二分图匹配
二分图的概念
二分图又称作二部图,是图论中的一种特殊模型。设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。(源自百度-二分图)

如上图就是一个标准的二分图。
二分图判断
染色。首先将任意的一个顶点染成红色,再把这个点相邻的顶点染成蓝色,如果按照这种染色方式可以将所有的顶点全部着色,并且相邻的顶点的颜色不同,那么该图就是一个二分图。
Code:
#define MAXV 1000
vector<int> G[MAXV]; //图
int V; //顶点数
int color[MAXV]; //顶点的颜色 (1 or -1)
//顶点v,颜色c
bool dfs(int v,int c){
color[v] = c;
//把当前顶点相邻的顶点扫一遍
for(int i = 0;i < G[v].size(); i++){
//如果相邻顶点已经被染成同色了,说明不是二分图
if(color[G[v][i]] == c) return false;
//如果相邻顶点没有被染色,染成-c,看相邻顶点是否满足要求
if(color[G[v][i]] == 0 && !dfs(G[v][i],-c)) return false;
}
//如果都没问题,说明当前顶点能访问到的顶点可以形成二分图
return true;
}
void solve(){
//可能是不连通图,所以每个顶点都要dfs一次
for(int i = 0;i < V; i++){
if(color[i] == 0){
//第一个点颜色为 1
if(!dfs(i,1)){
cout << "No" << endl;
return;
}
}
}
}
最大匹配与增广路的概念
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。(源自百度-二分图匹配)
最大匹配即是选择其中边数最大的子集的图。
完全匹配,也叫做完备匹配,即某个匹配中,每个顶点都和某条边相关联。
好的,现在介绍完一个基本概念,我们就要着手解决如何求解最大匹配的问题了。
若要找出二分图中的最大匹配,最朴素的方法就是找出所有的匹配并一一比较,但这种方法的时间复杂度是边数的指数级的,不能满足数据范围较大的问题。因此,我们需要找出一个更优的方法求解。
在寻找这更优的方法前,我们需要先了解增广路的概念:增广路,也称增广轨或交错轨。若P是图G中一条连通两个未匹配顶点的路径,并且属于M的边和不属于M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广路径(举例来说,有A、B集合,增广路由A中一个点通向B中一个点,再由B中这个点通向A中一个点……交替进行)。(源自百度-增广路)
由增广路的定义我们可以推出下述三个结论:
-
P的路径长度必定为奇数,第一条边和最后一条边都不属于M。
-
经过取反操作可以得到一个更大的匹配M’,边数为M的边数+1。
-
M为G的最大匹配当且仅当不存在相对于M的增广路径。
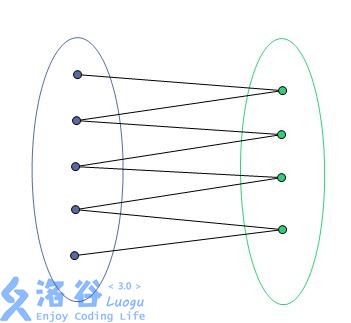
如图为一个二分图增广路集合。
匈牙利算法
匈牙利算法就是用增广路求最大匹配问题(由匈牙利数学家Edmonds于1965年提出)
算法的主要步骤为:
- 将M设置为空;
- 找出一条增广路径P,通过取反操作获得更大的匹配M’代替M;
- 重复2操作直到找不出增广路径为止;
给出一个大佬对匈牙利的算法的简单解释:传送门
Luogu P3386二分图匹配模板题
Code:
// 用邻接表建图
#include<cstdio>
#include<cstring>
#define sizee 1000500
#define sizen 1050
#include<iostream>
using namespace std;
int m,n,e;
int u[sizee],v[sizee],next[sizee],first[sizen],matched[sizen];
bool vis[sizen];
int tot = -1;
void add(int uu,int vv){
next[++tot] = first[uu];
first[uu] = tot;
u[tot] = uu;
v[tot] = vv;
return;
}
bool find(int i){// 采用dfs的方式, 不断地选择、调整
for(int j=first[i];j!=-1;j=next[j]){
if(vis[v[j]])continue;
vis[v[j]] = 1;
// matched[v[j]]指的是当前找到的编号为v[j]的b集合内的点已经匹配了的a集合内的点
if(matched[v[j]] == 0 || find(matched[v[j]])){
matched[v[j]] = i;
return true;
}
}
return false;
}
int Hungary(){
memset(matched,0,sizeof(matched));
int cnt = 0;
for(int i=1;i<=n;i++){//从每个a集合的点开始,因为可能有不连通的同集合的点
memset(vis,0,sizeof(vis));//vis指当前这此操作改动过匹配方案的b集合的点
if(find(i))cnt++;
}
return cnt;
}
int main(){
memset(first,-1,sizeof(first));
int uu,vv;
scanf("%d%d%d",&n,&m,&e);
for(int i=1;i<=e;i++){
scanf("%d%d",&uu,&vv);
if(vv > m || uu > n)continue;
add(uu,vv);
}
printf("%d",Hungary());
return 0;
}