因为在Scrapy的使用过程中,提取页面信息使用XPath比较方便,遂成此文。
在b站上看了介绍XPath的:https://www.bilibili.com/video/av30320885?from=search&seid=17721548966745663758
认识XPath
1,什么是XPath
1,解析XML的一种语言(HTML其实是XML的子级),广泛用于解析HTML数据
2,几乎所有语言都能使用XPath,比如Java和C语言
3,除了XPath还有其他手段用于XML解析,比如:BeautifulSoup,lxml,DOM,SAX,JSDOM,DOM4J,minixml等
2,XPath语法
XPath语法其实只有3大类
1,层级:/ 直接子级,//跳级
2,属性:@ 属性访问
3,函数:contains() text()等
使用XPath
1,在浏览器中使用XPath
跟在视频里面讲的类似,不过因为我想要爬取西刺代理,所以直接在西刺代理网站上进行分析
https://www.xicidaili.com/nn/1
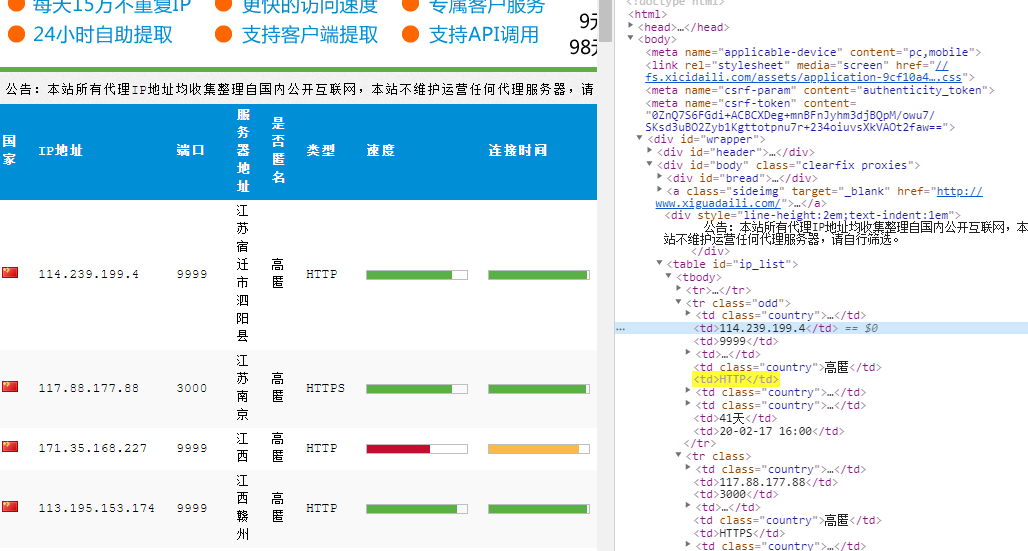
简单分析页面之后
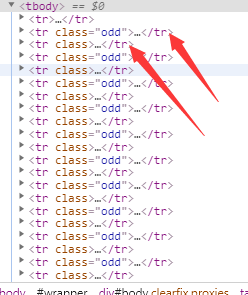
发现有ip的存在两种,一种是在<tr class="odd">...</tr>里面,另外一种是在<tr class>...</tr>
但是都是tr节点(除却第一个之外,因为第一个是 )
)
但是tr标签距离根差别很多级,所以我们使用//tr
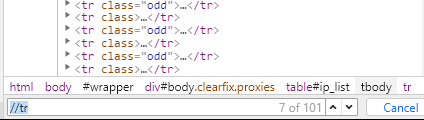
可以看到有101个,100个是ip的个数,还有一个是第一个,就是是蓝色的框。
深入分析tr里面

里面有几个td节点,ip在第二个td节点,port在第三个td节点,type在第四个td节点,这几个是我们所需要的,同级之下的提取视频里面没有讲,所以我去查了一下,可以使用//tr/td[2]来获取ip

可以看到这里是100个搜索结果,即100个ip,同样的方法获取port和type即可
2,在Scrapy中使用XPath
我们获取到了之后,在scrapy中整理输出第一页的代理ip,在spider爬取页面里写成:
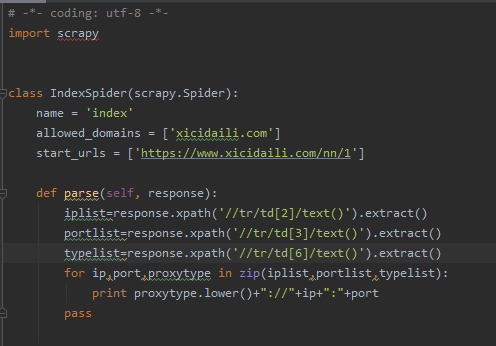
可以看到输出了100个IP地址:
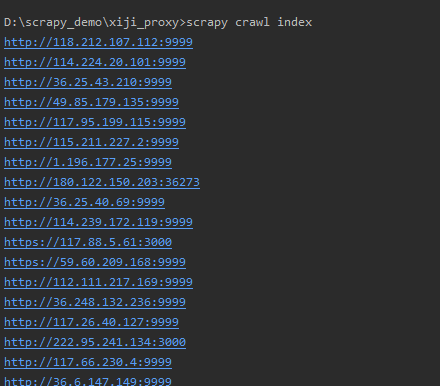
当然在爬取之前要将scrapy的setting.py里面的User-Agent设置好,还有robots.txt协议也要设置,才开始爬取,不然只会获取到空的结果。

还有一个就是设置LOG_LEVEL='WARN',这样运行scrapy的时候需要warning的时候才会输出log,避免出现很多日志信息干扰我们查看结果
这个只是第一页的IP地址,验证IP和储存IP,反爬等都还没有处理,剩下的下次另写一篇吧