题目1 ID88

给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 num1 成为一个有序数组。
说明:
初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。
你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。
示例:
输入:
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
我的解答:
因为是有序数组,所以我们可以用nums2挨个进行比较,如果是比nums1当前小的数字,就将nums1当前位以及后面的全部后移,插入数字,如果是比nums1当前大的数字则比较下一位nums1数字,依次类推。如果nums1结束了而nums2没结束,就把剩下的nums2全部放在nums1末尾。但是这样的缺点在于移位需要时间,更好的办法是直接从后往前比较,相比之下更大的数字就放在后面的位置,减少了读写的消耗(双100的执行结果)。另外还有一种办法是先将num1和num2写在同一个数组里(因为num1有足够大的空间),然后从小到大排序即可,比较容易理解的做法。
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n){
int i=m-1,j=n-1,k=m+n-1;
while(j>=0&&i>=0){
if(nums1[i]>nums2[j]){
nums1[k--]=nums1[i--];
}else{
nums1[k--]=nums2[j--];
}
}
while(j>=0){
nums1[k--]=nums2[j--];
}
return nums1;
}
题目2 ID326

给定一个整数,写一个函数来判断它是否是 3 的幂次方。
示例 1:
输入: 27
输出: true
示例 2:
输入: 0
输出: false
示例 3:
输入: 9
输出: true
示例 4:
输入: 45
输出: false
进阶:
你能不使用循环或者递归来完成本题吗?
我的解答:
上次做过一个4的幂的题目,用同样的方法做一遍,复习一下,因为测试数据的原因,e的精度要提高
bool isPowerOfThree(int n){
if(n==0){
return false;
}
double x=log((double)n)/log(3.0);
double e=1e-12;
int ifloor=floor(x),iceil=ceil(x);
if(x-ifloor<e||iceil-x<e){
return true;
}
return false;
}
题目3 ID面试题11

把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。
示例 1:
输入:[3,4,5,1,2]
输出:1
示例 2:
输入:[2,2,2,0,1]
输出:0
注意:本题与主站 154 题相同:https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array-ii/
我的解答:
第一反应是找数组里面最小值,心想为什么题目还写这么复杂
int minArray(int* numbers, int numbersSize){
if(numbersSize==0){
return ;
}
if(numbersSize==1){
return numbers[0];
}
int num=numbers[0],i;
for(i=1;i<numbersSize;i++){
if(numbers[i]<num){
num=numbers[i];
}
}
return num;
}
应该是运气好吧
很明显这个问题本意并不是想让我们用这种时间复杂度为O(n)的方式做出来,然后去学习理解了题解里面的一些做法。因为题目使用的是排序的旋转数组,所以在旋转了之后数组分为了两部分,这两部分都是递增的数组,比如说
Numbers[3,4,5,1,2],第一部分的递增数组是[3,4,5],第二部分的递增数组是[1,2],同时我们也可以看出,第一部分递增数组里面的数任何一个都是大于第二部分递增数组里面的数的,而最小值在数组旋转了之后永远存在于第二部分的递增数组里面,是第二部分递增数组的第一位。
所以我们用二分查找的方式,使用mid为中间值,low和high为两端的值。
当numbers[mid]>numbers[high]的时候,可知numbers[mid]是存在于第一部分的递增数组中,逆向思考如果numbers[mid]存在于第二部分的数组中,由于第二部分的数组是递增的,所以numbers[high]应当是其中的最大值,这就与numbers[mid]>numbers[high]矛盾,故numbers[mid]一定是在第一部分数组中,所以最小值是在mid的右边,low=mid+1
当numbers[mid]==numbers[high]的时候,这个时候我们不能确定最小值的范围是在左边还是右边,但不管mid是在左边部分还是右边部分,numbers[high]都不会是最小值,所以我们让high-1,缩小范围继续判断
当numbers[mid]<numbers[high]的时候,证明mid是在第二部分的递增数列中,所以最小值是在mid的左边,令high=mid
因为low=mid+1,所以我们最后返回numbers[low]就是最小值。
int minArray(int* numbers, int numbersSize){
if(numbersSize==0){
return ;
}
if(numbersSize==1){
return numbers[0];
}
int low=0,high=numbersSize-1;
int mid=(low+high)/2;
while(low<high){
mid=(low+high)/2;
if(numbers[mid]>numbers[high]){
low=mid+1;
}else if(numbers[mid]==numbers[high]){
high--;
}else{
high=mid;
}
}
return numbers[low];
}
题目4 ID141

给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
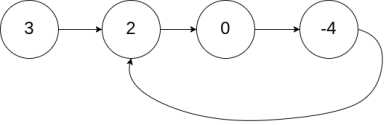
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
进阶:
你能用 O(1)(即,常量)内存解决此问题吗?
我的解答:
题目描述的不是很清楚,因为在输入的测试数据里面没有输入pos,其实就是给我们一个链表,判断是否是环形链表
这里用到的方法是快慢指针,可以理解为一个赛道上有两位速度不同的选手在跑步,如果这个赛道是环形的,那么跑的快的选手总会跟跑的慢的选手再次相遇,而如果不是环形的,那么跑的快的选手就会先到终点,以此编写代码判断环形链表
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head) {
if(head==NULL||head->next==NULL){
return false;
}
struct ListNode* slow=head;
struct ListNode* fast=head;
while(fast!=NULL&&fast->next!=NULL){
slow=slow->next;
fast=fast->next->next;
if(slow==fast){
return true;
}
}
return false;
}
题目5 ID1175

请你帮忙给从 1 到 n 的数设计排列方案,使得所有的「质数」都应该被放在「质数索引」(索引从 1 开始)上;你需要返回可能的方案总数。
让我们一起来回顾一下「质数」:质数一定是大于 1 的,并且不能用两个小于它的正整数的乘积来表示。
由于答案可能会很大,所以请你返回答案 模 mod 10^9 + 7 之后的结果即可。
示例 1:
输入:n = 5
输出:12
解释:举个例子,[1,2,5,4,3] 是一个有效的排列,但 [5,2,3,4,1] 不是,因为在第二种情况里质数 5 被错误地放在索引为 1 的位置上。
示例 2:
输入:n = 100
输出:682289015
提示:
1 <= n <= 100
我的解答:
提示里面提示了n的最大值是100,在有限的范围同时数字不是很大的情况下可以选择暴力打表做题。
正常做法是理解了题意之后,求出质数的个数,再求非质数的个数,然后两个全排列之后相乘,就是质数排列的数量,由于返回的数字会很大,所以我最开始调用函数返回int型结果报错了。
int check(int num){
int i;
if(num==1){
return false;
}
if(num==2){
return true;
}
for(i=2;i<=num/2;i++){
if(num%i==0){
return false;
}
}
return true;
}
int pailie(int num){
if(num==1){
return 1;
}else{
return pailie(num-1)*num;
}
}
int numPrimeArrangements(int n){
int isPrinum=0;
int i;
for(i=1;i<=n;i++){
if(check(i)){
isPrinum++;
}
}
int isnPrinum=n-isPrinum;
return (pailie(isPrinum)*pailie(isnPrinum))%(1000000007);
}
不仅返回int型报错了,而且递归算全排列,虽然看上去代码很清晰简洁,但是运行的时候很消耗内存,修改为:
int check(int num){
int i;
if(num==1){
return false;
}
if(num==2){
return true;
}
for(i=2;i<=num/2;i++){
if(num%i==0){
return false;
}
}
return true;
}
int numPrimeArrangements(int n){
int isPrinum=0;
int i;
for(i=1;i<=n;i++){
if(check(i)){
isPrinum++;
}
}
int isnPrinum=n-isPrinum;
long isum=1,nsum=1;
for(i=1;i<=isPrinum;i++){
isum=(isum*i)%(1000000007);
}
for(i=1;i<=isnPrinum;i++){
nsum=(nsum*i)%(1000000007);
}
return (isum*nsum)%(1000000007);
}
题目6 ID830

在一个由小写字母构成的字符串 S 中,包含由一些连续的相同字符所构成的分组。
例如,在字符串 S = "abbxxxxzyy" 中,就含有 "a", "bb", "xxxx", "z" 和 "yy" 这样的一些分组。
我们称所有包含大于或等于三个连续字符的分组为较大分组。找到每一个较大分组的起始和终止位置。
最终结果按照字典顺序输出。
示例 1:
输入: "abbxxxxzzy"
输出: [[3,6]]
解释: "xxxx" 是一个起始于 3 且终止于 6 的较大分组。
示例 2:
输入: "abc"
输出: []
解释: "a","b" 和 "c" 均不是符合要求的较大分组。
示例 3:
输入: "abcdddeeeeaabbbcd"
输出: [[3,5],[6,9],[12,14]]
我的解答:
比较简单的题目,但是C语言链表分配空间弄了几次都报错了,就改用python来做这道题目
只要当前数字跟前一个数字是相同的,我们令flag+1,当遇到不相等的时候,就检查flag>=3是否为真,将为真的结果添加到列表中,另外一种情况是一直没有遇到不相等的时候,比如”aaaa”这种,如果不加以处理的话,本应该输出[0,3],但是却会返回[]空列表,所以最后处理一下这种特殊情况就可以了。
class Solution(object): def largeGroupPositions(self, S): result=[] i,flag=0,1 if len(S)<3: return for i in range(1,len(S)): if S[i]==S[i-1]: if flag==1: start=i-1 flag+=1 else: if flag>=3: end=i-1 result.append([start,end]) start,end,flag=0,0,1 if flag>=3: end=i result.append([start,end]) return result """ :type S: str :rtype: List[List[int]] """
题目7 ID836

矩形以列表 [x1, y1, x2, y2] 的形式表示,其中 (x1, y1) 为左下角的坐标,(x2, y2) 是右上角的坐标。
如果相交的面积为正,则称两矩形重叠。需要明确的是,只在角或边接触的两个矩形不构成重叠。
给出两个矩形,判断它们是否重叠并返回结果。
示例 1:
输入:rec1 = [0,0,2,2], rec2 = [1,1,3,3]
输出:true
示例 2:
输入:rec1 = [0,0,1,1], rec2 = [1,0,2,1]
输出:false
说明:
两个矩形 rec1 和 rec2 都以含有四个整数的列表的形式给出。
矩形中的所有坐标都处于 -10^9 和 10^9 之间。
我的解答:
这道题目可以逆向思考,除了四种不重叠的情况,其余情况全部都是重叠的,如图:
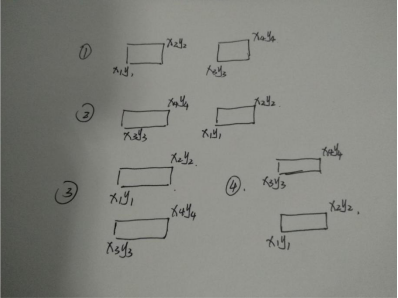
只有这四种情况任一出现时,才说明两个矩形没有重叠
bool isRectangleOverlap(int* rec1, int rec1Size, int* rec2, int rec2Size){
int x1=rec1[0],y1=rec1[1],x2=rec1[2],y2=rec1[3];
int x3=rec2[0],y3=rec2[1],x4=rec2[2],y4=rec2[3];
if(x2<=x3||x4<=x1||y4<=y1||y2<=y3){
return false;
}
return true;
}
题目8 ID203

删除链表中等于给定值 val 的所有节点。
示例:
输入: 1->2->6->3->4->5->6, val = 6输出: 1->2->3->4->5
我的解答:
练习对于链表的操作,删除节点有三种情况,第一种是需要删除的节点是头指针,第二种是删除中间节点,第三种是删除尾节点,第二种和第三种的操作方式是相同的,所以分两类情况进行代码编写
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* p=head,*q=NULL;
while(p&&head->val==val){
head=head->next;
p=head;
}
while(p){
while(p->next!=NULL&&p->next->val==val){
q=p->next;
p->next=p->next->next;
free(q);
}
p=p->next;
}
return head;
}
题目9 ID1290

给你一个单链表的引用结点 head。链表中每个结点的值不是 0 就是 1。已知此链表是一个整数数字的二进制表示形式。
请你返回该链表所表示数字的 十进制值 。
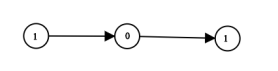
示例 1:
输入:head = [1,0,1]
输出:5
解释:二进制数 (101) 转化为十进制数 (5)
示例 2:
输入:head = [0]
输出:0
示例 3:
输入:head = [1]
输出:1
示例 4:
输入:head = [1,0,0,1,0,0,1,1,1,0,0,0,0,0,0]
输出:18880
示例 5:
输入:head = [0,0]
输出:0
提示:
链表不为空。
链表的结点总数不超过 30。
每个结点的值不是 0 就是 1。
我的解答:
专门训练自己对于链表的操作,这道题目很简单,按照二进制转十进制的规则就可以了,我们先遍历一遍链表求链表长度,再从头结点开始计算
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
int getDecimalValue(struct ListNode* head){
int length=0;
struct ListNode* p=head;
while(p){
length++;
p=p->next;
}
p=head;
int num=0;
while(p){
if(p->val==1){
num+=pow(2,length-1);
}
p=p->next;
length--;
}
return num;
}
题目10 ID237

请编写一个函数,使其可以删除某个链表中给定的(非末尾)节点,你将只被给定要求被删除的节点。
现有一个链表 -- head = [4,5,1,9],它可以表示为:

示例 1:
输入: head = [4,5,1,9], node = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
示例 2:
输入: head = [4,5,1,9], node = 1
输出: [4,5,9]
解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.
说明:
链表至少包含两个节点。
链表中所有节点的值都是唯一的。
给定的节点为非末尾节点并且一定是链表中的一个有效节点。
不要从你的函数中返回任何结果。
我的解答:
很有意思的题目,我们平时删除链表中的节点需要知道该节点上一个节点,然后将我们需要删除的节点删除,这道题反其道为之,只给了我们需要删除节点的地址,仔细观察题目可以看到题目里面告诉了我们这是非尾结点,也就是当前需要删除的节点后面一定还是有节点的。在无法找到上一个节点的情况下,我们能控制的只有当前节点和以后的节点,所以将当前节点的值替换成下一个节点的值,删除掉下一个节点即可,虽然当前节点实际上没有真正删除,但是却能够达到题目的要求
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
void deleteNode(struct ListNode* node) {
node->val=node->next->val;
node->next=node->next->next;
}
题目11 ID面试题22

输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。例如,一个链表有6个节点,从头节点开始,它们的值依次是1、2、3、4、5、6。这个链表的倒数第3个节点是值为4的节点。
示例:
给定一个链表: 1->2->3->4->5, 和 k = 2.
返回链表 4->5.
我的解答:
先遍历链表得到长度,再减去k得到正向的顺序,遍历链表,到达该输出的节点退出循环
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* getKthFromEnd(struct ListNode* head, int k){
struct ListNode* p=head,* s=NULL;
int length=0;
while(p){
length++;
p=p->next;
}
//length=5,q=3
int q=length-k+1,i=1;
p=head;
while(p){
if(i==q){
s=p;
break;
}
i++;
p=p->next;
}
return s;
}
题目12 ID面试题06

输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
示例 1:
输入:head = [1,3,2]
输出:[2,3,1]
限制:
0 <= 链表长度 <= 10000
我的解答:
先对链表进行反转,然后将每一个值赋给数组即可
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* reversePrint(struct ListNode* head, int* returnSize){
struct ListNode*p=head,*q=NULL,*s=NULL;
int length=0;
while(head){
p=head;
head=p->next;
p->next=q;
q=p;
length++;
}
head=p;
int* nums=(int*)malloc(sizeof(int)*length);
int i;
for(i=0;i<length;i++){
nums[i]=head->val;
head=head->next;
}
*returnSize=length;
return nums;
}
题目13 ID328

给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。
请尝试使用原地算法完成。你的算法的空间复杂度应为 O(1),时间复杂度应为 O(nodes),nodes 为节点总数。
示例 1:
输入: 1->2->3->4->5->NULL
输出: 1->3->5->2->4->NULL
示例 2:
输入: 2->1->3->5->6->4->7->NULL
输出: 2->3->6->7->1->5->4->NULL
说明:
应当保持奇数节点和偶数节点的相对顺序。
链表的第一个节点视为奇数节点,第二个节点视为偶数节点,以此类推。
我的解答:
一个原地算法(in-place algorithm)是一种使用小的,固定数量的额外之空间来转换资料的算法。 当算法执行时,输入的资料通常会被要输出的部份覆盖掉。就用正常想法,分别读取奇数节点和偶数节点,然后将偶数节点连接在奇数节点后面
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* oddEvenList(struct ListNode* head){
if(head==NULL){
return ;
}
struct ListNode* Odd=head,* OddNode=Odd;
struct ListNode* Even=head->next,* EvenNode=Even;
while(Even&&Even->next){
Odd->next=Odd->next->next;
Even->next=Even->next->next;
Odd=Odd->next;
Even=Even->next;
}
Odd->next=EvenNode;
return OddNode;
}
题目14 ID86

给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前。
你应当保留两个分区中每个节点的初始相对位置。
示例:
输入: head = 1->4->3->2->5->2, x = 3
输出: 1->2->2->4->3->5
我的解答:
使用双指针分别储存两种条件下的链表,然后合并返回,需要注意的是因为我们是从one->next和two->next开始储存的,所以实际上one,two这两个指针的头结点里面没有储存数字,在合并的时候应当删除掉。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* partition(struct ListNode* head, int x){
struct ListNode* one=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* two=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* oneNode,* twoNode;
oneNode=one;
twoNode=two;
while(head){
if(head->val<x){
one->next=head;
one=one->next;
}else{
two->next=head;
two=two->next;
}
head=head->next;
}
two->next=NULL;
one->next=twoNode->next;
oneNode=oneNode->next;
return oneNode;
}
题目15 ID374

我们正在玩一个猜数字游戏。 游戏规则如下:
我从 1 到 n 选择一个数字。 你需要猜我选择了哪个数字。
每次你猜错了,我会告诉你这个数字是大了还是小了。
你调用一个预先定义好的接口 guess(int num),它会返回 3 个可能的结果(-1,1 或 0):
-1 : 我的数字比较小
1 : 我的数字比较大
0 : 恭喜!你猜对了!
示例 :
输入: n = 10, pick = 6
输出: 6
我的解答:
很简单的二分查找,双一百击败所有用户
/**
* Forward declaration of guess API.
* @param num your guess
* @return -1 if num is lower than the guess number
* 1 if num is higher than the guess number
* otherwise return 0
* int guess(int num);
*/
int guessNumber(int n){
long low=1,high=n;
long mid=(low+high)/2;
while(low<high){
mid=(low+high)/2;
switch(guess(mid)){
case -1:high=mid;break;
case 1:low=mid+1;break;
case 0:return mid;
}
}
return low;
}
题目16 ID198

你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。
示例 1:
输入: [1,2,3,1]
输出: 4
解释: 偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入: [2,7,9,3,1]
输出: 12
解释: 偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12
我的解答:
动态规划的典型例题,慢慢学习动态规划
因为不能偷相邻的房屋,为了方便思考,我们从左往右计算能够盗窃的最大金额,在不考虑临界点的情况下,我们想要我们到达当前这个房屋的时候偷窃金额是最大的,就需要经过前面的房屋的时候,所获取到的钱是最大的,所以到达当前的房屋时,才可以考虑更大的金额。而当前房屋金额是否是从左到当前位置盗窃最大金额,我们需要考虑当前房屋的金额是否加入总金额。比较相隔一个房屋的金额加上当前房屋的金额,和相邻房屋最大金额之间谁是最大的,最大的那个就是从左到当前房屋的盗窃金额最大值,依次到最后一个房屋,求得最大值。另外考虑一下初始化开始两个房屋的值即可。
举个例子:
给出的示例里面有[1,2,3,1]
可以看到到第一个房屋的时候,能够偷窃的最大值是1,即n=1,dp[0]=1;
到达第二个房屋的时候,能够偷窃的最大值是2,即n=2,dp[1]=max(nums[0],nums[1]);
到达第三个房屋的时候,可以有两种情况,即偷窃第一个房屋和第三个房屋,或者是只偷窃第二个房屋
n=3,dp[2]=max(dp[2]+dp[2-2],dp[1]);
所以可以总结出
动态规划方程为:f(k) = max(f(k – 2) + A(k), f(k – 1))
同时我们可以看出来我们需要初始化的值是dp[0]和dp[1],因为不初始化的话dp[i-2]就会无值。
重要的是分析过程,而不是代码:
int max(int a,int b){
return a>b?a:b;
}
int rob(int* nums, int numsSize){
if(numsSize==0){
return 0;
}
if(numsSize==1){
return nums[0];
}
int* dp=(int*)malloc(numsSize*sizeof(int));
dp[0]=nums[0];
dp[1]=max(dp[0],nums[1]);
int i;
for(i=2;i<numsSize;i++){
dp[i]=max(dp[i-2]+nums[i],dp[i-1]);
}
return dp[numsSize-1];
}
题目17 ID125

给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:本题中,我们将空字符串定义为有效的回文串。
示例 1:
输入: "A man, a plan, a canal: Panama"
输出: true
示例 2:
输入: "race a car"
输出: false
我的解答:
按照题目一步一步地来,我们从字符串两端开始检查,退出循环的条件是两端的哨兵相遇的时候。如果有字母不相同则返回false,如果是大写字母转成小写,小写字母和数字直接比较,其他字符直接跳过。
bool check(char* ch){
if(*ch>='0'&&*ch<='9'){
return true;
}
if(*ch>='a'&&*ch<='z'){
return true;
}
if(*ch>='A'&&*ch<='Z'){
*ch=32+*ch;
return true;
}
return false;
}
bool isPalindrome(char * s){
if(strlen(s)==0||strlen(s)==1){
return true;
}
int i=0,j=strlen(s)-1;
while(i<j){
while((i<j)&&!check(&s[i])){
i++;
}
while((i<j)&&!check(&s[j])){
j--;
}
if((i<j)&&s[i]!=s[j]){
return false;
}
i++;
j--;
}
return true;
}
题目17 ID559

给你一个由一些多米诺骨牌组成的列表 dominoes。
如果其中某一张多米诺骨牌可以通过旋转 0 度或 180 度得到另一张多米诺骨牌,我们就认为这两张牌是等价的。
形式上,dominoes[i] = [a, b] 和 dominoes[j] = [c, d] 等价的前提是 a==c 且 b==d,或是 a==d 且 b==c。
在 0 <= i < j < dominoes.length 的前提下,找出满足 dominoes[i] 和 dominoes[j] 等价的骨牌对 (i, j) 的数量。
示例:
输入:dominoes = [[1,2],[2,1],[3,4],[5,6]]
输出:1
提示:
1 <= dominoes.length <= 40000
1 <= dominoes[i][j] <= 9
我的解答:
很自然地想到暴力法,超时了
int numEquivDominoPairs(int** dominoes, int dominoesSize, int* dominoesColSize){
int i,j;
int count=0;
for(i=0;i<dominoesSize;i++){
for(j=i+1;j<dominoesSize;j++){
if(dominoes[i][0]==dominoes[j][1]&&dominoes[i][1]==dominoes[j][0]){
count++;
continue;
}
if(dominoes[i][0]==dominoes[j][0]&&dominoes[i][1]==dominoes[j][1]){
count++;
continue;
}
}
}
return count;
}
因为时间复杂度是O(n^2),时间复杂度过高,换一种做法,将每一个多米诺骨牌存进对应映射的数组里,比如说[1,2],我们存进数组下标为21的位置,因为[1,2]和[2,1]是等价的,所以[2,1]也存进数组下标为21的位置,如何做到这一点,我们只需要比较多米诺骨牌中更大的那个数字,令其成为十位,小的数字为个位即可。然后循环遍历映射的表,等价多米诺骨牌的数量等于出现次数>1的组合数C(2,n),再相加即是总数
int numEquivDominoPairs(int** dominoes, int dominoesSize, int* dominoesColSize){
int i,j;
int count=0;
int tmp=0;
int hash[100]={0};
for(i=0;i<dominoesSize;i++){
if(dominoes[i][0]>dominoes[i][1]){
hash[dominoes[i][0]*10+dominoes[i][1]]++;
}else{
hash[dominoes[i][1]*10+dominoes[i][0]]++;
}
}
for(i=0;i<100;i++){
if(hash[i]){
count+=(hash[i]*(hash[i]-1))/2;
}
}
return count;
}
题目18 ID290

给定一种规律 pattern 和一个字符串 str ,判断 str 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 str 中的每个非空单词之间存在着双向连接的对应规律。
示例1:
输入: pattern = "abba", str = "dog cat cat dog"
输出: true
示例 2:
输入:pattern = "abba", str = "dog cat cat fish"
输出: false
示例 3:
输入: pattern = "aaaa", str = "dog cat cat dog"
输出: false
示例 4:
输入: pattern = "abba", str = "dog dog dog dog"
输出: false
说明:
你可以假设 pattern 只包含小写字母, str 包含了由单个空格分隔的小写字母。
我的解答:
使用python来做这种字符串的题目,缩进的时候提交老是提示我有语法错误。从题目里面可以看出规则和字符串之间有强烈的映射关系,容易想到将字符串的映射关系储存起来,考虑到会有两种情况,第一种是该映射关系在储存的字典中没有,我们就添加这一映射关系,第二种情况是有,那么就检查当前出现的映射关系是否符合存在的映射关系。
class Solution(object):
def wordPattern(self, pattern, str):
"""
:type pattern: str
:type str: str
:rtype: bool
"""
test1={}
test2={}
length=len(pattern)
test_list=str.split()
if length!=len(test_list):
return False
for i in range(length):
if pattern[i] not in test1 and test_list[i] not in test2:
test1[pattern[i]]=test_list[i]
test2[test_list[i]]=pattern[i]
elif pattern[i] in test1 and test_list[i] in test2 and test1[pattern[i]]==test_list[i] and test2[test_list[i]]==pattern[i]:
pass
else:
return False
return True
题目19 ID441

你总共有 n 枚硬币,你需要将它们摆成一个阶梯形状,第 k 行就必须正好有 k 枚硬币。
给定一个数字 n,找出可形成完整阶梯行的总行数。
n 是一个非负整数,并且在32位有符号整型的范围内。
示例 1:
n = 5
硬币可排列成以下几行:
¤
¤ ¤
¤ ¤
因为第三行不完整,所以返回2.
示例 2:
n = 8
硬币可排列成以下几行:
¤
¤ ¤
¤ ¤ ¤
¤ ¤
因为第四行不完整,所以返回3.
我的解答:
为了防止超时尽量不使用递归来做这一类题目,分析题意后写出代码即可
int arrangeCoins(int n){
int i;
long num=0;
for(i=0;;i++){
num+=i;
if(num+(i+1)>n){
return i;
}
}
}
题目20 ID695

给定一个包含了一些 0 和 1的非空二维数组 grid , 一个 岛屿 是由四个方向 (水平或垂直) 的 1 (代表土地) 构成的组合。你可以假设二维矩阵的四个边缘都被水包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为0。)
示例 1:
[[0,0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,1,1,0,1,0,0,0,0,0,0,0,0],
[0,1,0,0,1,1,0,0,1,0,1,0,0],
[0,1,0,0,1,1,0,0,1,1,1,0,0],
[0,0,0,0,0,0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,0,0,0,0,0,0,1,1,0,0,0,0]]
对于上面这个给定矩阵应返回 6。注意答案不应该是11,因为岛屿只能包含水平或垂直的四个方向的‘1’。
示例 2:
[[0,0,0,0,0,0,0,0]]
对于上面这个给定的矩阵, 返回 0。
注意: 给定的矩阵grid 的长度和宽度都不超过 50。
我的解答:
岛屿最大面积,以前在《啊哈!算法》一书中的第四章里面遇到过这类题目,很经典的题目,要求最大的岛屿面积,我们遍历数组中的元素,当为1时,表明当前为陆地,将其置为-1,防止重复计算,并且从当前位置继续漫水填充,也就是对于当前位置上下左右四个方向的陆地进行感染,每一个被感染的位置又可以继续感染其他陆地,直到无法感染为止。接着将获得的岛屿面积与当前最大岛屿面积进行比较替换即可,代码挺清晰的,也可以直接看代码
int check(int x,int y,int** grid,int gridSize,int* gridColSize){
int next_step[4][2]={{0,1},{1,0},{0,-1},{-1,0}};
int i;
int sum=1;
for(i=0;i<4;i++){
int next_x=x+next_step[i][0];
int next_y=y+next_step[i][1];
if(next_x>=0&&next_x<gridSize&&next_y>=0&&next_y<gridColSize[x]&&grid[next_x][next_y]==1){
grid[next_x][next_y]=-1;
sum+=check(next_x,next_y,grid,gridSize,gridColSize);
}
}
return sum;
}
int maxAreaOfIsland(int** grid, int gridSize, int* gridColSize){
int i,j,num=0,sum=0;
for(i=0;i<gridSize;i++){
for(j=0;j<gridColSize[i];j++){
if(grid[i][j]==1){
grid[i][j]=-1;
num=check(i,j,grid,gridSize,gridColSize);
if(num>sum){
sum=num;
}
}
}
}
return sum;
}