NLP 基本知识
NLP问题主要是对字词、短语、句子、篇章的处理,这一切问题主要包含两个层次:结构、语义。解决这些问题离不开两个基本概念:语言模型、序列标注。
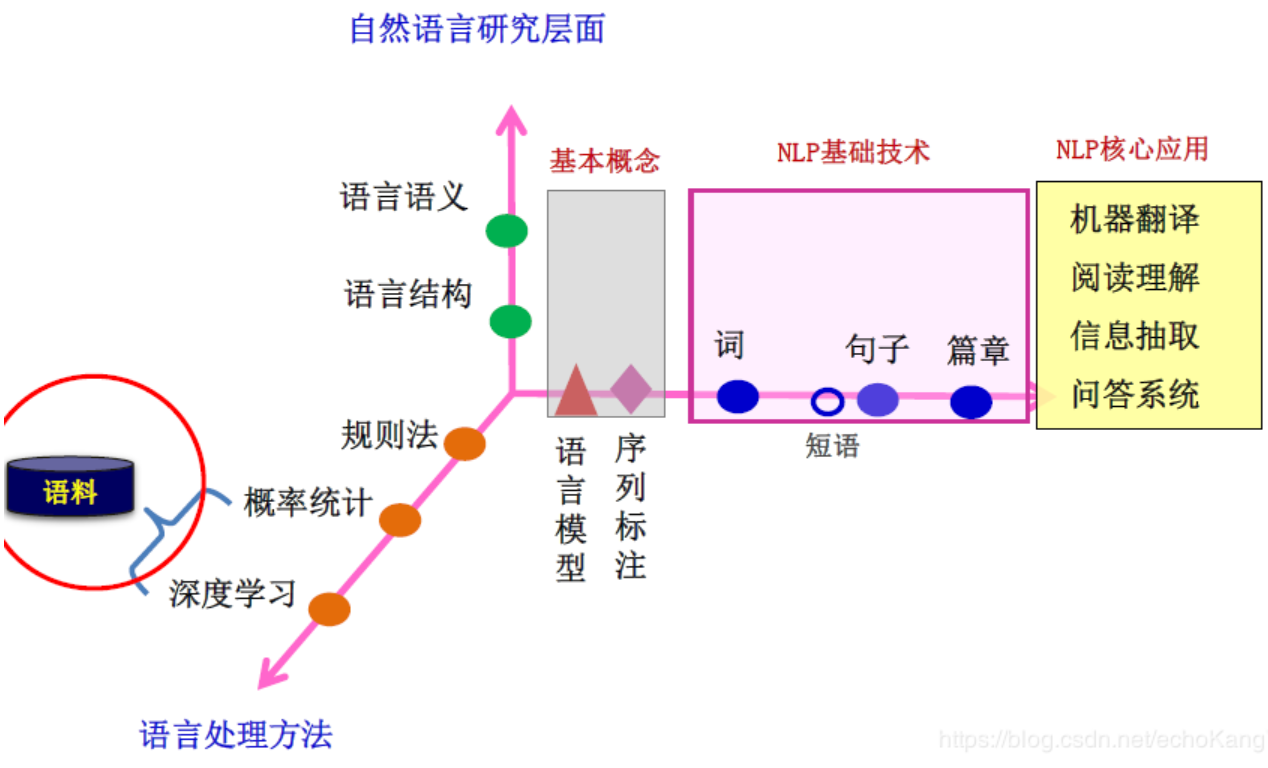
一、语言模型
语言模型是指用数学的方法描述语言规律,统计语言模型是用句子A出现的概率p(a)来刻画句子的合理性,常用的有 n-gram模型
二、词向量
离散的表示:one_hot ,词袋模型,TF-IDF
分布式表示:分布式表示,word2vec中的CBOW,skip_gram
哈夫曼树:一种带权路径长度最短的二叉树,也称最优二叉树。
三、序列标注
NLP许多任务可以转化为‘将输入的语言序列转化为标注序列’,例如命名实体识别,词性标注
常用方法:隐马尔可夫模型HMM,条件随机场CRF,神经网络与条件随机场结合 RNN+CRF
四、词性分析
词是语言处理的最小单位,词法分析是一切自然语言处理问题(句法分析,语义分析,文本分类,信息检索,机器翻译,机器问答等)的基础。词法分析的任务就是将输入的句子字串转换成词序列并标记出各词的词性。英语是曲折语,汉语是孤立语。
英语词法分析主要是英文词识别,词形还原;未登陆词识别;词性标注。汉语词法分析主要是分词;未登陆词识别;词性标注。
中文词法分析:1、自动分词(歧义问题、未登陆词问题、分词标准问题);2、词性标注(词性兼类歧义问题)。处理方法主要有规则法,概率统计法,深度学习法。成熟的分词系统,是综合不同的算法来处理不同的问题。
分词技术方法:1、基于字典、词库的规则分词方法(正向最大匹配、逆向最大匹配、最少切分法、双向最大匹配法),规则方法处理歧义能力较弱;2、基于统计的方法,根据字、词按照序列标注方法进行处理,处理歧义问题强,但需要大量标注(预处理)语料库的支持。3、深度学习方法,从句子获取的简单特征变为复杂的特征,从单一预料库单一标准的模型改进为可以利用多语料进行分词。
词性标注:主要问题是词性兼类问题(多义词),词性标准问题可以转化为序列标注问题来解决。
词法分析,现阶段主流方法是将其转化为序列标注问题。
五、句法分析
句法分析的任务是确定句子的句法结构或句子中词汇的依存关系,分为完全句法分析、局部句法分析、依存关系分析。
完全句法分析:文章经过词法分析后,通常用短语结构树表示,通过层次分析法可以构建短语结构树。

层次分析是利用语言学方法,从句子结构层面进行分析,1、将句子划分为主谓宾定状补等成分;2、以词或词组作为划分成分的基本单位;3、根据六个成分的搭配排列按层次顺序确定句子的格局。一般以树结构表示结构,我们将其称为句法分析树,找到主谓宾主干,其他成分作为枝叶。
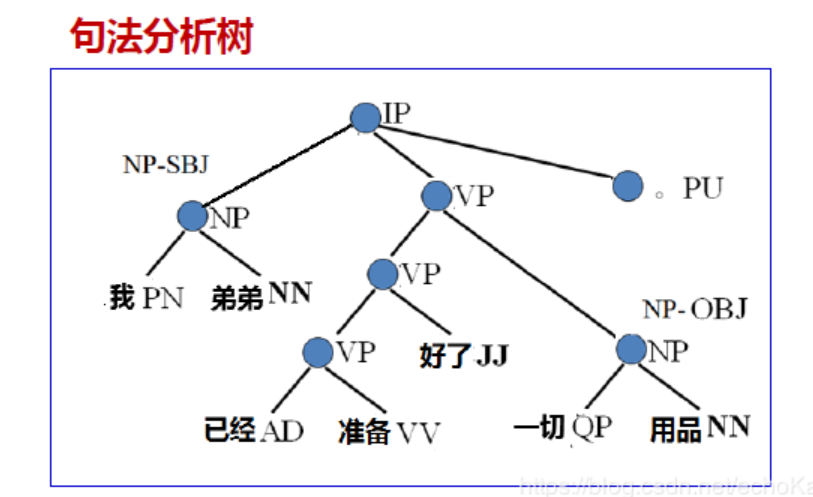
层次分析法面临问题:一个词类可以做多个句法成分,容易造成歧义/多义。
解决方法:Chomsky形式文法,根据重写规则的形式,将形式文法分为4级:0型文法(无约束文法),1型文法(上下文有关文法),2型文法(上下文无关文法),3型文法(正则文法),多级文法关系如下所示:

通过Chomsky形式文法作为刻画语言规律,表示语言的形式文法。从描述能力上,正则文法描述能力弱,上下文有关文法计算复杂度高,上下文无关文法使用较普遍。
句法分析系列详细文章:完全句法分析;局部句法关系、依存关系分析
六、语义分析
语义分析包含:词汇级语义分析、句子距语义分析
词汇及语义分析:1、语义消歧;--基于贝叶斯分类器的词义消歧方法、基于最大熵、互信息的消歧方法;上下文特征选取概率最大的结果;2、词语相似度;通过词向量计算词语距离。词语相似性反映词语聚合特点,词语相关性反映词语组合特点。
句子级语义分析:浅层语义分析和深层语义分析。浅层语义分析主要是语义角色标注
语义分析详细文章:语义分析