互联网信息过载,用户疲于应对纷繁复杂的信息,新时期的矛盾从用户获取信息和信息不足的矛盾转变为,用户获取高价值的信息和获取高价值信息成本高的矛盾,基于用户需求和兴趣进行信息匹配,是当前和未来推荐系统发展的趋势。
现代推荐系统简介
从百万量及样本通过粗排序模型(召回模型)生成百千级的候选集;通过精排生成百十级候选集展现给用户。粗排一般用户简单的协同过滤模型,基于用户历史数据特征;精排用于基于特征的推荐系统模型,例如深度类型的wide&deep,除了用户历史行为数据,还用到其他的旁路信息。
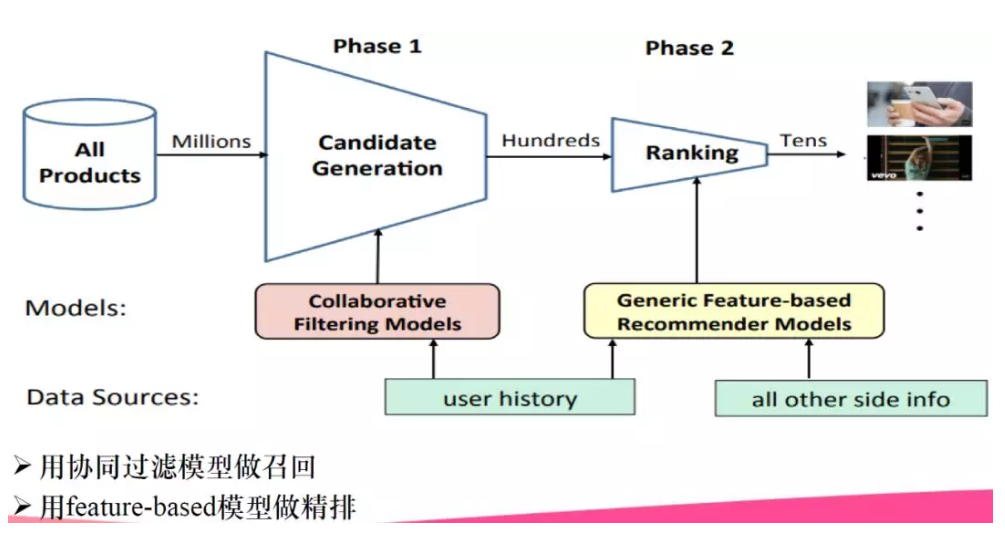
召回&排序
召回阶段:用于成本低、易实现、速度快的模型(协同过滤)进行初步筛选;
排序阶段:用于更全面的数据、更精细的特征、更复杂的模型进行精挑细选。
实际的业务中还有重排序和人工规则阶段,这里更多应用策略,集中业务和技术策略。为了更好的推荐体验,或加入去重、结果打散增加推荐结果的多样性、强插某种类型的推荐结果等不同类型的策略。从技术发展趋势看,重排阶段上应用模型,替代业务策略,是总体的趋势。重排阶段用list wise排序(list wise一个是优化目标和损失函数;一个是推荐模块的模型结构)。重排具体的内容可以看:推荐系统技术演进趋势,从召回到排序再到重排--张俊林的知乎
召回 recall
5.1 基于邻域的协同过滤
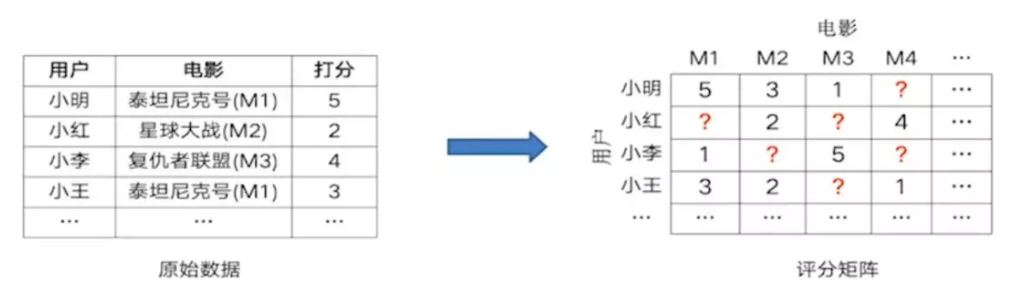
邻域建模是将用户对电影的评分日志转换成评分矩阵的形式,在矩阵中存在大量的空白,建模的过程就是填充空白项的过程,这样可以得到所用用户对所有电影的评分(喜好程度),可以据此进行个性化推荐。
求解空白项的过程:
计算用户物品余弦相似度;基于相似度和先用评分矩阵填充缺失值

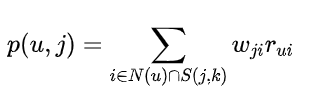
举例:
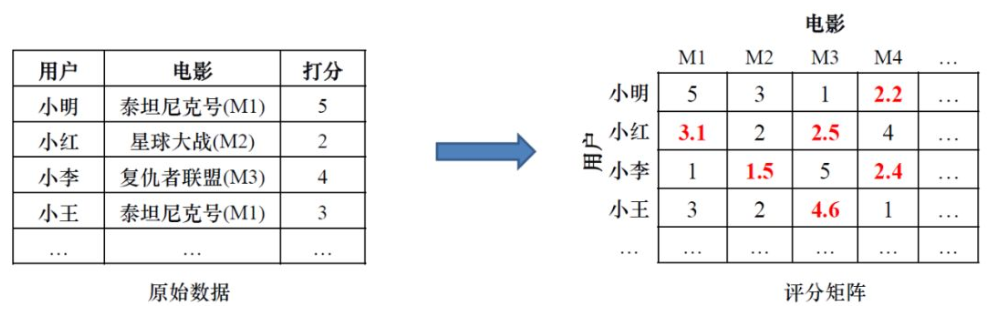
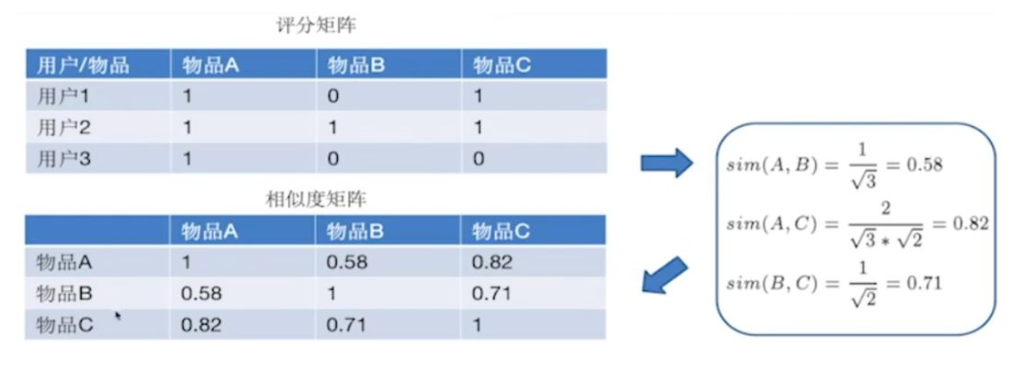
1、在评分的矩阵中,1表示用户交互过的评分,0表示算法需要填充的评分。用余弦相似度计算物品的相似度,可以得到物品相似度矩阵。
2、根据p(u,j)公式,算出用户对缺失物品的评分。把所有的评分算好后,可以填充评分矩阵中的缺失值。
通过上面的计算,可以对用户3进行推荐,得到用户3未操作的物品B的评分为0.58,未操作物品C的评分0.82,按照评分大小进行排序,生成有序的推荐集,用户3的推荐集为(物品C > 物品B)。
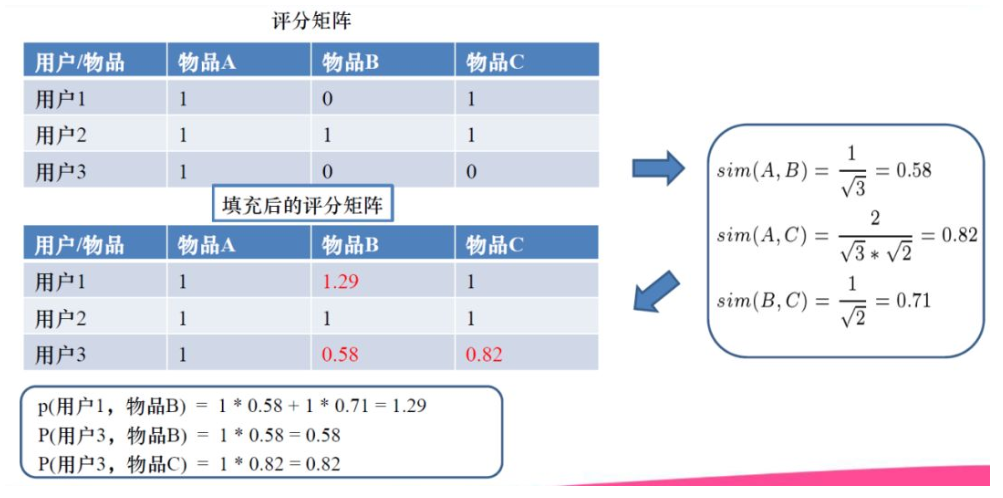
基于邻域的方法,是统计方法的延生,不是优化学习的方法(没有学习过程和设立指标优化的过程)。
用了局部数据计算相似度,进行推荐,类似于业务策略,没有考虑全局数据。实际业务中,面临用户和物品推荐维度很大,计算量大,难以存储等问题。基于这些原因,出现了基于隐向量的协同过滤方法。
5.2 基于隐向量的协同过滤
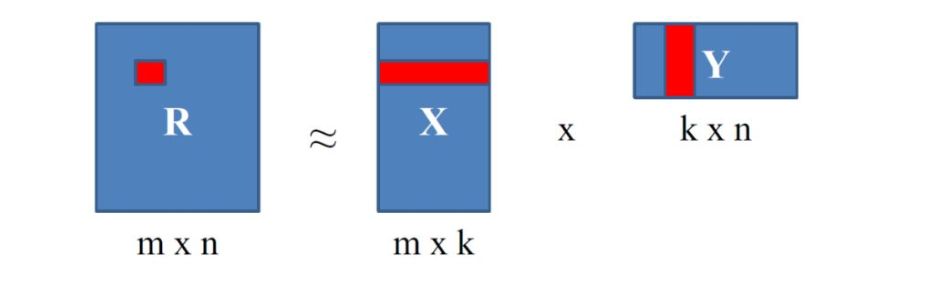
基于矩阵分解方法建模目的是补全缺失值。显式反馈常用方法是把高维稀疏评分矩阵 R 分解成两个小矩阵 X 和 Y 相乘的形式, 用两个小矩阵乘积拟合原始的大评分矩阵。目标函数是均方误差,小矩阵拟合效果越好,(rui - xu yi)2的差值越小,最后损失也越小。

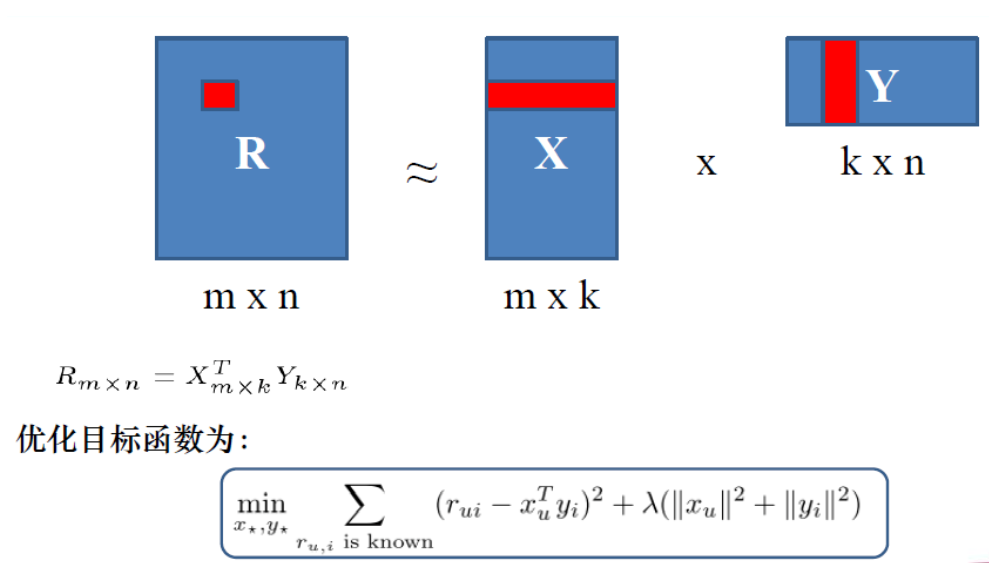
隐式反馈常用方法
用户不会对每一个主播进行评价交互,一般使用用户和主播的交互程度作为用户偏好,交互指标选择观看时长、点击次数和观看次数。
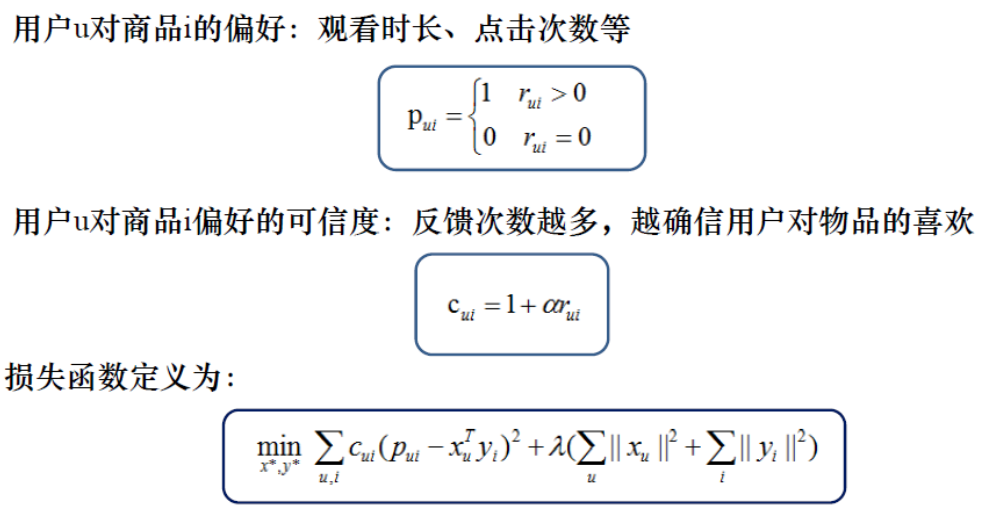
隐式反馈先根据交互程度 rui得到一个pui,比如我们观看时长大于10秒,pui = 1,观看时长小于10秒时,pui = 0。pui 代表用户的评分矩阵,取值范围【0,1】。XuYi 表示两个小矩阵来拟合大矩阵pui,公式中比显式反馈多了Cui ,表示对物品的置信度,它正比于反馈次数rui ,反馈越强烈,这一项值越大。可把Cui 这一项理解为加权训练,交互程度高,权重越高,训练的效果越好。
相关论文:
【1】Hu Y, Koren Y, Volinsky C. Collaborative filtering for implicit feedback datasets[C]//2008 Eighth IEEE International Conference on Data Mining. Ieee, 2008: 263-272.
目标函数求解
显式反馈和隐式反馈都可以通过最小二乘法(ALS)进行求解X,Y解法。

实际中如何应用
X中每行作为一个用户的隐向量,Y中每列作为一个物品的隐向量,离线训练好后将X,Y两个矩阵存起来,线线上,用户隐向量和主播隐向量进行内积运算,根据得分高低进行排序。
矩阵分解小结:
优点:模型简单易实现;线上速度快(可离线训练,线上只需要点积运算);存储少(高维稀疏矩阵变为低维稠密隐向量矩阵);
缺点:推荐结果可解释性差;不够综合、全面(和ranking系列模型相比)

深度学习的矩阵分解
(1) 深度学习+矩阵分解
有些示例表明,学到用户/物品的隐向量后,直接用内积描述用户-物品交互关系(matching function) 有一定的局限性,即内积函数(inner product function)限制了MF的表现力 。
随着深度学习的兴起,有学者提出了新的模型:即借鉴深度学习中的方法,使用深度神经网络 (DNN) 从数据中自动学习用户/物品隐向量的交互函数(即内积函数),在增强表现力的同时也可以引入一定的泛化能力。示例:NCF框架。(Neural Collaborative Filtering)
(2) Neural Collaborative Filtering(NCF)
下图中,左边是用户的隐向量,右边是物品的隐向量,如果直接做内积的话,就是传统的矩阵分解。NCF直接把内积计算换成了DNN,并且变成了传统机器学习的模式,用神经网络训练的方式学习交互关系。
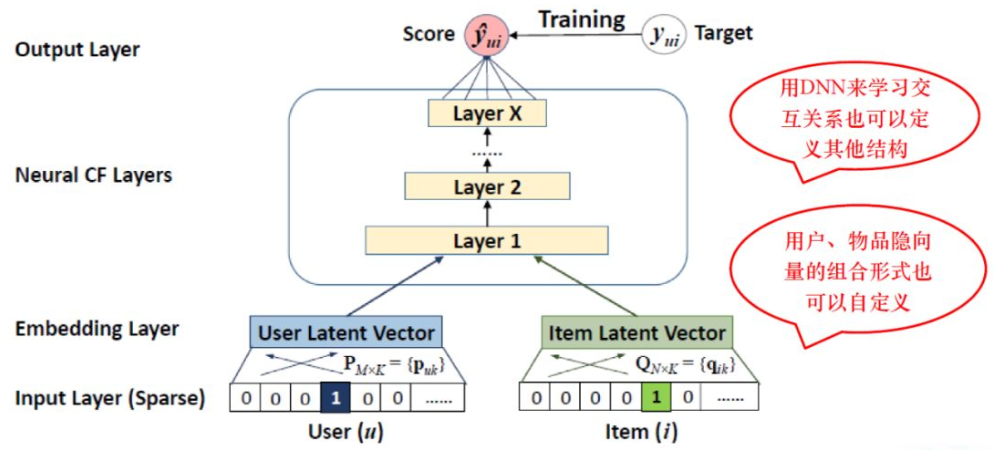
NCF论文:
【1】He X, Liao L, Zhang H, et al. Neural collaborative filtering[C]//Proceedings of the 26th international conference on world wide web. 2017: 173-182.
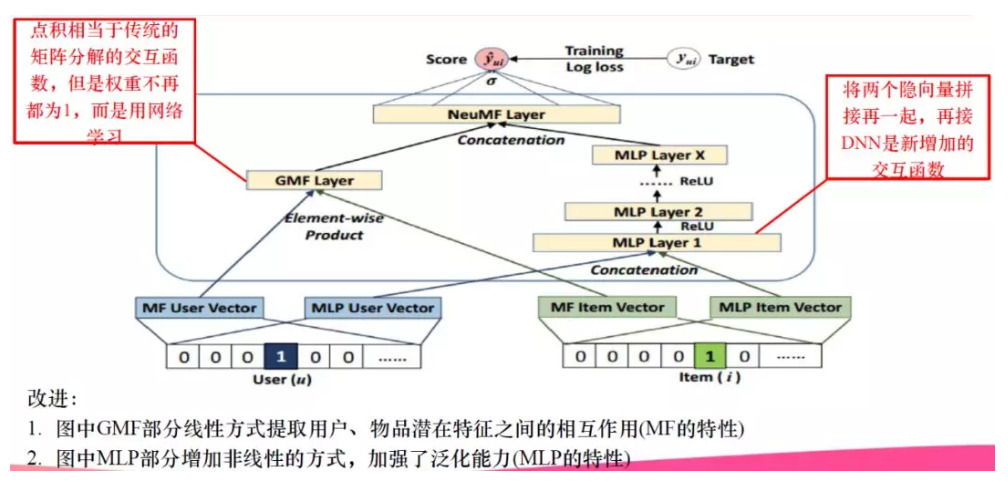
(3) NeuMF
集大成者的一个模型就是NeuMF(神经矩阵分解)。如下图所示,它提出了一个GMF Layer(广义矩阵分解层)和一个DNN层。可以看到拿到用户和物品的隐向量之后,一方面在GMF层做元素级别的乘积,其实内积就是对应位置相乘再相加,NeuMF稍微改进了一下,对应位置相乘完之后,不是直接相加,而是再学一次权重,这就是在接一个Dense层来学习一下权重,相当于传统的矩阵分解权重不在都为1,而是用网络学习。另一方面,加入了一个DNN层。把用户隐向量和物品隐向量直接Concatenate起来以后,直接接入一个DNN层。最后将两方面的结果Concatenate起来接到输出层。
这样做的好处是,GMF Layer保留了内积的方式NeuMF又引入了DNN的方式,结论表明这样做既可以增强传统矩阵分解的表现力又可以引入DNN自己的一些高阶特征交叉的特点进而引入了一定的泛化性。
NeuMF论文:
【1】He X, Liao L, Zhang H, et al. Neural collaborative filtering[C]//Proceedings of the 26th international conference on world wide web. 2017: 173-182.
最后,关于深度协同过滤的内容到这里就结束了,大家感兴趣的话,可以参考“花椒技术公众号”里文章:深度学习在花椒直播中的应用—神经网络与协同过滤篇,地址:https://mp.weixin.qq.com/s/ERfIcCJ7ne4OjfRStdR_vw 。这篇文章专门讲一些神经网络和协同过滤的内容,也含有一些代码和实例,也是曾经在花椒直播平台用作召回的模型。
5.3 其他模型
随着时代发展,基于邻域的协同过滤和基于隐向量的协同过滤是比较常见的,现在也有其他模型的出现,比如说Youtube的召回模型。
其他比较火的召回模型,比如说双塔模型,基于DNN或FM的双塔模型,这种模型的特点就是用户和物品各一个塔,从这两个塔中得到用户和物品的隐向量,在线上也是用两个隐向量进行内积得到用户对物品的得分,然后对得分进行排序。除此之外,其他召回模型还有基于用户多兴趣的模型、知识图谱模型和图神经网络等。这些模型都是比较新、比较潮流的,感兴趣的话可以根据自己的场景进行试验。
6 精排 (ranking)
把特征输入到模型中,用模型来做二分类,大于等于0.5是喜欢,小于0.5是不喜欢。如果是喜欢的话,怎么分喜欢和更喜欢呢?对物品做排序,分高的是更喜欢,其次是喜欢。
我们希望模型学到这样的效果:北京35岁的年轻男性用户王先生喜欢看“正在跳舞互动多的年轻女主播”,不喜欢“男性游戏主播”。这里面“北京”、“35岁”、“男性”、“王先生”(id类特征)是用户特征,“正在跳舞”、“互动多”、“年轻”、“女主播”是主播特征。我们希望通过许多样本,让模型学出不同用户的喜好

6.1 特征工程
把用户画像、主播画像和标签对应起来就会形成一条样本。我们就可以把今天的数据提取出来,组成训练样本。
特别需要注意,不能有数据穿透! 就是说,今天的数据我们当做标签的话,生产画像的时候,就一定不能包含今天的数据,而是用不包含今天的前N天数据来生产画像。
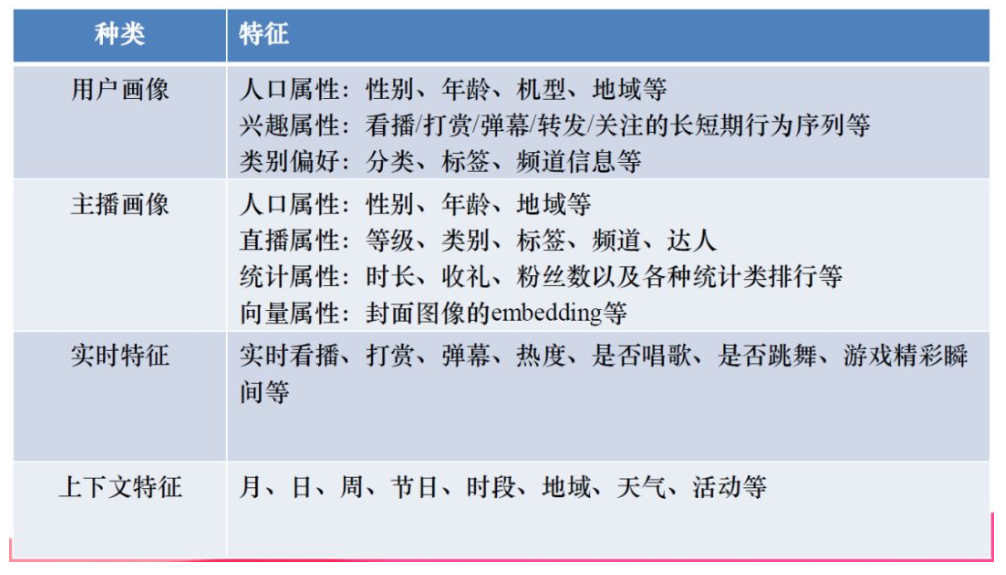
6.2 排序模型
早期的排序模型 : LR,FM/FFM,GBDT+LR
LR可解释强,但特征交叉能力差;FM(因子分解机)通过二阶特征交叉可以进行特征组合,但高阶交叉容易维度爆炸;GBDT+LR 可以进行特征交叉,但属于串行模型,并行能力差;

深度排序模型:
wide & deep类:DeepFM,DCN,DIN
以多任务学习为基础的联合训练模型:ESMM,MMOE
有LR模型还有DNN模型,自然有研究者就把这两者结合在一起。因为LR的好处就是记忆性,缺点就是人工特征交叉、特征工程复杂;DNN的好处就是泛化能力强、可以自动学习特征之间潜在关系、是一种端到端的模型。所以把它们两个结合在一起后,即兼顾了记忆性、泛化性,还能端到端的训练,serving起来也是比较简单的。
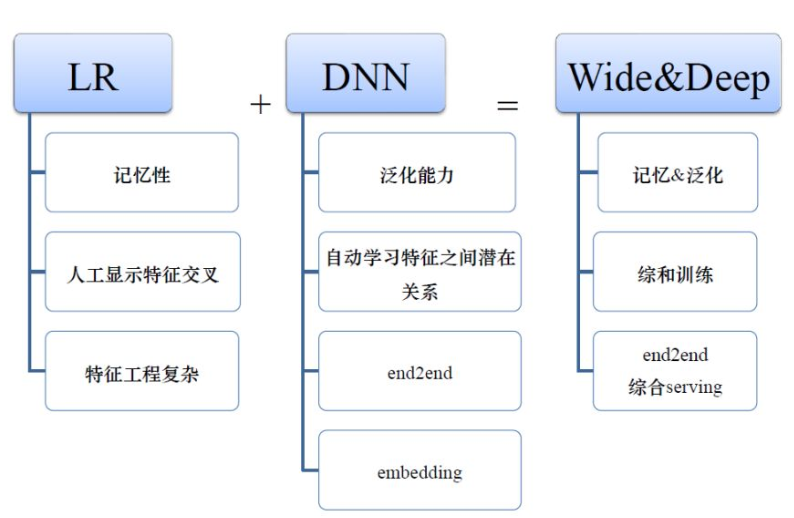

从上图的Wide&Deep模型中可以看出,左边是一个LR,右边是一个DNN。这种深浅双塔结构的提出极大的促进了后续模型的发展,后续很多模型都是基于这个模型的改动。
Wide & Deep论文:
【1】Cheng H T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st workshop on deep learning for recommender systems. 2016: 7-10.
FM + DNN = DeepFM
既然LR能和DNN结合,自然又有研究者想到FM也能和DNN结合,这就是DeepFM模型。与Wide&Deep模型的区别在于把左边的LR换成了FM,这样即能保证有LR部分的特点,还能多一个二阶自动交叉的FM特点。
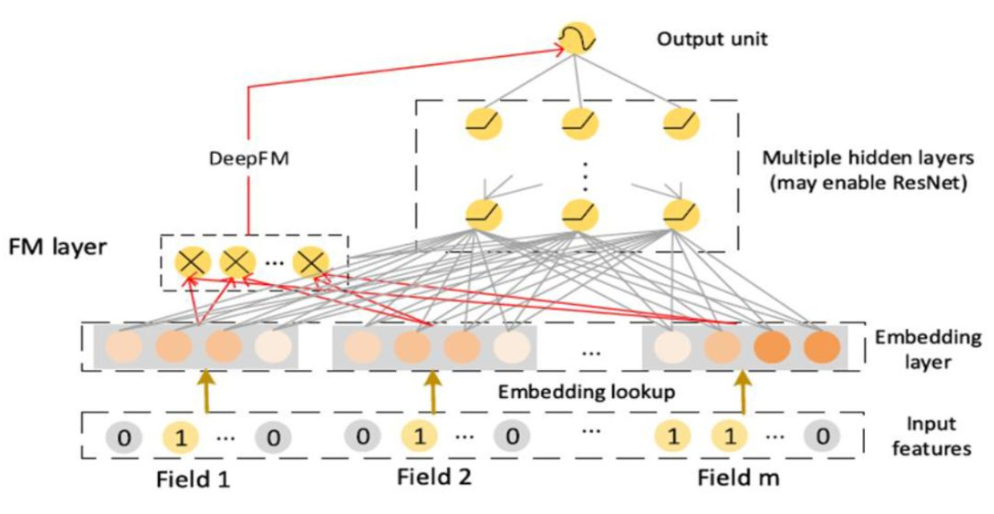
DeepFM论文:
【1】Guo H, Tang R, Ye Y, et al. DeepFM: a factorization-machine based neural network for CTR prediction[J]. arXiv preprint arXiv:1703.04247, 2017.
Wide&Deep类模型区别就在两部分:一是特征交叉的方式是隐式/显示、元素级/向量级、二阶/高阶中的哪一个;二是所有Embedding的级联方式是concatenate/weighted sum/product/attention中的一种
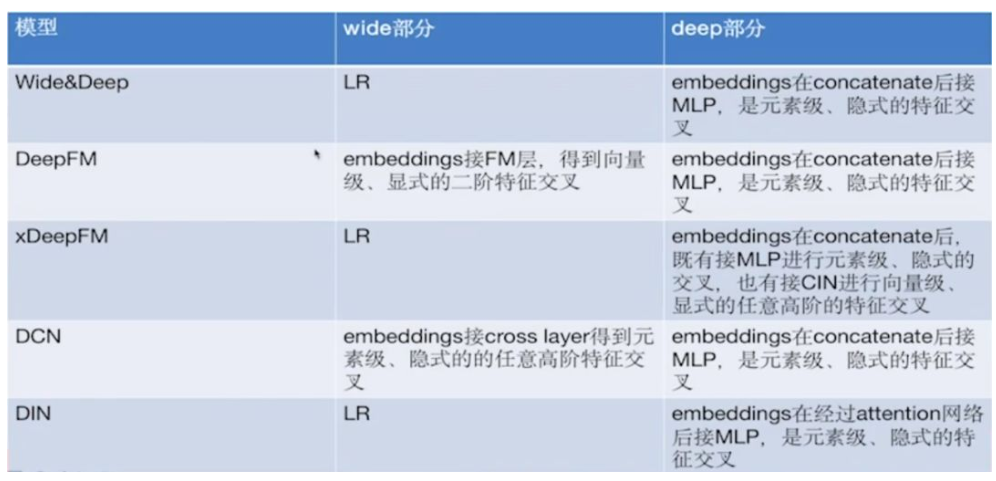
相关文章:
【1】深度学习在花椒直播中的应用——排序算法篇,地址:https://mp.weixin.qq.com/s/e6Spp7smIEUUExJxHzUOFA 。这篇文章主要是分析Wide&Deep类模型,这里面只简单的介绍了五种排序模型,但是还有好多模型都可以归为Wide&Deep类,都是在Wide部分或者Deep部分有一些改动,总体框架都是差不多的。
多任务类模型
推荐系统的多目标优化,是目前业界的主流之一,也是很多公司的研发现状。以花椒直播为例,可以优化的目标有点击、观看、送礼、评论、关注、转发等等。
多任务模型旨在平衡不同目标的相互影响,尽量能够做到所有指标同步上涨,即使不能,也要尽量做到在某个优化目标上涨的情况下,不拉低或者将尽量少拉低其它指标,力求达到全局最优的效果。
ESMM模型首次把样本空间分成了三大部分,从曝光到点击再到转化的三步行为链,并引入了浏览转化率(pCTCVR)的概念。我们正常做CVR任务的时候,默认只在点击的空间上来做,认为曝光、点击并转化了就是正样本,认为曝光、点击并未转化为负样本。如果这样想的话,样本全空间只有点击的样本,而没有考虑没有点击的样本。ESMM论文就提出曝光点击、曝光不点击以及点击之后是否转化所有的这些样本都考虑进来,因此提出三步的行为链。
ESMM论文:
【1】Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1137-1140.
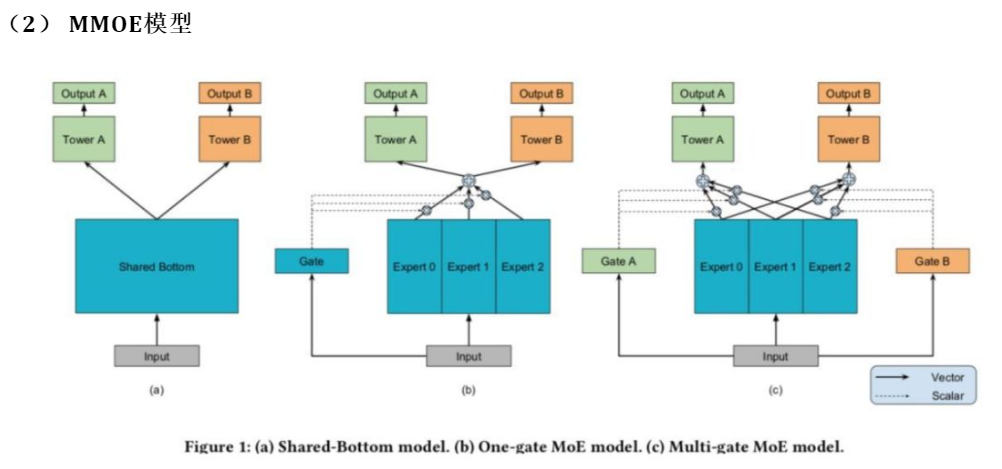
很多多任务模型是上图(a)这种模式,共享一个底层的Embedding之后,然后两个塔得到两个任务。但是它的使用表明如果多任务的相关性比较低的话,模型的效果就比较差。基于这种现象就提出了上图所示的(b)(c)专家网络,希望不同的任务可以从输入得到不同的东西,这就有点类似于Attention的部分了。用门来决定塔可以从输入拿到什么东西,这样的好处就是每一个Tower可以拿到不同的输入,这样就可以减少任务之间相互拖后腿的情况。这种架构也是目前比较常见的。
上面分享了花椒直播推荐系统从0到1的搭建过程,包括召回和排序过程,但可以发现这些其实是很通用的,完全可以应用于商品推荐、小视频推荐等其他场景。
MMOE论文:
【1】Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1930-1939.
花椒直播的推荐业务
直播中的推荐和商品推荐等场景有所不同,是“活的”而不是“死的”,因为直播是长时间连续性的,并且内容是实时在变的,比如用户喜欢看跳舞直播,那么当主播不跳的时候用户可能也不想看了。因此我们需要把直播最核心、最精彩的部分挖掘出来推荐给用户。这就需要对多模态内容进行理解、融合,包括但不限于:
- 文本(如直播间标题、弹幕等);
- 图片(如主播头像、封面等);
- 视频(如可以识别主播是否在跳舞、游戏、挂机等);
- 音频(如可以识别主播是否在唱歌,在唱什么类型的歌等);
直播的实时数据反映了当前的火热程度,放在模型中可以加强推荐系统的准确性和实时性。
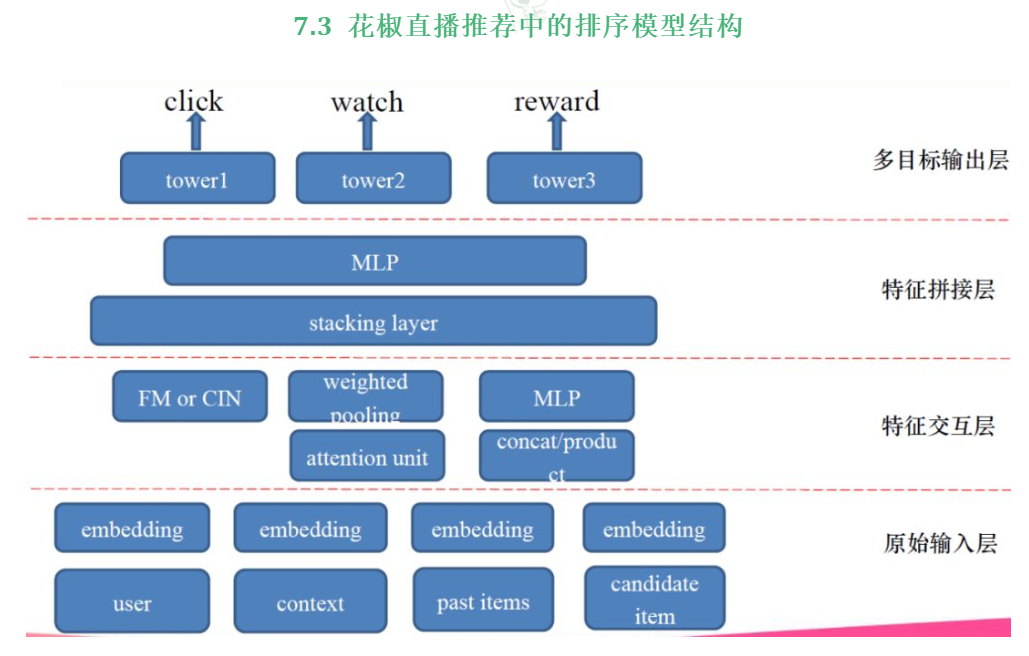
- 原始输入层:用户特征、上下文特征、过去交互过的物品特征和当前要预测的物品的特征。
- 特征交互层:特征交互层就像上文总结的Wide&Deep类模型一样,可以有很多部分。比如,FM可以来提取特征之间的二阶交叉,举例,拿用户性别的Embedding和候选主播的Embedding来做二阶交叉,FM可能会学到男用户喜欢看女主播。CIN是多阶交叉,可以拿多个特征放到CIN中进行高阶特征组合。Attention就像DIN那种方式,可以把过去交互过的主播和当前要预测的主播放到Attention中。这样当前预测主播是跳舞,可以把用户过去看过的游戏主播权值训练的小一些,过去看过的跳舞主播权值大一些,这样就达到了筛选优化的作用。还有简单的方式,就是把这些Embedding全都连接起来,接一个全连接层。
- 特征拼接层:特征拼接层就是把特征交互层得到的Embedding向量拼接在一起,然后接个全连接。这个全连接可以起到降维的作用,把Embedding的维度降小一点。因为,多目标输出层中还有多个tower。
- 多目标输出层:类似MMOE的结构,可以设计一个专家网络,这样每个任务从特征拼接层的输出中学到不同的东西,避免造成各任务之间相互干扰的情况。常见的任务有:点击,用户是否点击了这个主播。观看,可以定义观看多少秒以下是无意义的观看,多少秒以上是有意义的观看,并且可以把观看时长作为一个权重进行加权训练。送礼,送的是正样本,没送的是负样本,送了多少可以当成权重进行加权训练。多任务训练的好处就是可以用全样本数据,且原始输入层中的Embedding也会训练的更加充分。

训练原始数据有用户数据、物品数据、实时数据和上下文数据。用这些数据解析成用户/主播画像作为训练数据,用户主播交互标签作为训练数据的label。离线训练的部分,就是上文所讲的训练集生成的过程。每天生成一天的训练样本,把多天的训练样本组合起来形成全量样本,满足覆盖度和数据量的要求。全量样本直接存储在HDFS上,以天或周的级别进行更新,这样可以保证模型的准确性。另一部分是增量样本,比如flink流,可以线上对模型进行流式更新,这样可以满足模型实时性的要求。模型验证模块,验证模型指标有没有达到我们期望的阈值,防止一些不好的特征把模型训练坏了,还推上线的情况。模型验证好之后,需要上线服务就可以用Tensorflow Serving这种框架来进行线上服务。推荐引擎用的是golang来处理用户的请求,以及将请求转化为特征,并把特征喂给Tensorflow Serving的一个流程。golang的性能比较高。
分享总结了花椒直播沿着业内的发展路线从0到1搭建个性化推荐系统的过程,先后尝试了许多模型,每个模型除了其典型的结构外,还有许多非常珍贵的细节,比如公式推导、参数的选择、工程上的trick等等,这些大家可以查阅相关模型论文。
要注意的是,没有“最好的模型”,只有“最适合的模型”,并不是说模型越fancy越复杂,线上效果就会越好。比如阿里提出了DIN模型,是因为工程师们首先发现了数据中“多峰分布”、“部分激活”的现象,而在直播场景中这个特点就不是很明显,因此上线了DIN模型后的提升也不是很大。
但直播场景也有其自身的特点,如多模态、实时性和热点效应等。只有深入理解了场景,并基于用户行为和数据提取出能表现这个场景的特征,再对应的开发适用于这个场景的模型,才能取得最佳的效果。
参考文章:
直播场景推荐系统,推荐大家关注原博主公众号。
【1】花椒直播推荐系统高级算法工程师王洋:智能推荐系统在直播场景中的应用,视频,地址:https://www.bilibili.com/video/av90507035?t=1453
【2】回顾 | 花椒直播推荐系统高级算法架构师王洋:智能推荐算法在直播场景中的应用,地址:https://mp.weixin.qq.com/s/1Hrl25TjDKiEvPa35RDyNQ
【3】深度学习在花椒直播中的应用——排序算法篇,地址:https://mp.weixin.qq.com/s/e6Spp7smIEUUExJxHzUOFA
【4】深度学习在花椒直播中的应用—神经网络与协同过滤篇,地址:https://mp.weixin.qq.com/s/ERfIcCJ7ne4OjfRStdR_vw
【5】深度学习在花椒直播的应用——Tensorflow 原理篇,地址:深度学习在花椒直播的应用——Tensorflow 原理篇