SQL和RDBMS的区别:用SQL操作RDBMS
一、数据的完整性


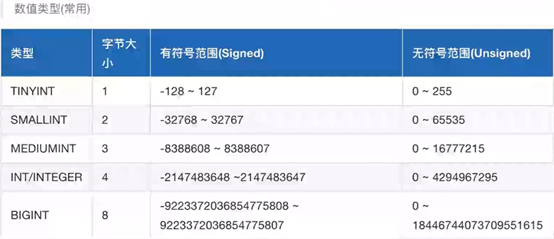

一个汉字占多少长度与编码有关:
UTF-8:一个汉字=3个字节
GBK:一个汉字=2个字节
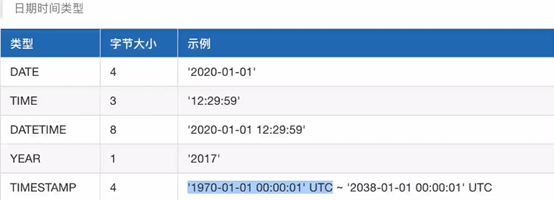
二、数据库基本操作
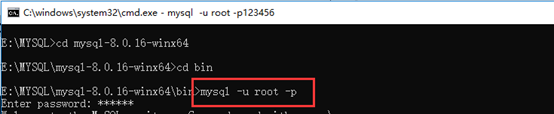
1、 登录数据库
首先进入mysql安装目录下的bin文件,然后运行命令:

2、退出登录:quit或者exit
3、 以分号或者g结束
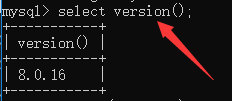
查看sql版本:select version();
查看当前时间:select now();
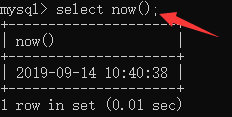
修改提示符:prompt 新的提示符
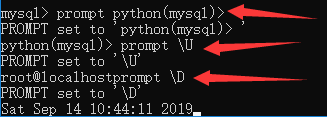
查看创建的数据库:show databases;
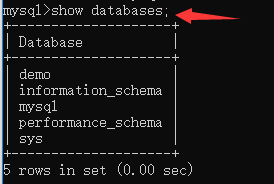
查看当前正在使用的数据库:select database(); --NULL值的是空
使用数据库:use demo;
创建数据库:create database 数据库名;
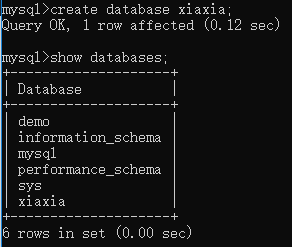
查看数据库的创建语句;show create database 数据库名称;

删除数据库:drop database 数据库名;

指定数据集:create database 数据库名 charset=utf8;

输出Mysql数据库管理系统的性能及统计信息:show table status from 数据库名;

三、数据表基本操作
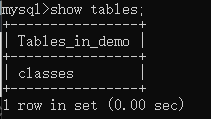
1、查看当前所使用的表:show tables;
使用该命令前需要使用 use 命令来选择要操作的数据库。
创建表:
create table 数据表名(字段名 字段类型 字段约束[,字段名 字段类型 字段约束])
例:CREATE TABLE student (
id INT UNSIGNED PRIMARY KEY auto_increment,
NAME VARCHAR(10) NOT NULL,
age TINYINT UNSIGNED DEFAULT 0,
high DECIMAL (5, 2) DEFAULT 0.0,
gender enum('男','女','中性','保密') DEFAULT '保密', --枚举值默认从1开始,在使用上是一样的
cls_id INT UNSIGNED NOT NULL );
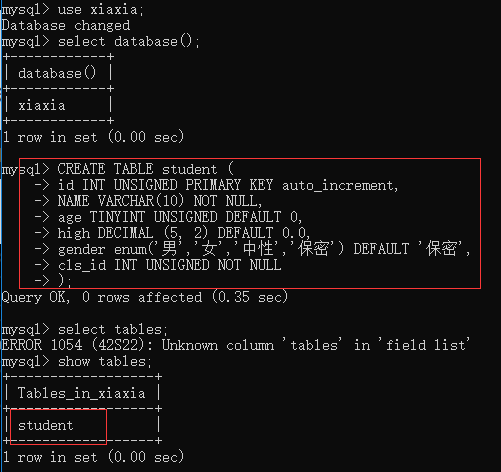
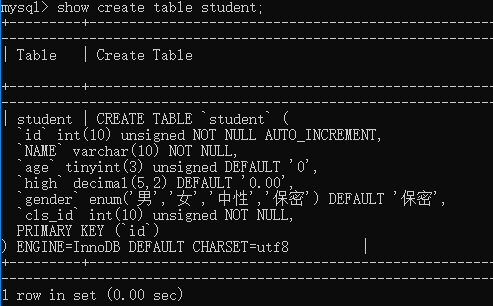
查看表的创建语句:show create table 表名;
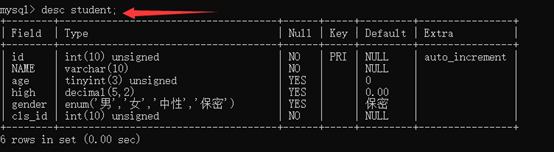
查看表结构:desc 表名 或 show columns from 表名;
显示数据表的详细索引信息,包括PRIMARY KEY(主键):SHOW INDEX FROM 表名:

修改表结构:alter add/modify/change
其中:alter是针对于不存在的字段,例如:添加字段名称
add/modify是针对于已经存在的字段,例如:修改字段类型
change:修改字段名和类型、约束
alter table 表名 add 新加字段 字段约束
例:alter table student add birthday datetime default “2011-11-11 11:11:11”

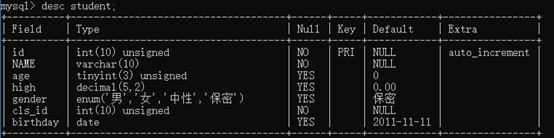
修改已经存在的字段的类型:
alter table student modify birthday date default "2011-11-11";
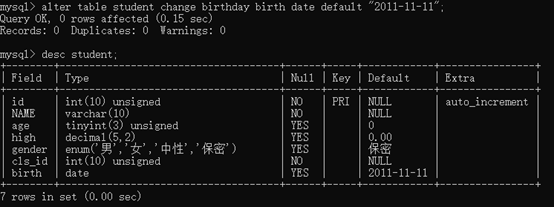
修改已经存在的字段名:
alter table student change 旧名称 新名称 date default "2011-11-11";
alter table student change birthday birth date default "2011-11-11";
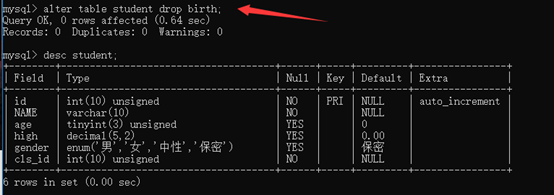
删除字段:alter table 表名 drop 字段名;
例:alter table student drop birth;
删除表:drop table 表名;
四、数据的增删改查
1、增加insert
(1)全列插入:值与表的字段顺序一一对应
(在实际开发中用的不多,如果表结构一旦发生变化,全列插入就会发生错误)
insert into 表名 values (值1,值2);
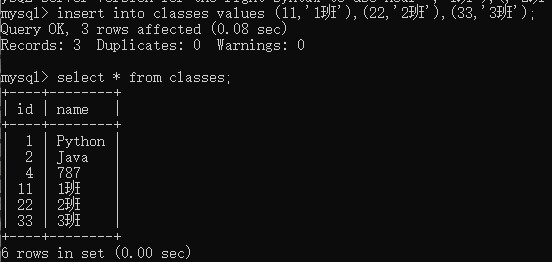
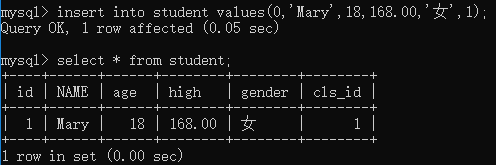
(2)指定列插入:
insert into 表名 (列1,列2,……) values (值1,值2,……)
insert into student (name,high,cls_id) values('夏夏',111,2);

(3)多行插入
insert into 表名 (列1,列2,……) values (值1,值2,……), values (值1,值2,……)
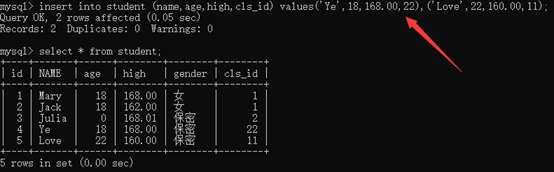
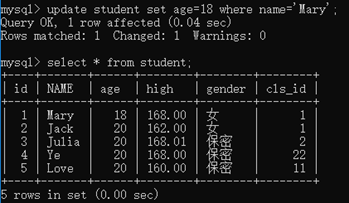
2、修改update
update 表名 set 列1=值1,列2=值2 [where 条件]
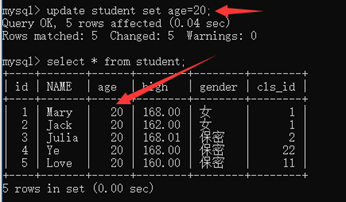
没有where进行条件限制就是全表更新
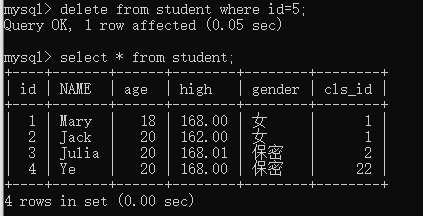
4、 删除delete
物理删除:delete from 表名 [where 条件判断]
delete from student; --会删除表内所有内容
where:数据库中常用的是where关键字,用于在初始表中筛选查询。它是一个约束声明,用于约束数据,在返回结果集之前起作用。
group by:对select查询出来的结果集按照某个字段或者表达式进行分组,获得一组组的集合,然后从每组中取出一个指定字段或者表达式的值。
having:用于对where和group by查询出来的分组经行过滤,查出满足条件的分组结果。它是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作。
执行顺序:select –>where –> group by–> having–>order by
五、数据的其它操作
1、UNION :用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions] UNION [ALL | DISTINCT] SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions];
参数
-
expression1, expression2, ... expression_n: 要检索的列。
-
tables: 要检索的数据表。
-
WHERE conditions: 可选, 检索条件。
-
DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
-
ALL: 可选,返回所有结果集,包含重复数据。
总结:
UNION 语句:用于将不同表中相同列中查询的数据展示出来;(不包括重复数据)
UNION ALL 语句:用于将不同表中相同列中查询的数据展示出来;(包括重复数据)
SELECT 列名称 FROM 表名称 UNION SELECT 列名称 FROM 表名称 ORDER BY 列名称; SELECT 列名称 FROM 表名称 UNION ALL SELECT 列名称 FROM 表名称 ORDER BY 列名称;