scrapy登录界面的难点在于登录时候的验证码,我们通过使用scrapy.FormRequest向目标网站提交数据(表单提交),同时将验证码显示在本地,手动输入,进而登录。

验证码是类似于这种的,才可以通过此方式登录,如网站是通过滑块验证登录的话,此方法就不再适用
因为要找到这种验证码登录的网站一时之间没找到,本想用学校教务系统的登录网站进行测试,但是测试后发现验证码是动态加载的,故放弃,找了一会,就用提交教育漏洞的edusrc网站作为练习登录爬虫的站点
登录url是:https://src.sjtu.edu.cn/login/
我们先登录一下,查看需要post哪些数据

可以看到,这里POST表单里面我们提交了username,password,captcha_1,captcha_0以及csrfmiddlewaretoken
username和password是我们的登录邮箱和密码,captcha_1是输入的验证码,captcha_0我猜测是每次登录的时候都会根据网站算法而更新的一个值,csrfmiddlewaretoken也是一个根据算法更新的值,从名字可以看出是防止csrf攻击而生成的令牌值,告诉网站来到这个页面的用户的权限。
而提交的数据中,captcha_0和csrfmiddlewaretoken都是直接从页面中获取的,我们先用xpath从页面中获取这两个值


使用xpath语法对这两个值进行提取:
formdata={
'username': '',
'password': ''
}
captcha_0=response.xpath('//input[@name="captcha_0"]/@value').get()
formdata['captcha_0']=captcha_0
csrfmiddlewaretoken=response.xpath('//input[@name="csrfmiddlewaretoken"]/@value').get()
formdata['csrfmiddlewaretoken']=csrfmiddlewaretoken
其中username和password需要自己输入,这个时候就只剩下captcha_1即验证码没有获取了
查看源代码 之后可知:

验证码存在一个url,这个url里面的验证码每次刷新之后都会改变,但是url也在不断变化,使用xpath提取这个url,然后我们进一步进行处理
captcha_url = response.xpath('//img/@src').get()
captcha_url = 'https://src.sjtu.edu.cn/' + captcha_url
print captcha_url
captcha = self.check_captcha(captcha_url)
check_captcha函数就是我们用来处理captcha_url即验证码url的
def check_captcha(self,image_url):
urllib.urlretrieve(image_url,'captcha.jpg')
image=Image.open('captcha.jpg')
image.show()
captcha=raw_input('please input captcha:')
return captcha
我们使用了urlretrieve函数来下载远程url的数据,这里就是将验证码图片下载在了本地我们查看
python2和python3都可以使用urlretrieve函数,使用方法略有不同,我使用的是python2,参考这篇博客修改的:
https://blog.csdn.net/drdairen/article/details/61934598?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
获取到的验证码图片会保存在当前文件夹下,接着我们使用Image打开该图片同时show,看到验证码图片的我们关闭图片后输入验证码字符串并返回该字符串
formdata['captcha_1'] = captcha yield scrapy.FormRequest(url=self.login_url,formdata=formdata,callback=self.parse_after_login)
将captcha_1加入到formdata之后,我们向login_url提交formdata,同时为了检测我们是否成功登录,回调函数是parse_after_login
def parse_after_login(self,response):
if response.url=="https://src.sjtu.edu.cn/":
yield scrapy.FormRequest(self.bug_url,callback=self.parse_bug)
print "login successful!"
else:
print "login failed!"
自己尝试登录之后,可以知道登录了之后网站会自动将我们302重定向到https://src.sjtu.edu.cn/,所以我们只需要检测response.url是否跟https://src.sjtu.edu.cn/相同即可
我们登录了之后去bugurl即https://src.sjtu.edu.cn/list/?page=1页面第一页提取bug_list信息打印出来,证明可以做到登录之后的操作即可,因为为了避免信息泄露,漏洞列表里登录后和没登录看到的漏洞信息是不一样的,侧面可以反映我们是否登录成功
def parse_bug(self,response):
print response.url
if response.url==self.bug_url:
print "join bug_list successful!"
bug_list=response.xpath('//td/a[contains(@href,"/post/")]/text()').getall()
for bug in bug_list:
print bug
else:
print "join bug_list failed!"
现在主要的部分就写好了,填入username和password运行试试
运行之后跳出验证码图片

输入验证码之后输出第一页的漏洞列表:
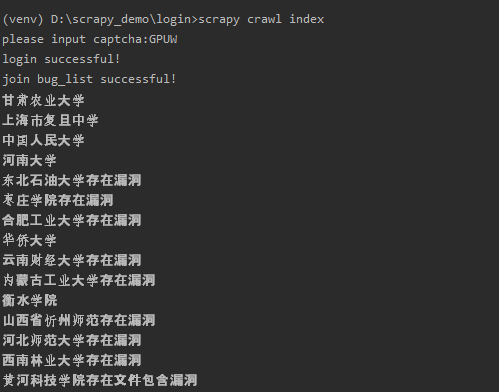
可以看到跟登录之后的漏洞信息显示相同
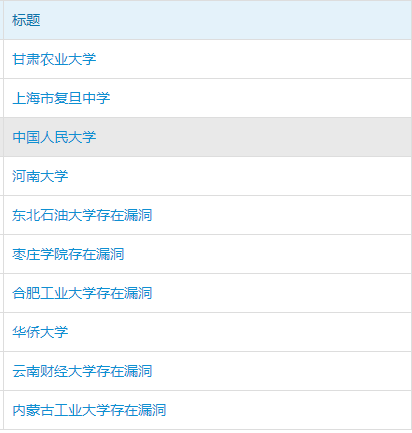
如果没登录的话,显示的信息是这样的:

其实我感觉没登录的时候看到的信息要多一些:)
可以看出我们登录成功了。
这个代码主要是识别验证码和POST提交formdata数据比较重要
代码放在github上面了:
https://github.com/Cl0udG0d/scrapy_demo
参考链接:
https://blog.csdn.net/drdairen/article/details/61934598?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task