track);
下面我们来分析一下BufferProvider::getNextBuffer函数的实现
status_t CopyBufferProvider::getNextBuffer(AudioBufferProvider::Buffer *pBuffer, int64_t pts) { ...... status_t res = mTrackBufferProvider->getNextBuffer(&mBuffer, pts); ...... }
它调用了Track::getNextBuffer继续来分析
status_t AudioFlinger::PlaybackThread::Track::getNextBuffer( AudioBufferProvider::Buffer* buffer, int64_t pts __unused) { ServerProxy::Buffer buf; size_t desiredFrames = buffer->frameCount; buf.mFrameCount = desiredFrames; status_t status = mServerProxy->obtainBuffer(&buf); buffer->frameCount = buf.mFrameCount; buffer->raw = buf.mRaw; if (buf.mFrameCount == 0) { mAudioTrackServerProxy->tallyUnderrunFrames(desiredFrames); } return status; }
它调用了ServerProxy::obtainBuffer,ServerProxy::obtainBuffer和调用AudioTrack::write的时候调用到的ClientProxy::obtainBuffer是相似的。ServerProxy::releaseBuffer和ClientProxy::releaseBuffer也是类似的,AudioTrack和AudioFlinger通过mCblkMemory这块内存来实现“生产者-消费者”数据交互,下面我们来分析一下ServerProxy和ClientProxy通过共享内存进行数据交互的原理。
创建 track 的时候,AudioFlinger 会给每个 track 分配 audio 共享 buffer,AudioTrack、AudioFlinger 以该buffer 为参数通过 AudioTrackClientProxy、AudioTrackServerProxy 创建 mClientProxy、mServerProxy。AudioTrack( client 端)通过 mClientProxy 向共享 buffer 写入数据, AudioFlinger(server 端)通过 mServerProxy 从共享 buffer 读出数据。这样 client、server 通过 proxy 对共享 buffer 形成了生产者、消费者模型。AudioTrackClientProxy、AudioTrackServerProxy( 这两个类都位于 AudioTrackShared.cpp )分别封装了 client 端、server 端共享 buffer 的使用方法 obtainBuffer 和 releaseBuffer,这些接口的功能如下:
Client 端:
AudioTrackClientProxy:: obtainBuffer()从 audio buffer 获取连续的 empty buffer;
AudioTrackClientProxy:: releaseBuffer ()将填充了数据的 buffer 放回 audio buffer。
Server 端:
AudioTrackServerProxy:: obtainBuffer()从 audio buffer 获取连续的填充了数据的 buffer;
AudioTrackServerProxy:: releaseBuffer ()将使用完的 empty buffer 放回 audio buffer。
2.2.开始播放
上面应用层开始播放PCM数据是通过调用AudioTrack的play方法来实现的,它的主要流程如下图所示。

它经过层层的调用,最终调用到了AudioPolicyManager的startOutput函数,这个在学习AudioPolicy的时候分析过了,所以先跳过。
2.3.往AudioTrack中写数据
在调用了AudioTrack的play函数开始播放PCM音频数据之后,我们会调用AudioTrack的write函数来向AudioTrack中写数据。它的主要流程如下图所示。

我们直接分析native层AudioTrack的write函数。
ssize_t AudioTrack::write(const void* buffer, size_t userSize, bool blocking) { if (mTransfer != TRANSFER_SYNC || mIsTimed) { return INVALID_OPERATION; }//STATIC模式下,数据是一次就写完的,不需要调用write ...... size_t written = 0; uffer audioBuffer; //写入数据 while (userSize >= mFrameSize) {//传过来的数据大小大于1帧数据 audioBuffer.frameCount = userSize / mFrameSize; status_t err = obtainBuffer(&audioBuffer, blocking ? &ClientProxy::kForever : &ClientProxy::kNonBlocking); //obtainBuffer出错 if (err < 0) { if (written > 0) { break; } return ssize_t(err); } size_t toWrite = audioBuffer.size; //内存复制 memcpy(audioBuffer.i8, buffer, toWrite); //指针跳过已写入的数据 buffer = ((const char *) buffer) + toWrite; //剩余的数据量 userSize -= toWrite; //已经写入的数据量 written += toWrite; //释放audioBuffer releaseBuffer(&audioBuffer); } return written }
首先我们需要使用obtainBuffer来获取目标区的写入地址下面我们来分析一下它具体是怎样实现的:
status_t AudioTrack::obtainBuffer(Buffer* audioBuffer, const struct timespec *requested, struct timespec *elapsed, size_t *nonContig) { ...... sp<AudioTrackClientProxy> proxy; sp<IMemory> iMem; ...... // Keep the extra references proxy = mProxy; iMem = mCblkMemory; status = proxy->obtainBuffer(&buffer, requested, elapsed); }
从上面代码可以发现其调用了AudioTrackClientProxy::obtainBuffer所以我们进入到AudioTrackClientProxy::obtainBuffer分析其获取buffer的步骤
// frameworks/av/media/libmedia/AudioTrackShared.cpp*/ status_t ClientProxy::obtainBuffer(Buffer* buffer, const struct timespec *requested, struct timespec *elapsed) { ...... //step1:获取 audio 共享 buffer 的读写指针 rear,front //由于读指针 front 在 AudioFlinger 端也会被操作 //这里调用 android_atomic_acquire_load 接口获取,该接口采用了内存屏障技术, //实现共享变量的读写同步访问; front = android_atomic_acquire_load(&cblk->u.mStreaming.mFront); rear = cblk->u.mStreaming.mRear; ...... //step2:计算出当前 buffer 中可用的 empty buffer 数量; size_t avail = mIsOut ? mFrameCount - filled : filled; ...... //step3:rear &= mFrameCountP2 – 1,计算出写指针 rear 在 buffer 中的真实偏移量; //part1 = mFrameCountP2 – rear,计算出从写指针开始 buffer 最大的连续地址长度 rear &= mFrameCountP2 - 1; part1 = mFrameCountP2 - rear; ...... //step4最大连续地址长度大于可用 empty buffer 值时,将其值修正为 empty buffer 值,这种情况说明所有可用 //的 empty buffer 都是地址连续的;然后再将 part1 与要求的 buffer 数量比较,大于要 求数量,则修正其 //值为要求的 buffer 数量,这种情况说明在本次操作中能完全满足要求,一次性完成 if (part1 > avail) { part1 = avail; } //step5填 充 buffer->mFrameCount ( 实 际 获 取 的 buffer 数 量 ), buffer->mRaw ( buffer 的 起 始 指 针 ), //buffer->mNonContig(未使用的不连续 empty buffer 数量),mUnreleased(需要释放的 buffer 数量,在releaseBuffer 中释放) buffer->mFrameCount = part1; buffer->mRaw = part1 > 0 ? &((char *) mBuffers)[(mIsOut ? rear : front) * mFrameSize] : NULL; buffer->mNonContig = avail - part1; mUnreleased = part1; ...... }
在申请完buffer并填充完音频数据之后我们需要释放buffer以供AudioFlinger获取并提取其中的音频数据信息,这个步骤是通过调用releaseBuffer来实现的,下面我们就来分析一下具体的实现方式。
void AudioTrack::releaseBuffer(const Buffer* audioBuffer) { ...... Proxy::Buffer buffer; buffer.mFrameCount = stepCount; buffer.mRaw = audioBuffer->raw; mProxy->releaseBuffer(&buffer); }
可见,和obtainBuffer一样也是通过调用AudioTrackClientProxy::releaseBuffer来实现的,下面就来分析AudioTrackClientProxy::releaseBuffer
proxy->obtainBuffervoid ClientProxy::releaseBuffer(Buffer* buffer) { ...... size_t stepCount = buffer->mFrameCount; ...... mUnreleased -= stepCount; audio_track_cblk_t* cblk = mCblk; if (mIsOut) { int32_t rear = cblk->u.mStreaming.mRear; android_atomic_release_store(stepCount + rear, &cblk->u.mStreaming.mRear); } }
该接口很简单,stepCount = buffer->mFrameCount,获取需要释放的 buffer 数量,然后获取写指针 rear,调用android_atomic_release_store 更新 rear
AudioTrack和AudioFlinger通过mCblkMemory这块内存来实现“生产者-消费者”数据交互,AudioTrack将音频数据写入到共享内存中,下AudioFlinger将音频数据从共享内存中读取出来的。