字符编码
在计算机中存放的都是二进制,而人类能识别的是字符。由二进制数字到字符必须要经历一个转换过程。
文字符号转换成数字称为编码encode。将数字转换成字符的过程叫解码decode。
字符编码表
转换的过程参照一张表,这张表就是字符编码表,上面记录一个字符对应的一个数字。
字符编码表的发展历程
1、一家独大
现代计算机起源于美国,所以最先考虑仅仅是让计算机识别英文字符,于是诞生了ASCII表。
ASCII码表:
只能识别英文字符,用8bit位对应一个英文字符。
几个常见字母的ASCII码大小: “A”为65;“a”为97;“0”为 48。
2、诸侯纷争,天下大乱
各个国家为了计算机能识别本国字符,都建立了属于本国的编码表。这些编码表都会兼容ASCII码。
GBK:
国标编码。能识别中文和英文,用16个bit(2Bytes)对应一个字符。一个英文字符对应1Bytes。
shift-JIS
能识别日文和英文。
Euc-KR
能识别韩文和英文。
这个时候各个国家虽然都有自己的编码表,但本国的计算机只能识别本国的字符和英文字符,那么如果一个人用多国语言写了一篇文章,那么这篇文章是无法被计算机识别的。所以需要一种世界通用的标准,能包含世界各个国家的编码表,这就是Unicode编码表,也称万国码。
3、归于统一
Unicode
Unicode能兼容所有国家的字符,与全世界所有的字符编码都有映射关系。这样任意国家的字符可以转换成Unicode码,再通过Unicode转换成其他编码表。
常用的字符用16bit(2Bytes)对应一个字符, 起初用2个字节编码,后来用32bit位(4Bytes)编码。但如果整个文件都是英文字符,那么这样就会浪费存储空间,还好现在存储设备越来越便宜,浪费空间这点还能忍受。可如果用Unicode编码写入硬盘,会增加I/O操作,降低读写速度,这个是不能接受的。所以后面又出现了utf-8。
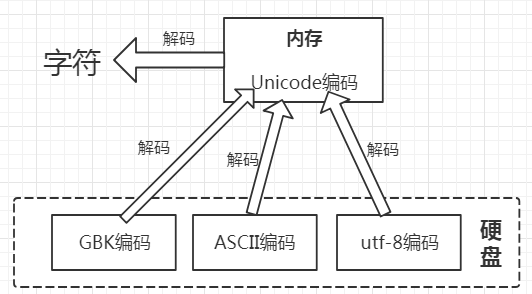
使用Unicode计算机可以接收任意国家的字符,不会出现字符无法识别乱码的问题。目前计算机字符存在内存中固定都是以Unicode编码存储的,从内存中写入硬盘中则以非Unicode编码存储。
utf-8
全称Unicode Transformation Format。Unicode的优化版本,用一个字节对应一个英文字符,用三个字节对应一个中文字符,将数据量控制到最精简。这样就解决了Unicode浪费空间和增加I/O的问题。
文件的写入
在诸多文件类型中,只有文本文件的内存是由字符组成的,因而文本文件的存取也涉及到字符编码的问题。
字符存在内存中都是以Unicode编码存储的,从内存中存入硬盘中则以非Unicode编码存储(具体编码格式可以在保存文件时指定),这就需要将Unicode编码格式转换为其他编码格式。
从字符转换为Unicode编码格式和Unicode编码格式转换为其他编码格式的过程称为编码encode。
不同编码格式之间不能相互识别。内存中所有字符都是是以Unicode编码的,除了bytes类型文件。但是当你的数据用于网络传输或者存储到硬盘中必须以非Unicode编码(utf-8,gbk等等)

文件的读取
文件在存入硬盘时用的可能是各种编码,但从硬盘读入内存要转成Unicode编码。从其他编码专为Unicode编码和从Unicode编码转为字符这两个过程都称为解码decode。
bytes类型
bytes类型是Python的基础数据类型之一,本质上是二进制,是将非Unicode编码的二进制进行封装,以16进制方式显示。
将Unicode格式编码成其他格式。
s = '字'
res = s.encode('utf-8')
print(res,type(res))
b'xe5xadx97' <class 'bytes'>
x表示16进制,一个16进制正好对应一个字节,uff-8编码就是用三个字节保存一个汉字。
将其他编码格式解码成Unicode编码。
s = b'xe5xadx97'
res = s.decode('utf-8')
print(res,type(s))
字 <class 'str'>
乱码问题
1、写入时乱码。
写入硬盘时没有使用能正确编码文件字符的编码表,比如用日文的shift-JIS保存韩文,就不能正确编码。导致在写入时就已经乱码,这样的乱码无法恢复,文件已经丢失。
# 正确编码过程
中文、英文 ---Unicode---> 内存 ---gbk---> 硬盘
# 错误编码过程
中文、英文 ---Unicode---> 内存 ---shift-JIS---> 硬盘
# 这样会导致中文部分无法正确编码,在写入时文件已经丢失,无法恢复。
解决方法:存入硬盘时选用能正确编码文件字符的编码表。目前都默认使用utf-8,这样无论输入任何国家的字符都能正确存入。
2、读取文件时乱码。
写入时没有乱码,但读取时没有使用与存入时相同的编码表导致乱码。这时文件还存在,只是读取乱码。
解决方法:存取都用同一种字符编码表。
Python解释器运行程序的三个步骤
1、先启动解释器。
2、解释器将代码文件从硬盘读取到内存,此时解释器会读取第一行内容,来决定以什么编码格式将文件读入内
存,而其他内容全部为普通字符,没有语法意义。
3、解释器先检查代码文件的语法,然后从左至右、从上往下逐行解释执行。
要修改解释器读取文件使用的编码格式,文件的第一行要写成特殊的注释,用来指定读取文件时的编码格式。
# -*- coding: 编码格式 -*-
或者这种方式
# coding:编码格式
关于 第一行 规则的一种例外情况是,源码以 UNIX "shebang" 行 开头。这种情况下,编码声明就要写在文件的第二行。例如:
#!/usr/bin/env python3
# -*- coding: cp1252 -*-
Python2和Python3中字符串类型的区别
Python2解释器
默认读文件使用的是ASCII编码。Python2中字符串类型在内存中是以读取文件时第一行指定的编码存储,str类型等于bytes类型。
Python3解释器
默认读文件使用的是utf-8编码。字符串在内存中是直接以Unicode的编码存储。打印Unicode相当于直接打印出字符串。
# 在字符串前面加上u表示是Unicode编码。
s = '字' # 相当于 s = u'字'
print(u'字') # 相当于print('字')
不同编码类型之间的转换
不同的编码类型直接无法直接转换,但所有的编码表在Unicode编码中都有映射,只要先将其他编码类型转换为Unicode编码格式,然后再通过Unicode编码格式转换即可。这个转换仅限于utf-8编码与其他编码表之间的转换,除了utf-8与Unicode编码表之外的编码,彼此直接无法正确转换。比如shift-JIS如gbk之间,两张表包含很多对方不具备的字符编码。
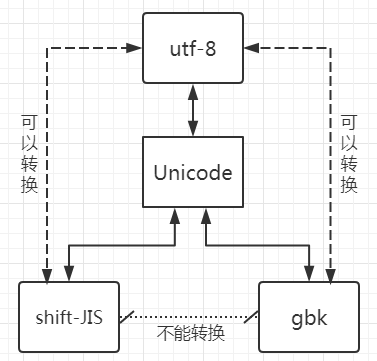
例如,将gbk转换为utf-8。
# 将中国编码为gbk
g = '中国'.encode('gbk')
print(g)
b'xd6xd0xb9xfa' # gbk一个中文占两个字节
# 将gbk解码为Unicode
un = g.decode('gbk')
print(un)
中国
# 将Unicode编码为utf-8
ut = un.encode('utf-8')
print(ut)
b'xe4xb8xadxe5x9bxbd' # utf-8一个中文占三个字节