今天我们来搞一下Boss直聘网,试着拿一下工作相关的信息,有助于ITer们在找工作的时候,做决策分析。
说一下思路,跟之前做的小练习,动态爬取中国图书网相比,Boss直聘的网站是采取REST风格的GET请求,我们首先看一下第一页,query=‘java’的请求URL:
Request URL: https://www.zhipin.com/c101280600/h_101280600/?query=java&page=1&ka=page-1
尝试着爬取深圳地区(101280600)的java工作信息,当然如果想要搜索其他职位也是可以的。
首先老规矩观察一下chrome开发者模式中的各项参数,尤其是Response返回的一系列参数,我要需要这些参数来做浏览器模拟登陆。
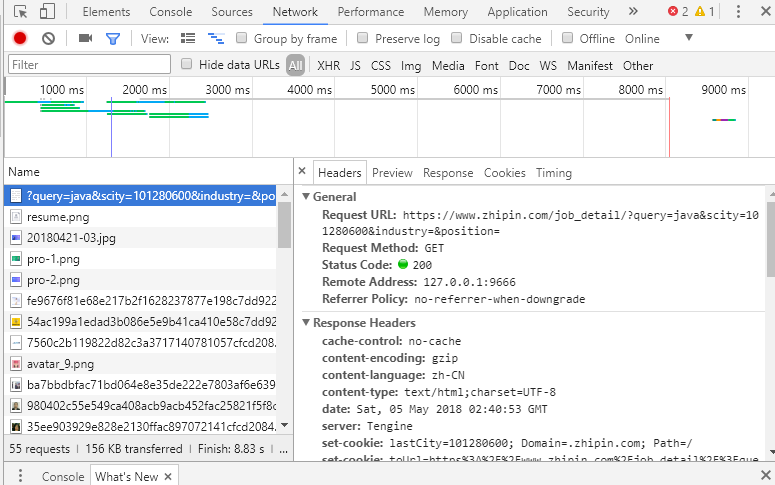
写好需要模拟浏览器登录的header后,我们分析一下拿下一页数据的操作,发现直接改变Url参数就可以跳转到下一页,
因此跳转到下一页代码:
url = "https://www.zhipin.com/c101280600/h_101280600/?" # 深圳地区编号101280600 paras = 'query=' + language + '&page=' + str(page) + '&ka=page-' + str(page)
只需要修改__main__方法的参数,可以控制要读的页数,以及要搜索的职位关键字:
if __name__ == '__main__': main('java',3)
对于首页的DOM, 我决定用熟悉的 漂亮的汤 来进行解析,通过对网站的DOM源码分解,我们找到了对应需要的一些信息的<tags>,
并且拿到我们想要的职位名称,薪资,学历,以及工作年限;
观察一下Boss直聘的DOM,发现想要的数据比较好拿;
如图都放在<li>里面:
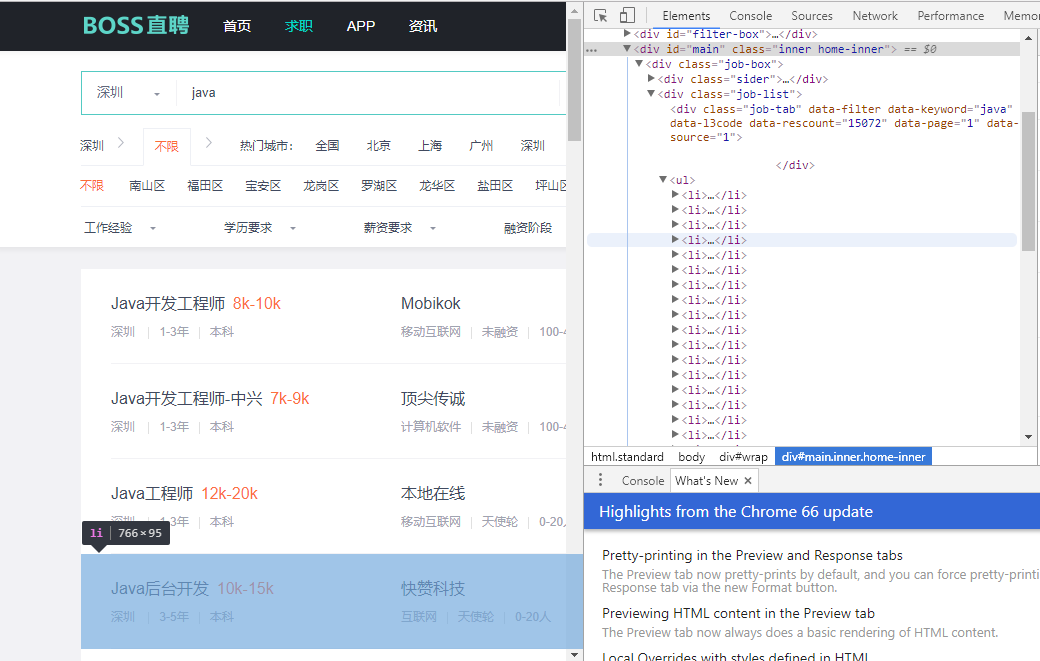
对应的BeautifulSoup代码:
response = requests.get(newUrl, headers = header, proxies = proxy ) soup = BeautifulSoup(response.text, "html.parser") for item in soup.select("div .job-list ul li"): job_title = item.select("div .job-title")[0].text job_detail = 'http://www.zhipin.com'+ item.select("div .info-primary a")[0].get('href') job_salary = item.select('div .info-primary span')[0].text job_requirements = item.select('div .info-primary p')[0].text.replace("深圳 ", "") job_diploma = job_requirements[-2 : len(job_requirements)] # 拿最后两位 job_years = job_requirements.replace(job_diploma,"") job_info = {"职位": job_title, "薪资": job_salary, "学历": job_diploma, "工龄": job_years}
单击选中的job后,可以进入到job的详细信息,其中包括公司的详细信息,岗位要求,任职要求等信息。其实如果能熟练使用bs去解析,我还是更倾向于用漂亮的汤。
但是为了练习,我们尝试用正则表达式去拿我们需要的岗位要求等信息,在py中需要引入re这个包。
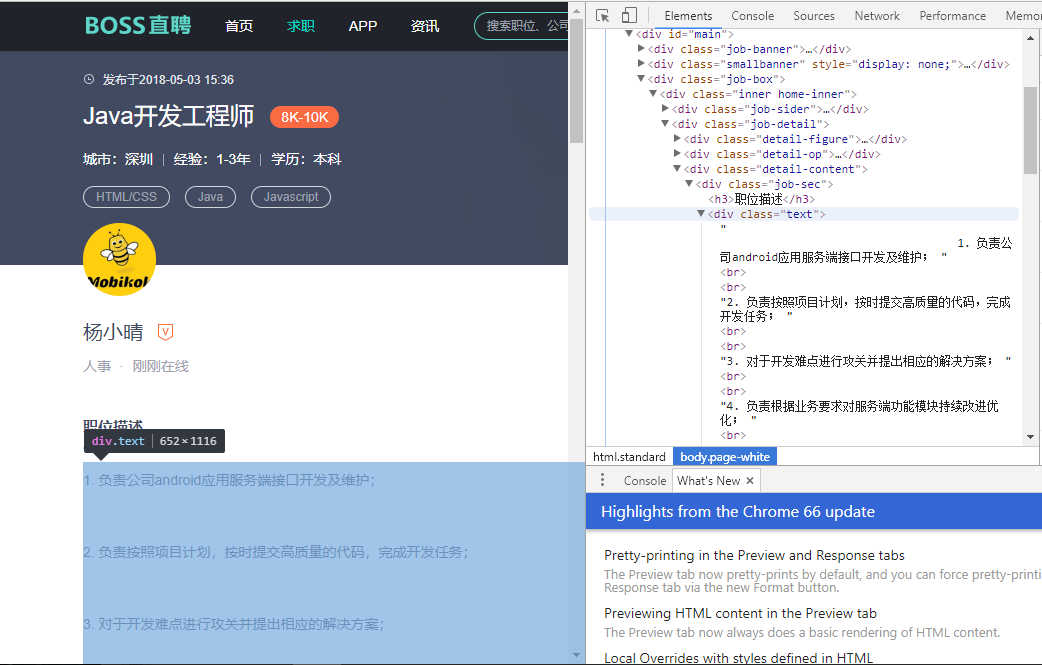
通过对DOM的分析,我们发现所需要的职位描述等信息,都保存在<div class="text">内,所以我们先用正则直接拿这个div内的信息,Tip:在正则表达式编辑过程中用(.*?)表示
自己需要的内容,可以先调用re.compile('regax...')编译了正则表达式后,再用re.findall()方法去拿需要的值。因为后面我们想通过岗位需求内的数据做词频分析,所以也做了数
据清洗 。
response = requests.get(url,headers = header) regax = re.compile('<div class="job-sec">.*?<div class="text">(.*?)</div>',re.S) result = re.findall(regax, response.text)[0] # 拿到任职要求等信息 filtedData = re.findall(r'[一-龥]+',result) # 拿到清洗过的数据,存在数组中
然后我们想把job对应的信息存入excel表格,以及需要进行词频分析的数据,存入txt文件,对应的方法在上一篇以及记录啦。
在程序写到一半的时候,突然发生一个致命的问题,因为访问次数过多,Boss官网把我的Ip给封了。。。
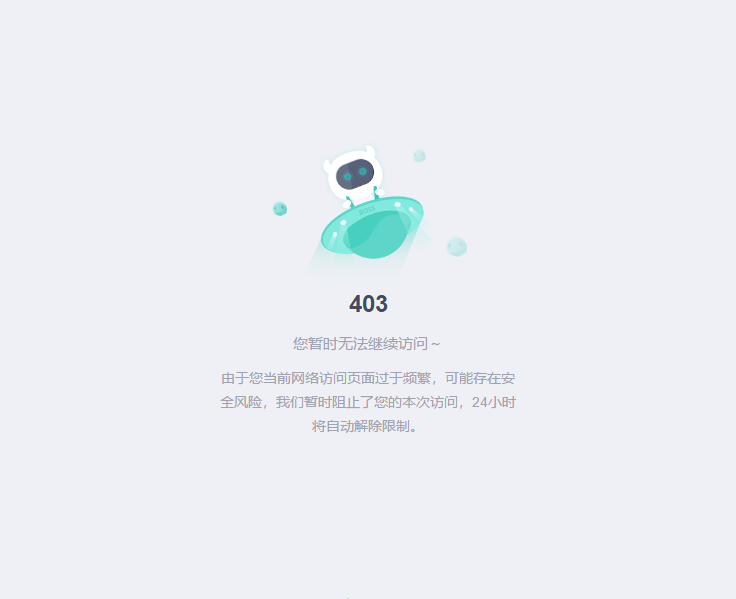
好尴尬,在网上查了一下,发现爬虫程序很多都是挂代理来抓别人数据的。。。所以,我们就先去抓代理网站的代理ip :-)
在网上搜了搜,有很多免费的代理ip池,我们就去抓取一部分ip,生成自己的random ip池。
这样。。我们就需要首先去爬下代理ip网站的ip地址喽:
def get_ip_list(url, headers): web_data = requests.get(url, headers=headers) soup = BeautifulSoup(web_data.text, 'lxml') ips = soup.find_all('tr') ip_list = [] for i in range(1, len(ips)): ip_info = ips[i] tds = ip_info.find_all('td') ip_list.append(tds[1].text + ':' + tds[2].text) return ip_list def get_random_ip(ip_list): proxy_list = [] for ip in ip_list: proxy_list.append('http://' + ip) proxy_ip = random.choice(proxy_list) proxies = {'http': proxy_ip} return proxies def get_ip(): url = 'http://www.xicidaili.com/nn/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36' } ip_list = get_ip_list(url, headers=headers) proxies = get_random_ip(ip_list) return proxies
拿到生成的代理ip后,我们在每个request请求里,加上他:
proxy = get_ip()
response = requests.get(newUrl, headers = header, proxies = proxy )
进程池的部分我们就不多说啦,请看上回分解,我加了两个锁,分别锁csv文件的写入,以及txt文件的写入。
文本预处理:
之后我们对于已经收集过的数据,进行词频分析,首先要使用jieba这个包,jieba可以帮助分割中文字符,调用jieba的cut方法即可。在中文语言中,会有很多没有特殊意义的字词,比如,的,你,然后。。等等,我们想把这些词从我们的数据中去掉,要洗掉这些stopwords。首先我们需要google一下中文的stopwords.txt文件,里面会有很多连词,使我们需要去掉的,当然我们也可以在这个文件中添加我们自己想去掉的一些词,所以我们先试试把我们不想要的一些词从stopwords里面去掉。
def data_filter(path): content = read_txt_file(path) stopwords = {}.fromkeys([line.rstrip() for line in open('stopwords.txt')]) result = '' for word in content: if(word not in stopwords): result += word result = jieba.cut(result) result = dict(Counter(result)) # list字典,包含key与出现字词value for k,v in result.items(): print('%s%d' %(k,v))
然后打印出来,当然可以根据统计进行排序,做成统计图,这里就不多描述了
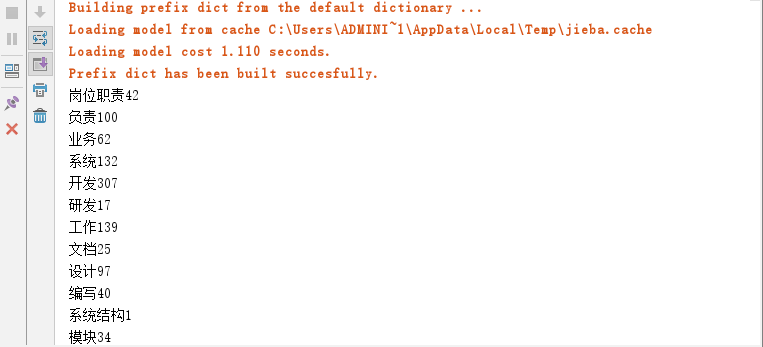
完整代码:
from bs4 import BeautifulSoup import requests import re import csv import multiprocessing import random import jieba from collections import Counter def get_one_page(lock1, lock2, language, page, title, path1, path2): ''' 第一页的Request URL: https://www.zhipin.com/c101280600/h_101280600/?query=java&page=1&ka=page-1 ''' url = "https://www.zhipin.com/c101280600/h_101280600/?" # 深圳地区编号101280600 paras = 'query=' + language + '&page=' + str(page+5) + '&ka=page-' + str(page) header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36', 'Host': 'www.zhipin.com', 'Referer': 'https://www.zhipin.com/', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9' } newUrl = url+paras proxy = get_ip() response = requests.get(newUrl, headers = header, proxies = proxy ) soup = BeautifulSoup(response.text, "html.parser") print(multiprocessing.current_process().name + ' ' + newUrl) #显示进程拿url的情况 for item in soup.select("div .job-list ul li"): job_title = item.select("div .job-title")[0].text job_detail = 'http://www.zhipin.com'+ item.select("div .info-primary a")[0].get('href') job_salary = item.select('div .info-primary span')[0].text job_requirements = item.select('div .info-primary p')[0].text.replace("深圳 ", "") job_diploma = job_requirements[-2 : len(job_requirements)] # 拿最后两位 job_years = job_requirements.replace(job_diploma,"") job_info = {"职位": job_title, "薪资": job_salary, "学历": job_diploma, "工龄": job_years} write_csv_rows(lock1, path1, title, job_info) # print(job_title, job_detail, job_salary, job_diploma, job_years) parse_detailed_info(lock2, job_detail, header, path2) # 交给另一个方法分析 公司详细信息 print(multiprocessing.current_process().name+ " complete!") def parse_detailed_info(lock, url, header, path): ''' 用正则来拿公司详细信息页面的 职位描述,任职要求等 ''' response = requests.get(url,headers = header) regax = re.compile('<div class="job-sec">.*?<div class="text">(.*?)</div>',re.S) result = re.findall(regax, response.text)[0] # 拿到任职要求等信息 filtedData = re.findall(r'[一-龥]+',result) # 拿到清洗过的数据,存在数组中 write_txt_file(lock, path, ''.join(filtedData)) def write_csv_headers(path, title): # write header of csv with open(path, 'a', encoding='gb18030', newline='') as f: f_csv = csv.DictWriter(f, title) f_csv.writeheader() def write_csv_rows(lock, path, title, rows): # write one row lock.acquire() with open(path, 'a', encoding='gb18030', newline='') as f: f_csv = csv.DictWriter(f, title) if type(rows) == type({}): f_csv.writerow(rows) else: f_csv.writerows(rows) lock.release() def write_txt_file(lock, path, txt): lock.acquire() with open(path, 'a', encoding='gb18030', newline='') as f: f.write(txt) lock.release() def read_txt_file(path): with open(path, 'r', encoding='gb18030', newline='') as f: return f.read() def scraping_data(language, page, title, path1, path2): pool = multiprocessing.Pool() lock1 = multiprocessing.Manager().Lock() # for csv lock2 = multiprocessing.Manager().Lock() # for txt for i in range(page): pool.apply_async(get_one_page, (lock1, lock2, language, i+1, title, path1, path2)) pool.close() pool.join() def get_ip_list(url, headers): web_data = requests.get(url, headers=headers) soup = BeautifulSoup(web_data.text, 'lxml') ips = soup.find_all('tr') ip_list = [] for i in range(1, len(ips)): ip_info = ips[i] tds = ip_info.find_all('td') ip_list.append(tds[1].text + ':' + tds[2].text) return ip_list def get_random_ip(ip_list): proxy_list = [] for ip in ip_list: proxy_list.append('http://' + ip) proxy_ip = random.choice(proxy_list) proxies = {'http': proxy_ip} return proxies def get_ip(): url = 'http://www.xicidaili.com/nn/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36' } ip_list = get_ip_list(url, headers=headers) proxies = get_random_ip(ip_list) return proxies def data_filter(path): content = read_txt_file(path) stopwords = {}.fromkeys([line.rstrip() for line in open('stopwords.txt')]) result = '' for word in content: if(word not in stopwords): result += word result = jieba.cut(result) result = dict(Counter(result)) # list字典,包含key与出现字词value for k,v in result.items(): print('%s%d' %(k,v)) def main(language, page): cvs_file_name = '深圳_' + language + '_jobInfo.csv' txt_file_name = language + '关键字数据库.txt' title = ['职位','薪资','学历','工龄'] write_csv_headers(cvs_file_name,title) scraping_data(language, page, title, cvs_file_name, txt_file_name) data_filter(txt_file_name) if __name__ == '__main__': main('java',10)