学习记录自苗大和煎鱼
维基百科
Data structure alignment refers to the way data is arranged and accessed in computer memory. It consists of three separate but related issues: data alignment, data structure padding, and packing.
The CPU in modern computer hardware performs reads and writes to memory most efficiently when the data is naturally aligned, which generally means that the data's memory address is a multiple of the data size. For instance, in a 32-bit architecture, the data may be aligned if the data is stored in four consecutive bytes and the first byte lies on a 4-byte boundary.
Data alignment refers to aligning elements according to their natural alignment. To ensure natural alignment, it may be necessary to insert some padding between structure elements or after the last element of a structure. For example, on a 32-bit machine, a data structure containing a 16-bit value followed by a 32-bit value could have 16 bits of padding between the 16-bit value and the 32-bit value to align the 32-bit value on a 32-bit boundary. Alternately, one can pack the structure, omitting the padding, which may lead to slower access, but uses half as much memory.
Although data structure alignment is a fundamental issue for all modern computers, many computer languages and computer language implementations handle data alignment automatically. Ada,[1][2] PL/I,[3] Pascal,[4] certain C and C++ implementations, D,[5] Rust,[6] C#,[7] and assembly language allow at least partial control of data structure padding, which may be useful in certain special circumstances.
数据结构对齐是代码编译后在内存的布局与使用方式。包括三方面内容:数据对齐、数据结构填充(padding)与包入(packing)。
现代计算机一般是32比特或64比特地址对齐,如果要访问的变量没有对齐,可能会触发总线错误。
当数据小于计算机的字(word)尺寸,可能把几个数据元素放在一个字中,称为包入(packing)。
一个例子
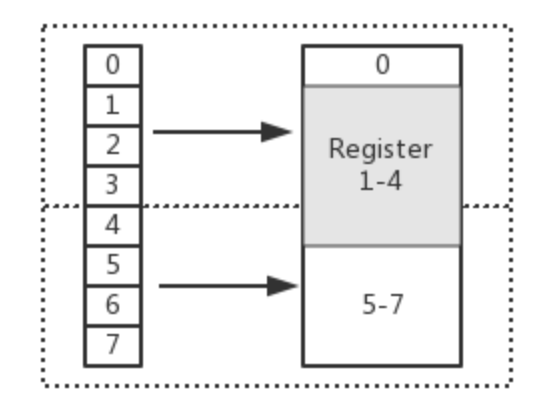
这就是没内存对齐,这就导致了我们取1-4花了两步。实际上我们很多都是默认开内存对齐的,那么还有什么研究的,可以稍微优化一些,比如下面这种。

type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
type Part2 struct {
c int8
a bool
e byte
b int32
d int64
}
func main() {
part1 := Part1{}
part2 := Part2{}
fmt.Println(unsafe.Sizeof(part1), unsafe.Alignof(part1))
fmt.Println(unsafe.Sizeof(part2), unsafe.Alignof(part2))
}
输出
32 8 16 8
Part1 axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
Part2 ecax|bbbb|dddd|dddd
位和字节和机器字应该了解,机器字是计算机用来一次性处理事务的一个固定长度,64是8个字节,32是4个字节。所以如果两个平台切换的话要主要保证64移植性。
再举一个例子
package main import ( "fmt" "unsafe" ) type A struct { arr [2]int8 // 2 数组主要取决于item slice []int8 // 24 切片看SliceHeader bl bool // 1 sl []int16 // 24 ptr *int64 // 8 指针类型64位是8个字节,32位是4个字节 st struct{ // 16 struct取决于字段 str string // string其实就是一个指针和一个int表示的len,所以8+8=16 } m map[string]int16 // map其实就是一个指针引用 i interface{} // interface实际是一个类型指针一个数据指针,9+8=16 } func main() { a := A{} // 2 1 fmt.Println(unsafe.Sizeof(a.arr), unsafe.Alignof(a.arr)) // 24 8 fmt.Println(unsafe.Sizeof(a.arr), unsafe.Alignof(a.arr)) // 1 1 fmt.Println(unsafe.Sizeof(a.bl), unsafe.Alignof(a.bl)) // 24 8 fmt.Println(unsafe.Sizeof(a.sl), unsafe.Alignof(a.sl)) // 8 8 fmt.Println(unsafe.Sizeof(a.ptr), unsafe.Alignof(a.ptr)) // 16 8 fmt.Println(unsafe.Sizeof(a.st), unsafe.Alignof(a.st)) // 8 8 fmt.Println(unsafe.Sizeof(a.m), unsafe.Alignof(a.m)) // 16 8 fmt.Println(unsafe.Sizeof(a.i), unsafe.Alignof(a.i)) }

string
// stringHeader is a safe version of StringHeader used within this package. type stringHeader struct { Data unsafe.Pointer Len int }
map
// A header for a Go map. type hmap struct { // Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go. // Make sure this stays in sync with the compiler's definition. count int // # live cells == size of map. Must be first (used by len() builtin) flags uint8 B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items) noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details hash0 uint32 // hash seed buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0. oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated) extra *mapextra // optional fields }
slice
// sliceHeader is a safe version of SliceHeader used within this package. type sliceHeader struct { Data unsafe.Pointer Len int Cap int }
interface
type iface struct { tab *itab data unsafe.Pointer } type eface struct { _type *_type data unsafe.Pointer }
final zero field
package main import ( "fmt" "unsafe" ) type T1 struct { a struct{} x int64 } type T2 struct { x int64 a struct{} } func main() { a1 := T1{} a2 := T2{} // 8 16 fmt.Println(unsafe.Sizeof(a1), unsafe.Sizeof(a2)) }
这里主要是考虑到我们后期会对T2.a这种情况引用,然而这正是边界地址,如果没有空间岂不是要操作到别的地址去了,所以go里对这种是默认加一段内存地址。
内存地址对齐,我们如何判断
https://golang.org/ref/spec#Package_unsafe
这里有比较详尽的解释。
大概我们可以用一个公式
uintptr(unsafe.Pointer(&a1)) % unsafe.Alignof(a1) == 0
就拿前面的图我们也可以理解
64字的访问安全保证
其实在32位中,对于64字采取的处理方式是两个32并排在一起,不然还能怎么办?所以这时候对64进行原子操作就会报错了,因为它是对地址的操作,64的原子操作不能在32上跑的,这里如何解决?
加锁吧。
总结(拿来主义)
至少我之前写代码是没考虑到这种层面的,但是感觉其实也并不深,基础良好应该不具备太多的困难,这更多的是基础改进工程方面的学习,解决go源码中的一些结构体的”对齐“疑惑。
https://eddycjy.gitbook.io/golang/di-1-ke-za-tan/go-memory-align