前言:
从写第一篇关于snap随笔的时候,我就有对此深入研究的想法,而上回和Kai.Ma 讨论了一下思路;也看到很多朋友的留言提到的采集服务,我还是决定把这些想法验证一下,看看采集速度,到底可以解决多少的问题.
思路:
首先要解决的问题是, webbrowser 运行在STA 模式下,每次采集都进行了构造和释放,所以首先避免这点,再就是,既然它是只能依靠主STA模式的线程运行的话,那就模拟多页面浏览器的机制,构造足够多的实例,让它们同步执行,然后及时地给它们派发消息,那么只要服务器带宽和内存都足够的情况下,它们可以最大程度降低并发采集所带来的性能问题.
测试 10 次结果:
目前刚出的测试结果:
输入:3百多个页面的链接,通过google搜索的,范围大。
输出:250 个页面预览图 (平均)
耗时:5分钟 (平均)
内存占用: 255兆(峰值)
并发:50
无法访问的页面数:79页(平均)
处理速度(250-79):1页/1.75秒(平均)
硬件配置:
操作系统:Windows Vista Ultimate 6000
CPU:1.73 pm
内存:1GB
硬盘:60GB+80GB
显卡:ATI X700(256)
带宽: 网通 ADSL (200K/秒)下载
运行状态: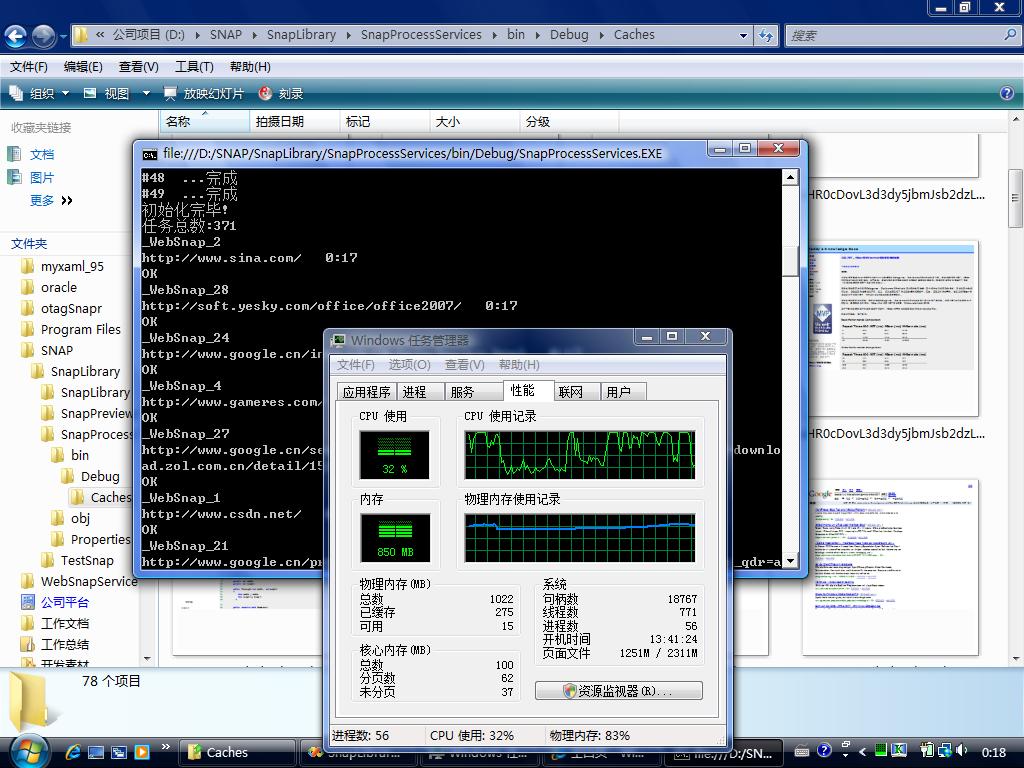
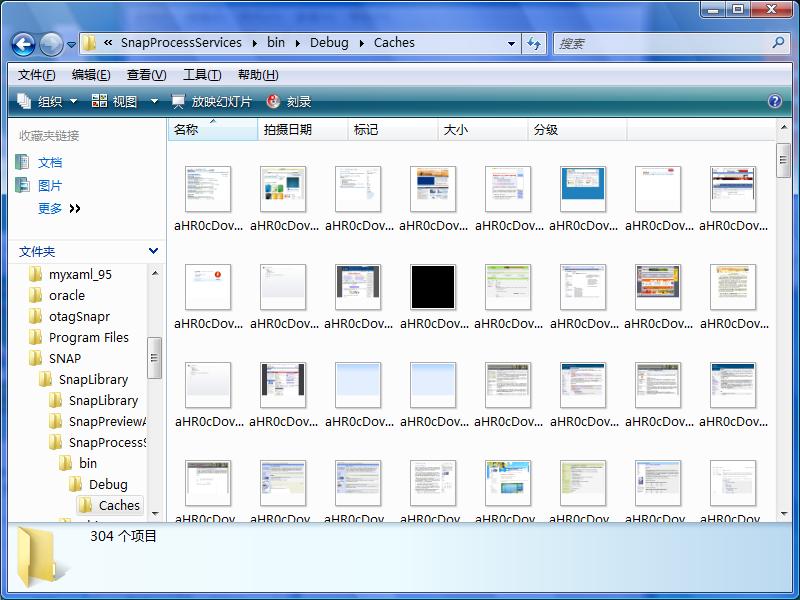
这类采集有几个问题是硬伤:
1.我只知道通过webbrowser来实现页面图
2.目标网站的连接下载页面速度
在服务稳定之后,将开放源码.并研究多机负载和一个站点的实例。
休息了,本来说好10点半睡得。。
2006年12月30日1:17:06