总结:
0. 优化是为了 improve the training_loss; Regularization/ Ensembling is improving the performance on test data; Transfer learning 使得在样本量小的时候也可以使用CNN。
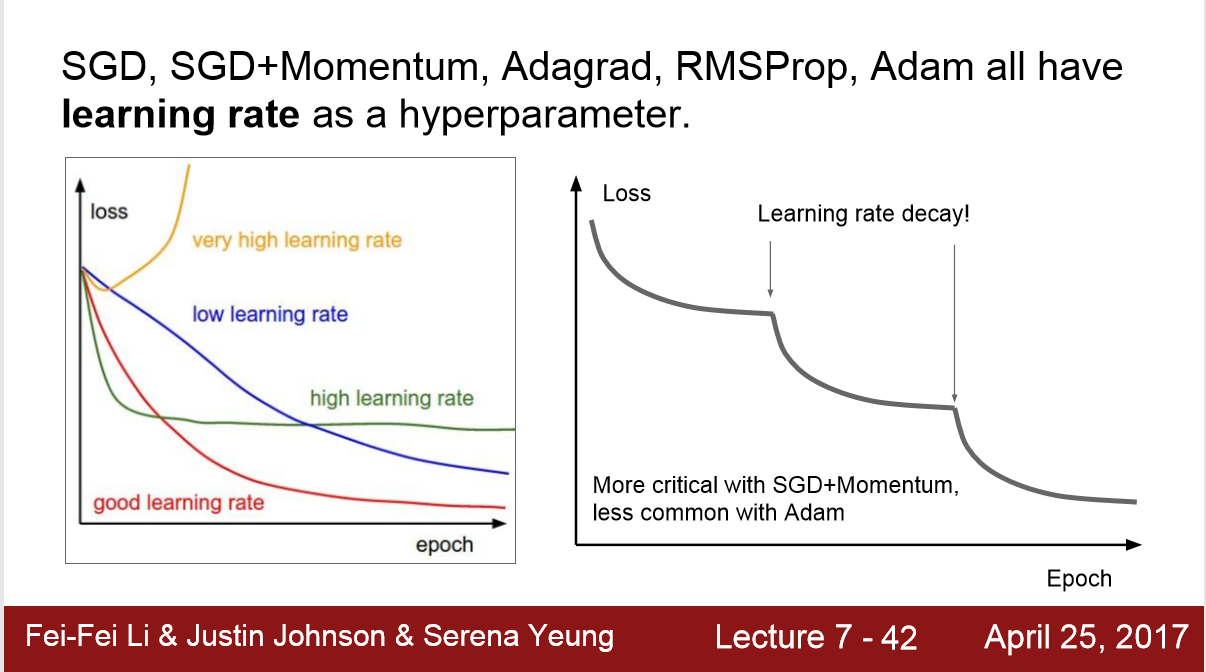
1. 一般使用Adam进行优化,设置 beta1 = 0.9; beta2 = 0.999; learning_rate = 1e-3 或 5e-4
2. 或者使用 learning_rate decay + SGD Momentum,先一遍不用learning_rate decay的图,再看从哪里开始decay
3. 改良过的优化算法比SGD+Momentum收敛更快
https://blog.csdn.net/willduan1/article/details/78070086


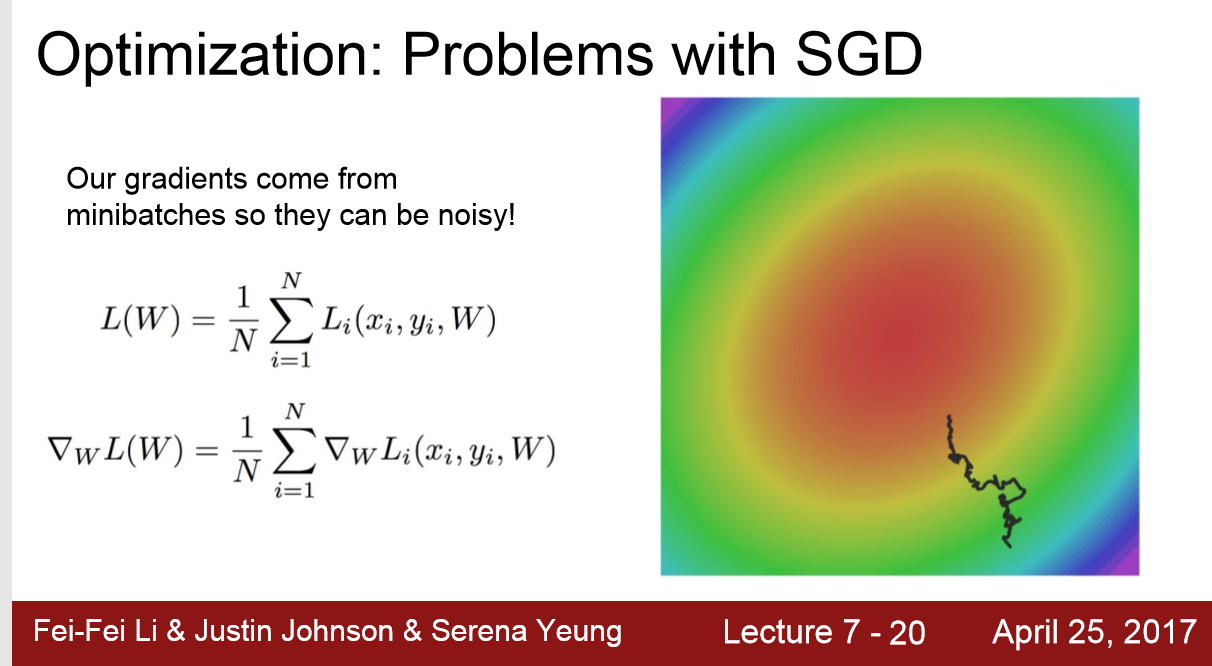
SGD的问题:
1. Loss 在某一个方向上下降很快,在另一个方向上较慢

2. 遇到局部最优,或者鞍点:斜率为0或者非常小,这样loss下降的会非常慢

3. 随机梯度下降来自于 随机的一个mini-batch,其最优梯度不一定代表全样本最优
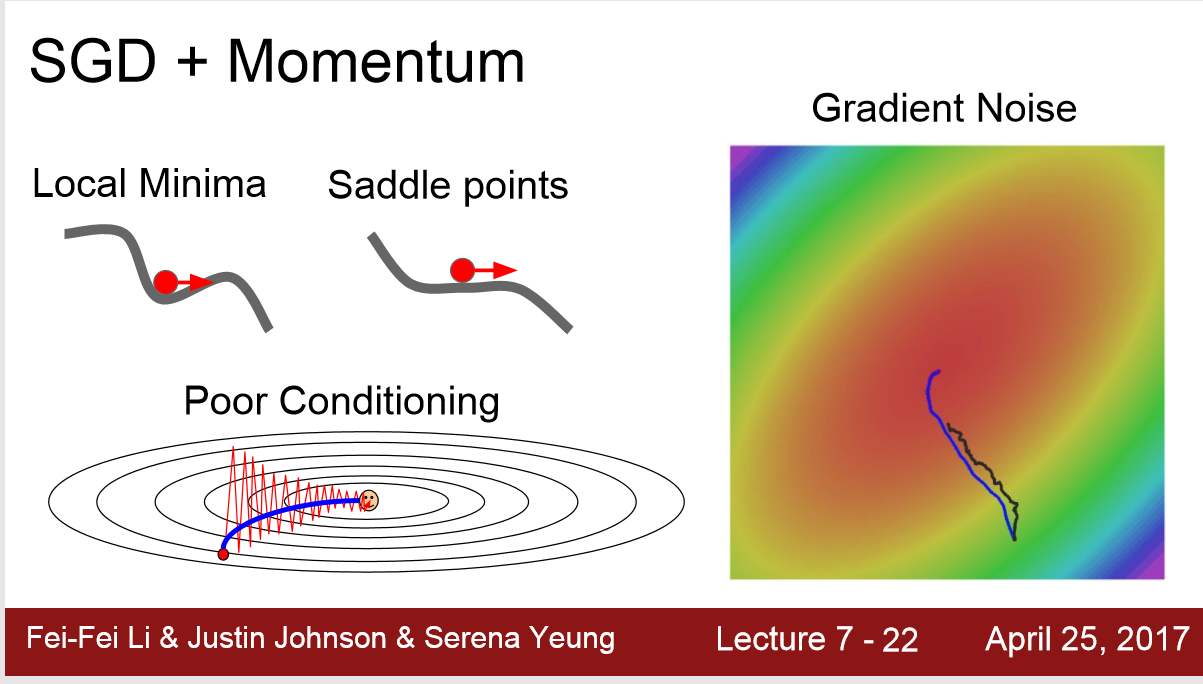
优化方法一: SGD+Momentum
加入一个动量项: 在第n+1次更新梯度时,保留0.9倍第n次的梯度,从而更新参数,降低loss

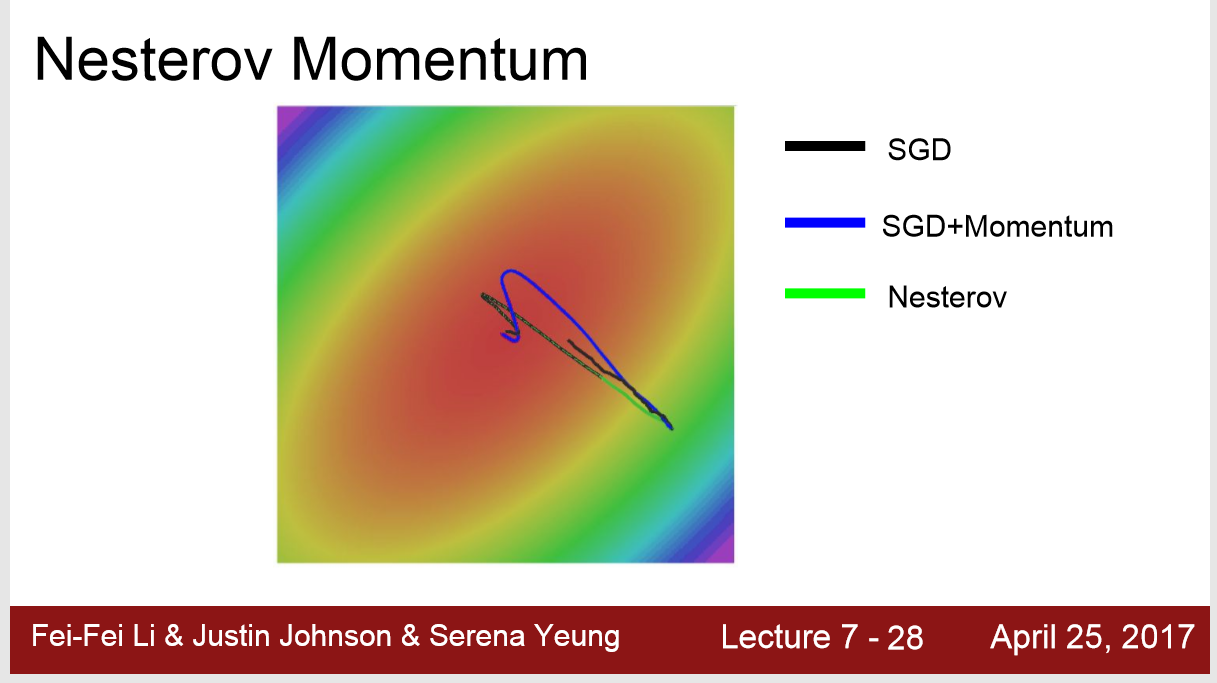
二:Nesterov Momentum

三: