在Ubuntu14.04 64bit上搭建单机Spark环境,IDE为Intelli IDEA
一. 环境
Ubuntu14.04 64位
JDK 1.8.0_73
scala-2.10.4
spark 1.5.1 [此处注意Spark版本和Scala版本的兼容性问题]
IntelliJ IDEA 14.04
二. 安装JDK
1.从http://www.oracle.com/technetwork/java/javase/downloads页面下载JDK 1.8安装包,此处选择的是jdk-8u73-linux-x64.tar.gz
2.解压到软件希望安装的目录下
3.修改环境变量: sudo gedit /etc/profile
export JAVA_HOME=/home/cherish/program/java/jdk1.8.0_73 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
4.重新载入profile文件:
source /etc/profile
5.验证:
java, javac, java -version
三.安装scala
1.从http://www.scala-lang.org/download/2.10.4.html页面下载scala-2.10.4安装包
2.解压到软件希望安装的目录下
3.修改环境变量: sudo gedit /etc/profile
export SCALA_HOME=/home/cherish/program/scala/scala-2.10.4
export PATH=${SCALA_HOME}/bin:$PATH
4.重新载入profile文件:
source /etc/profile
5.验证:
scala, scala -version
四. 安装spark
1.从http://www.scala-lang.org/download/2.11.7.html页面下载spark安装包,这里我选择的是1.5.1版本的Pre-build for Hadoop2.6 and later.
2.解压到软件希望安装的目录下
3.修改环境变量: sudo gedit /etc/profile
export SPARK_HOME=/home/cherish/program/spark/spark-1.5.1-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH
4.重新载入profile文件:
source /etc/profile
五.安装IntelliJ IDEA
1.从http://www.jetbrains.com/idea/download/#section=linux页面下载IntelliJ IDEA安装包,此处选择的版本是14.04
2.解压到软件希望安装的目录下
3.下载插件
首先启动intelliJ IDEA:在命令行终端中,进入$IDEA_HOME/bin目录,输入sudo ./idea.sh进行启动,进入如下界面,然后选择右下角“plugins”
然后进入以下界面,点击Plugins,由于Scala插件没有安装,需要点击”Install JetBrains plugins"进行安装,如下图所示: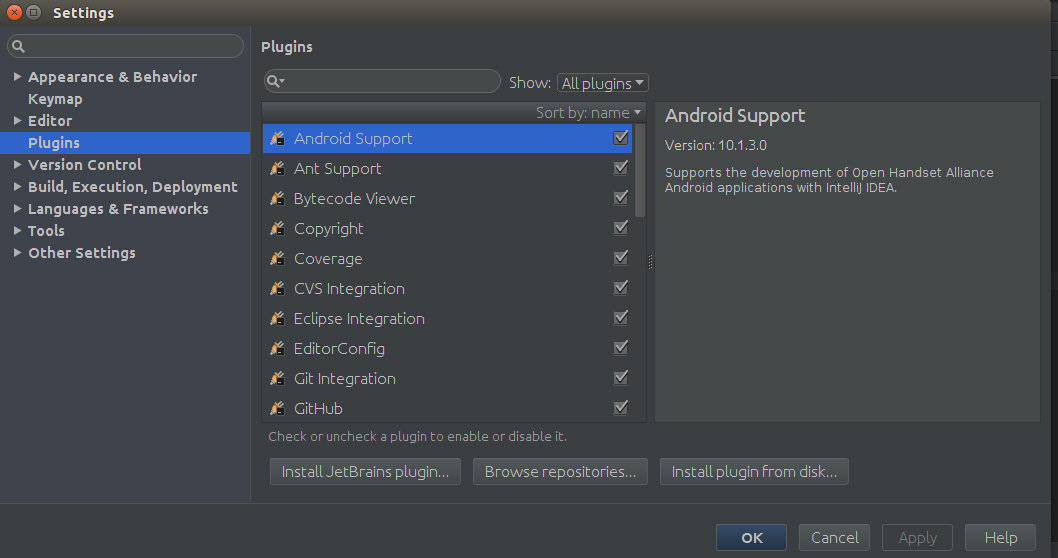
然后进入以下界面,点击下载,等下载安装好后,点击close就ok了
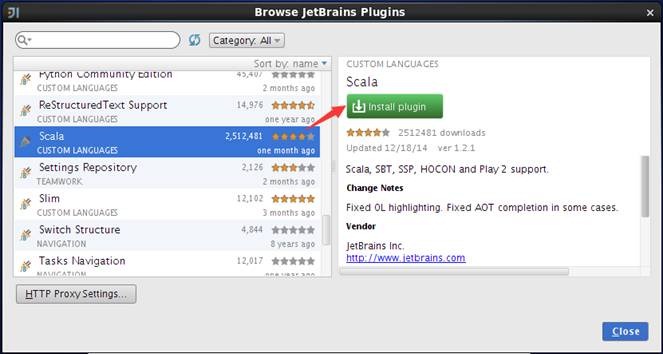
安装插件后,在启动界面中选择创建新项目,弹出的界面中将会出现"Scala"类型项目,如下图,选择scala-》scala
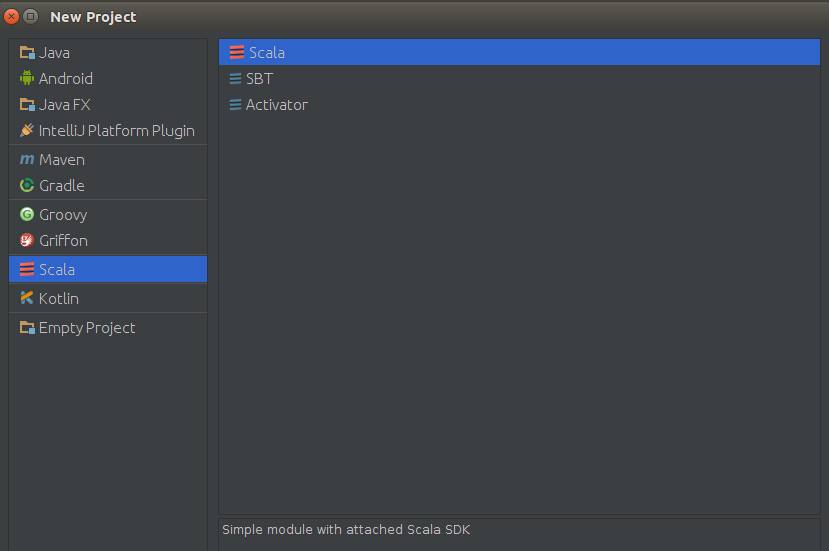
点击next,project name自己随便起的名字,把自己安装的scala和jdk选中,按照上面的安装过程,此处选的为jdk 1.8.0_73, scala-2.10.4!完成后,点击Finish
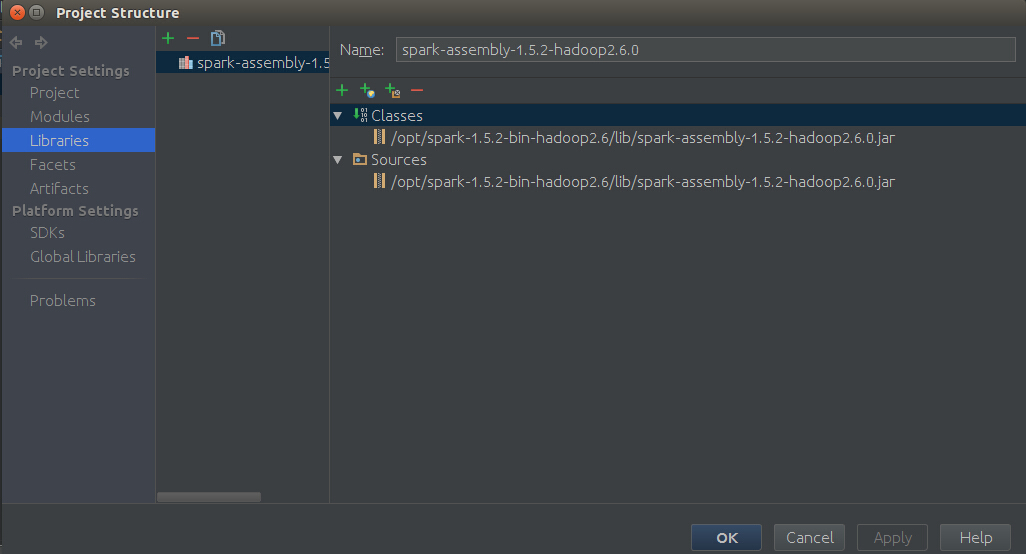
然后在IDE中File -> project Structure -> Libraries ->“+”,然后进入你安装spark时候解压的 spark-XXX-bin-hadoopXX下,在lib目录下,选择spark-assembly-XXX-hadoopXX.jar,结果如下图所示,然后点击Apply,最后点击ok
现在我们就可以在src下创建一个包,然后创建一个Scala Object,如下图,然后就可以用scala来编写代码了。
六. 测试整个开发环境
下面是一个测试小代码,单词计数,代码如下


1 package graphTest 2 3 import org.apache.spark.{SparkConf, SparkContext} 4 5 /** 6 * Created by root on 16-3-21. 7 */ 8 object myFirstScalaObject { 9 def main(args: Array[String]) { 10 val conf = new SparkConf() 11 conf.setAppName("world") 12 conf.setMaster("local") 13 val sc = new SparkContext(conf) 14 val lines = sc.textFile("/home/cherish/programData/test") //数据路径 15 val words = lines.flatMap{line => line.split(" ")} 16 val pairs = words.map{ word => (word,1)} 17 val wordCounts = pairs.reduceByKey(_+_) 18 wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2)) 19 sc.stop() 20 } 21 }
然后点击Run即可运行了。
此处运行时如果出现如下的报错信息,则表明Spark版本和Scala版本不兼容,需要更改scala的版本。但是在本文介绍的scala-2.10.4版本与spark 1.5.1版本是兼容的。
Exception in thread "main" java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
七. 感谢
Ubuntu spark 搭建_在Ubuntu14.04 64bit上搭建单机Spark环境
linux 系统下IntelliJ IDEA的安装及使用