今天查询sqlite的时候需要不区分大小写,查了下文档,需要使用collate nocase.顺便学习下collate的用法。
collate在sql中是用来定义排序规则的。排序规则其实就是当比较两个字符串时,根据某种规则来确定哪个比较大,是否相等。各个数据库支持不同的排序规则。
sqlite有三种build in的排序规则:
| BINARY | 二进制比较,直接使用memcmp()比较 |
| NOCASE | 将26个大写字母转换为小写字母后进行与BINARY一样的比较 |
| RTRIM | 和BINARY一样,忽略结尾的空格 |
Sql server则比较复杂: 根据MSDN官方解释 排序规则指定了表示每个字符的位模式。它还指定了用于排序和比较字符的规则。
排序规则具有下面的特征: 区分语言,区分大小写,区分重音,区分假名
看一下SqlServer中的截图:
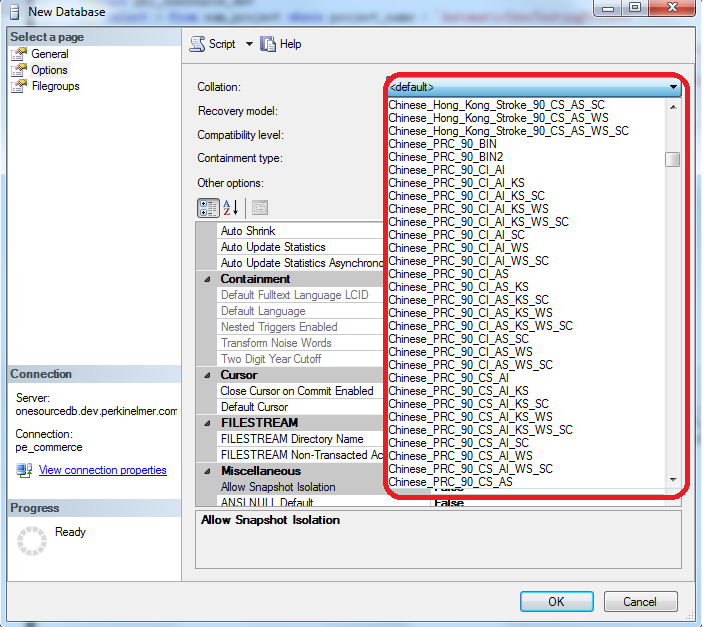
collate的名字包括两部分,前部分是表示字符集,后部分定义如下:
| _BIN | 指定使用向后兼容的二进制排序顺序。 |
| _BIN2 | 指定使用 SQL Server 2005 中引入的码位比较语义的二进制排序顺序。 |
| _Stroke | 按笔划排序 |
| _CI(CS) | 是否区分大小写,CI不区分,CS区分 |
| _AI(AS) | 是否区分重音,AI不区分,AS区分 |
| _KI(KS) | 是否区分假名类型,KI不区分,KS区分 |
| _WI(WS) | 是否区分全半角,WI不区分,WS区分 |
还可以根据拼音,笔画来排序。
如何设置排序规则
可以在数据库(create database/alter database时指定),字段级别(create table/alter table时指定)使用Collate命令设置collate,字段级别优先级更高。