爬取的目标网站是:
http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1
目的是爬取每一个教程的标题,作者,时间和详细内容
通过下面的命令可以快速创建 CrawlSpider模板 的代码:
scrapy genspider wsapp wxapp-union.com
CrawlSpider是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合。
在之前爬取免费代理的爬虫里面,我们没有使用crawlspider,当我们想要爬取下一页的时候,采用的是xpath解析response,找到下一页的链接,然后再次请求

但是这样的弊端在于难以灵活爬取网站,因此这里我们使用crawlspider来让爬取任务更简单。
CrawlSpider继承自Spider, 爬取网站常用的爬虫,其定义了一些规则(rule)方便追踪或者是过滤link。 也许该spider并不完全适合您的特定网站或项目,但其对很多情况都是适用的。 因此您可以以此为基础,修改其中的方法,当然您也可以实现自己的spider。
除了从Spider继承过来的(您必须提供的)属性外,其提供了一个新的属性:
- rules
一个包含一个(或多个) Rule 对象的集合(list)。 每个 Rule 对爬取网站的动作定义了特定表现。 Rule对象在下边会介绍。 如果多个rule匹配了相同的链接,则根据他们在本属性中被定义的顺序,第一个会被使用。
该spider也提供了一个可复写(overrideable)的方法:
- parse_start_url(response)
当start_url的请求返回时,该方法被调用。 该方法分析最初的返回值并必须返回一个 Item 对象或者 一个 Request 对象或者 一个可迭代的包含二者对象。
这里我们使用rules设置规则爬取我们需要的链接。
因为我们需要爬取教程,点击下一页之后发现网页链接的变化是page,即第一页到第二页的变化是page=1变成了page=2
/portal.php?mod=list&catid=2&page=1
如果有爬虫经验的话这里应该很容易理解
可以知道页数链接是在类似于list&catid=2&page=x这种格式的链接里面
接着我们查看每一页里面的每一篇文章的链接,比如:
http://www.wxapp-union.com/article-5798-1.html
可知教程的详情是在类似于article-xxx.html这种格式的链接里面
所以我们可以在rules里面编写这两条规则
rules = (
Rule(LinkExtractor(allow=r'.+list&catid=2&page=d+'), follow=True),
Rule(LinkExtractor(allow=r'.+article-.+.html'), callback='parse_detail', follow=False),
)
我们需要使用LinkExtractor和Rule这两个东西来决定爬虫的具体走向
需要注意的是:
1,allow设置规则的方法:要能够限制在我们想要的url上面,不是和其他url产生相同的正则表达式即可
在我们这里设置的rules里面,使用 .+来匹配任意字符,d+来匹配page后面的数字
2,什么情况下使用follow:如果在爬取页面的时候,需要将满足当前条件的url在进行跟进,那么就设置为Ture,否则设置为False
在我们的这个例子里面,对于这个界面,我们选择了跟进:
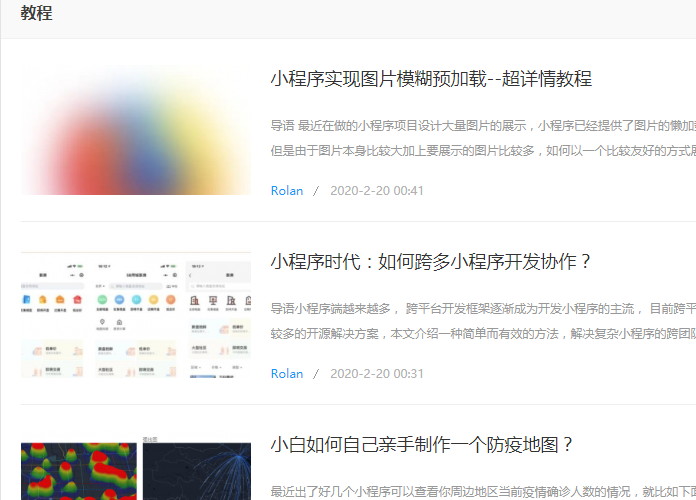
因为我们在这个页面里再爬取教程的详情页面,所以需要跟进
而在这个页面我们没有跟进:
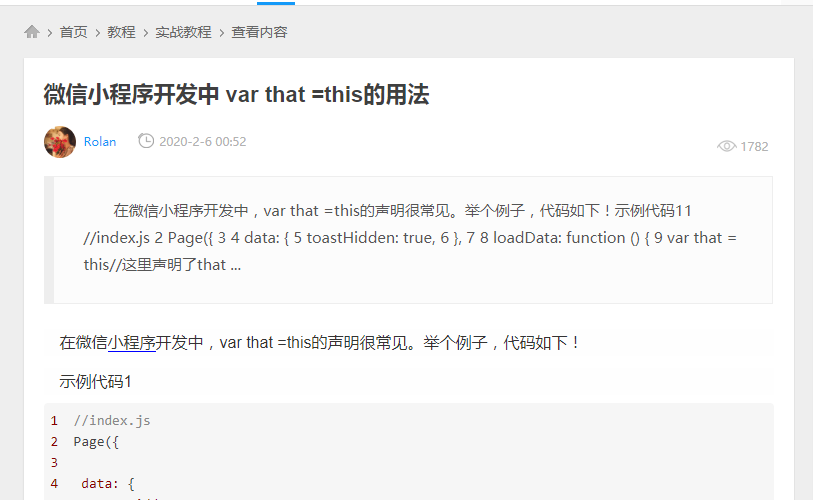
因为我们到了这个页面并且获取了教程详细信息之后,这个页面对于我们来说就已经无用了,虽然在这个页面的旁边可能还有其他的教程详情链接等待我们去点击,但是这些详情链接我们会在其他的地方爬取到的,虽然scrapy里面自动会去重,但我们为了省事,得到我们需要的东西之后就终止爬虫对于这个页面的探索,这样爬虫脉络更清晰一点
3,什么情况下该指定callback:如果这个url对应的页面,只是为了获取更多的url,并不需要里面的数据,那么可以不指定callback,如果想要获取url对应页面中的数据,那么就需要指定一个callback
callback里面的函数是我们对于页面进行详细解析的回调函数。我们需要对详细教程页的教程内容进行分析,所以需要callback,而在portal.php?mod=list&catid=2&page=1这一类页面里,我们仅仅是想要获取更多的详细教程的链接,也不需要更多的处理,所以不使用callback
除了这些之外,其他的地方跟原来的spider大致相同,爬取到的详细内容保存在了json文件里面

代码放在了github上面,欢迎Star
https://github.com/Cl0udG0d/scrapy_demo
参考链接:
https://geek-docs.com/scrapy/scrapy-tutorials/scrapy-crawlspider.html
https://www.kancloud.cn/ju7ran/scrapy/1364596
https://www.cnblogs.com/derek1184405959/p/8451798.html
https://www.bilibili.com/video/av57909837?p=8