目录:
1、Elmo与transformer的简单回顾
2、DAE与Masked Language Model
3、Bert模型详解与不同训练方法
4、如何把bert模型应用到实际项目中
5、如何对bert减肥(优化)
6、bert存在的问题
1、Elmo与transformer的简单回顾
一词多义是NLP目前的重要问题之一,Elmo作为一种语言模型,给定文本的context,预测下一个词。Elmo部分程度上解决了一词多义的问题,word2vec,glove训练的embedding是静态的,elmo考虑更多额context信息,对每一个词给出3个embedding,对3个embedding特征会添加三个位置,不同的任务赋予不同德尔权重,根据权重对embedding做向量平均,作为最终embedding。
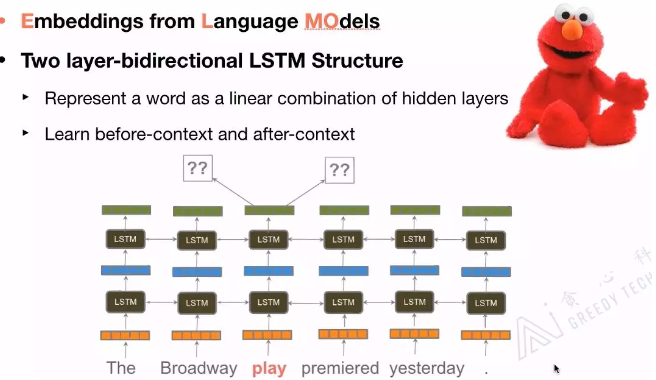
elmo用的是long contexts信息,不同于其他模型的window size contexts信息。同时,elmo用到bi-lstm,如果elmo换成transformer就和bert结构一样。
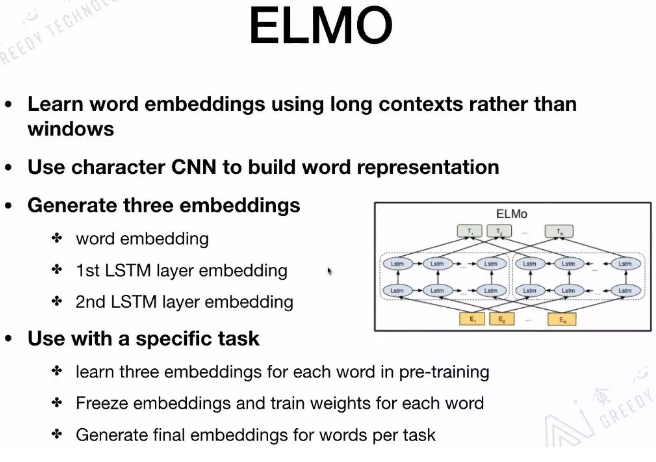
transformer与LSTM的区别:
- 基于RNN的LSTM训练是迭代的,当前序列进入完LSTM单元后才能输入到下一个序列的训练单元中,是串行结构
- transformer的训练是并行进行,所以序列可以同时进行训练,加入位置嵌入后,提高了模型对语言顺序的理解
transformer中encoder的五个核心部分:self-attention,layer norm,skip connection(直连边),forward network,positional encoding
2、DAE与masked language model
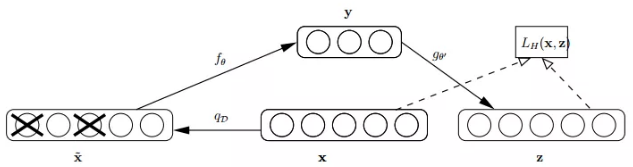
语音、图像等高维数据的出现,传统统计学-机器学习方法解决上效果欠佳。线性学习的PCA降维方法只对线性数据效果较好,CNN利用卷积、降采样很好的处理了特征。对于非信息数据,研究者提出了自动编码器(autoencoder),研究者提出了自动编码器(autoencoder):原始input(x)经过加权(w,b),映射(sigmoid)之后得到y,再对y反向加权映射回来成z,结构如下:

自动编码器的过程没有使用标签计算误差update参数,属于无监督学习,利用类似神经网络的双隐层方式,简单粗暴的提取了样本的特征。为了缓解经典autoencoder容易过拟合的问题,研究者提出在输入中加入随机噪声,Vincent在2008年的论文《Extracting and Composing Robust Features with Denoising Autoencoders》中提出autoencoder的改良版Denoising AutoEncoder(DAE)。工作原理如下:以一定的概率分布(通常是二项分布)去除原始input矩阵,每个值随机设置0,这样丢失了部分数据,将丢失数据的均值x计算y,并计算z,将z与原始的x做误差迭代,使得网络更新了损失(corruputed).
这种加入破损数据的方法优点:
- 通过和非破损数据对比,破损数据训练出来的weight噪声小,随机设置0时部分噪声会被消除
- 破损数据降低了训练数据和测试数据的误差,数据被随机初始化后,破损的数据比较接近测试数据,训练的weight鲁棒性更好
3、bert、DAE与Masked language model的关系
- Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences. In all but a few cases, however, such attention mechanisms are used in conjunction with a recurrent network.
-
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
- 一个模型架构避免了递归,而完全依赖于一个注意机制来绘制输入和输出之间的全局依赖关系。
bert 是一种基于transformer encoder 来构建的模型,整个架构基于DAE(Denoising autoencoder,去噪编码器),bert文章中称为masked language model。MLM并非严格意义上的语言模型,因为训练过程并不是利用语言模型来训练的,bert随机把部分单词mask标签来代替,接着预测被mask的单词,这个过程和DAE类似。bert有两个训练好的模型,bert-small和bert-large,bert-large使用了12层的encoder结构。
bert存在的问题,例如不能用来生成数据,bert本身依赖于DAE结构训练,不像基于语言模型训练的模型具备很好的生成能力,NNLM,ELMO是基于语言模型生成的,用训练好的模型可以生成出一些句子、文本等,基于生成模型的方法存在问题,只考虑了语言的上文,没有考虑下文,理解一个单词要在上下文中理解。
bert预训练过程:一个是masked language model(MLM),一个是next sentence predicition(NSP),在训练bert的时候,两个任务同时训练,bert的损失函数是把两个任务的损失函数加起来,属于多任务训练。
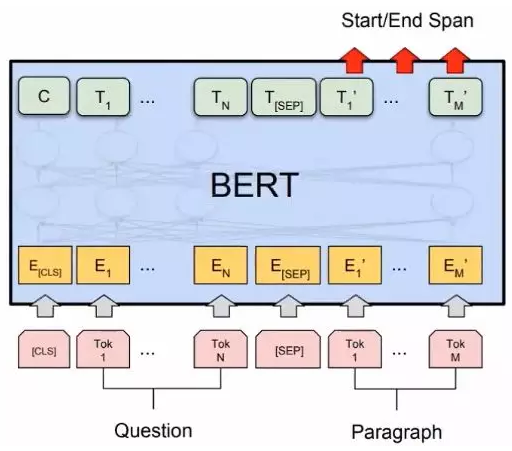
4、bert的使用场景
classification
【1】Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
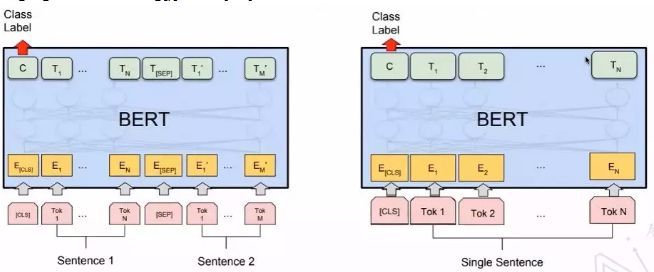
questions & answering
【1】Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.

具体信息可以参看:Bert时代的创新(应用篇):Bert在NLP各领域的应用进展 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/68446772
named entity recognition (NER)
BERT论文提到:
【1】Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.

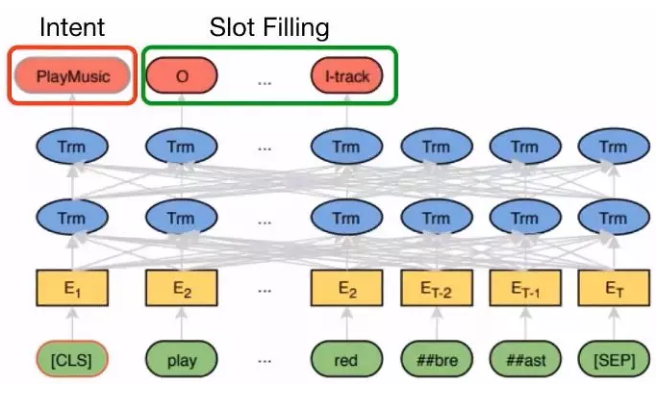
chat bot( intent classification & slot filling)
相关论文:
【1】Chen Q, Zhuo Z, Wang W. Bert for joint intent classification and slot filling[J]. arXiv preprint arXiv:1902.10909, 2019.
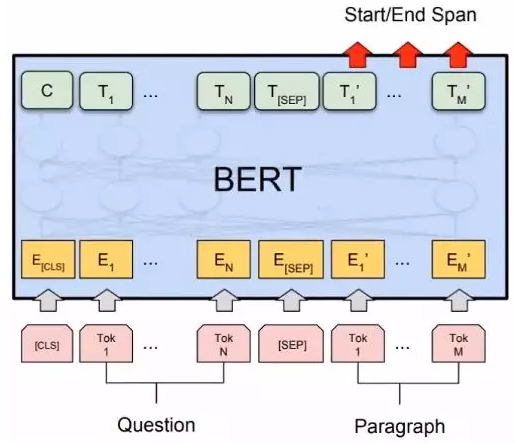
read comprehension