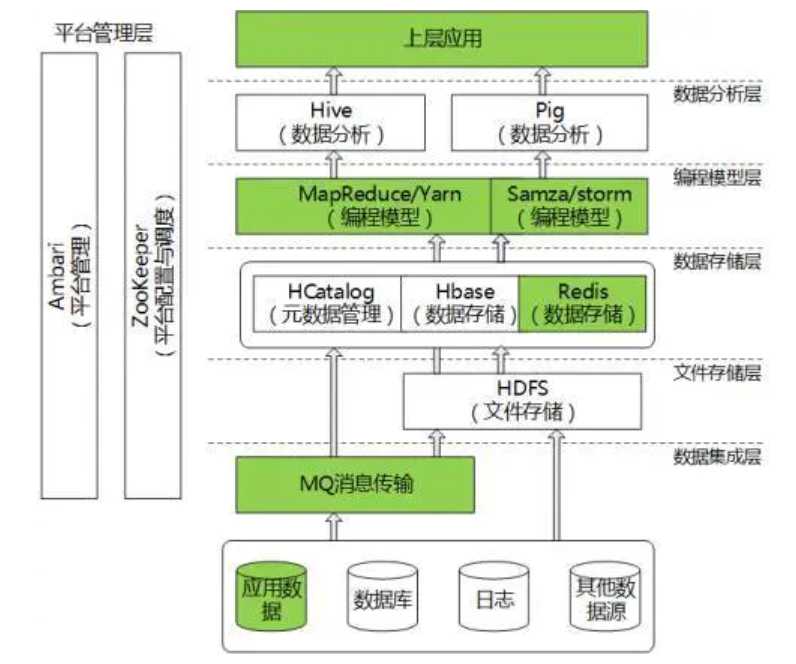
Hadoop 组件
- HDFS分布式文件系统
作为Hadoop分布式文件系统,HDFS处于Hadoop生态圈的最下层,存储着所有的数据,支持着Hadoop的所有服务。
HDFS是基于节点的形式进行构建的,里面有一个父节点NameNode,他在机器内部提供了服务,NameNode本身不干活,NameNode将数据分成块,只是把数据分发给子节点dataNode,交由子节点来进行存储。
- MapReduce分布式离线计算框架
基于YARN的大型数据集并行处理系统。是一种计算模型,用以进行大数据量的计算。
- Yarn资源调度
分布式集群资源管理框架,管理者集群的资源(Memory,cpu core)
- Hbase数据库
Hbase即 HadoopDatabase 的简称,是一种NoSQL 的Key/value数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询。HBase是一个基于HDFS的分布式数据库,擅长实时地随机读/写超大规模数据集。如果说HDFS是文件级别的存储,那HBase则是表级别的存储。
HBase是一个提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库,一般采用HDFS作为其底层数据存储。
Hbase是一个内存数据库,而hdfs是一个存储空间;是物品和房子的关系。hdfs只是一个存储空间,hbase是一个内存数据库,简单点说hbase把表存在hdfs上。
- hive数据仓库
Hive是Hadoop的数据仓库,严格地讲并非数据库,是一种类SQL的引擎,并且运行MapReduce任务。主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,可以对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储,适用于离线的批量数据计算。Hive适合用来对一段时间内的数据进行分析查询,Hbase非常适合用来进行大数据的实时查询。
在大数据架构中,Hive和HBase是协作关系,1.通过Hive清洗、处理和计算原始数据;2.通过ETL工具将数据源抽取到HDFS存储;3.Hive清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase;4.数据应用从HBase查询数据。
1.hive是基于Hadoop的一个数据仓库工具;
2.可以将结构化的数据文件映射为一张数据库表,并提供类sql的查询功能;
3.可以将sql语句转换为mapreduce任务进行运行;
4.可以用来进行数据提取转换加载(ETL);
5.hive是sql解析引擎,它将sql 语句转换成M/R job然后在Hadoop中运行;
hive的表其实就是HDFS的目录/文件夹。按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R job里使用这些数据。
- Flume日志采集
Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于数据收集;同时,Flume提供对数据进行简单处理并写到各种数据接受方的能力。
- Sqoop
Sqoop是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据的互操作性。通过Sqoop可以方便地将数据从MySQL、Oracle. PostgreSQL等关系数据库中 导人Hadoop (可以导人HDFS、HBase或Hive ),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。
- Zookeeper - 监测组件心跳,是否有效
Zookeeper是针对谷歌Chubby的一个开源实现,是高效和可靠的协同工作系统,提供分布式锁之类的基本服务,用于构建分布式应用,减轻分布式应用程序所承担的协调任务。
- Impala - SQL支持
一个开源的查询引擎。与hive相同的元数据,SQL语法,ODBC驱动程序和用户接口,可以直接在HDFS上提供快速,交互式SQL查询。impala不再使用缓慢的hive+mapreduce批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎。可以直接从HDFS或者Hbase中用select,join和统计函数查询数据,从而大大降低延迟。
- storm计算框架
storm是一个分布式的,容错的计算系统,storm属于流处理平台,多用于实时计算并更新数据库。storm也可被用于“连续计算”,对数据流做连续查询,在计算时将结果一流的形式输出给用户。他还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。
- Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
- Redis数据库
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
数据采集、存储、分析场景
该场景下完成了整个数据的采集、存储、分析,并输出结果,组件搭配如下:
Flume + kafka(zookeeper)+ Hdfs + Spark/Storm/Hive + Hbase (Zookeeper、Hdfs) /Redis
说明如下:
- Flume用来从种渠道(如http、exec、文件、kafka , …)收集数据,并发送到kafka(当然也可以存放到hdfs、hbase、file、…)。
- Kafka可以缓存数据,与flume一样也支持各种协议的输入和输出,由于kafka需要zookeeper来完成负载均衡,所以需要zookeeper来支持。
- 数据计算,Spark/Storm/Hive,各有优势,相对Hive目前仍使用广泛,该技术出现的较早;Storm专注于流式处理,延迟非常低; Spark最有前景的计算工具;不管用什么,最终都是对数据的清理、统计,把得到的结果输出。
- 展示结果数据存储,可以使用Hbase/kafka(zookeeper) /Redis/mysql等,看使用场景(数据量大小等因素),由于处理之后的结果数据一般比较少可以直接放到Redis,然后就可以采用常规的技术展示出报表或其它消费方式使用这些计算后的结果数据。
MapReduce原理
MapReduce计算模型主要由三个阶段构成:Map、Shuffle、Reduce。Map是映射,负责数据的过滤分类,将原始数据转化为键值对;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果;为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,然后再交给对应的Reduce,这个过程就是Shuffle。Shuffle过程包含Map Shuffle和Reduce Shuffle。
1)Map Shuffle
在Map端的shuffle过程就是对Map的结果进行分区、排序、分割,然后将属于同一个分区的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件。分区有序的含义是Map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排序(默认)
2)Reduce Shuffle
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。Map任务成功完成后,会通知父TaskTracker状态已经更新,TaskTracker进而通知JobTracker(这些通知在心跳机制中进行)。所以,对于指定作业来说,JobTracker能记录Map输出和TaskTracker的映射关系。Reduce会定期向JobTracker获取Map的输出位置,一旦拿到输出位置,Reduce任务就会从此输出对应的TaskTracker上复制输出到本地,而不会等到所有的Map任务结束。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
数据架构包含:数据采集层,数据调度平台、数据展示
埋点采集主要是离线数仓和实时采集,改进方案:NG -> Kafka -> StructuredStreaming/Flink,然后实时的需求直接走StructuredStreaming/Flink,获取实时的数据存到redis/ES等内存数据库中,可以做搜索推荐。离线的将数据存到HDFS中,第二天对昨天的日志进行合并(主要是合并小文件)
数据中台主要包含:数据治理、数据安全、数据质量
Hadoop的最核心的存储层叫做HDFS,全称是Hadoop文件存储系统,有了存储系统还要有分析系统mapreduce,mapreduce做分析太重,脸书开源了hive
Hadoop最开始设计是用来跑文件的,对于数据的批处理(batch data processing)能力较强,实时数据(streaming data processing) 使用spark 或flink