1) Before you implement this project, Record your estimate about the time you WILL spend in each component of your program.
预计完成总时长:13.5h
| 预计项目 | 时长 | 具体内容 |
| 计划需求分析,软件安装 | 1.5h | 此步骤主要对课程博客要求进行阅读,下载并安装VS2012。 |
| 编写调试代码 | 8h | 此步骤用于根据软件需求编写C++程序,并进行调试。 |
| 设计测试用例,测试 | 2h | 对代码进行过程分析和功能分析,设计出相应用例,并测试(修正)。 |
| 书写博客 | 2h | 根据课程博客要求进行博客书写,总结项目经验,不断学习。 |
2) After you had implemented this project, record the ACTUAL time you spent in each component of your program.
实际完成总时长:63.5h
| 与预期相比 | 项目 | 实际时长 | 具体内容 |
| :) | 计划需求分析,软件安装 | 1.5h | 此步骤主要对课程博客要求进行阅读,下载并安装VS2012。 |
| :( | 编写调试代码 | 12h | 此步骤用于根据软件需求编写C++程序,并进行调试。 |
| :) | 设计测试用例,测试 | 2h | 对代码进行过程分析和功能分析,设计出相应用例,并测试(修正)。 |
| 新增 | 代码分析,性能优化 | 5h+25h(Week2) | 学习VS2012的代码分析功能,并依据报告修改程序,以优化性能。 |
| 新增 | 测试,对比结果 | 1h+3h(Week2) | 对优化代码进行正确性测试,对比性能分析报告,分析优化质量。 |
| :) | 书写博客 | 2h+2h(Week2) | 根据课程博客要求进行博客书写,总结项目经验,不断学习。 |
编写调试代码部分,预估时间和实际时间较大差距的原因:
不熟悉C++语言,需要不断地学习新的C++知识,例如:vector,pair等;不熟悉系统的调用,请教同学以及网上查阅资料才得以解决;需要时间适应新的软件;不熟悉C++的文件操作。
3) Describe how much time you spent on improving the performance of your program, and show a performance analysis graph (generated by VS2012 perf analysis tool), if possible, please show the most costly function in your program.
优化代码一共花费6h,代码分析,性能优化:5h+测试,对比结果:1h。
【更新】优化代码一共花费34h,代码分析,性能优化:30h+测试,对比结果:4h。
【更新】将Week1和Week2的优化整理在一起
第一次优化过程:
优化前:
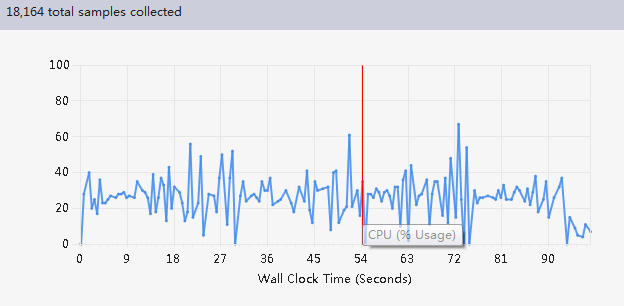


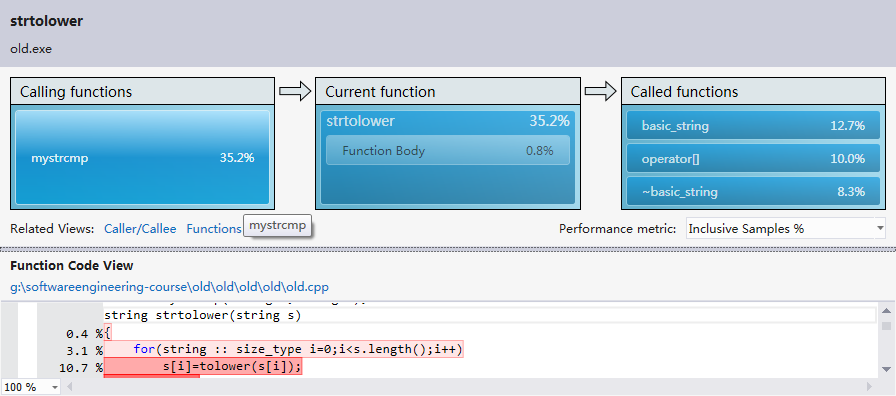
由报告可以分析出,目前程序的最大瓶颈在与tolower(s[i]);使用次数过多。
更进一步剖析算法,可以得出tolower的算法设计有很大的缺陷,造成每一次的单词比较,都要进行一次大小写转换。
解决方案:用一个vector<string>将频次表的每个单词的小写形式都存储起来,这样对每个单词只进行一次大小写转换,大大提高效率。
优化后:
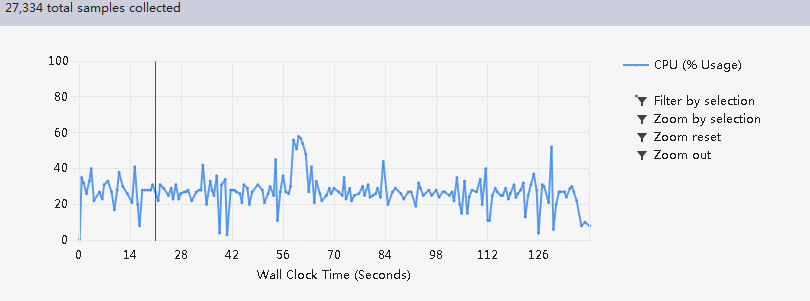
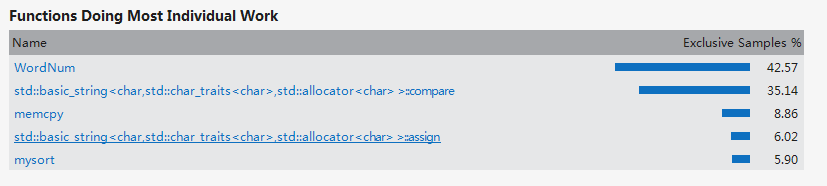
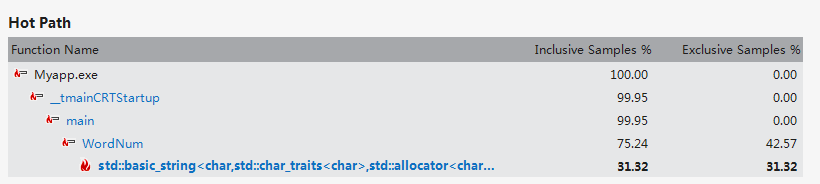
从优化后报告可以看出,tolower()函数已经完全从hot path中消失,说明开始算法在此的设计时非常欠考虑的,也说明优化是很成功的。
第二次优化过程
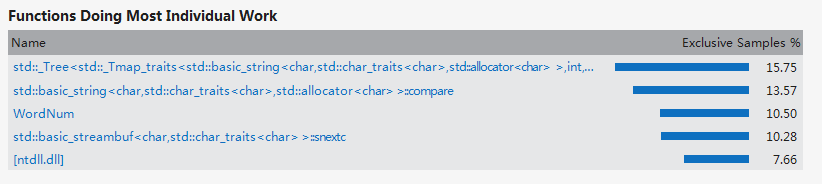
从第一次优化结果可以看出虽然tolower()函数完全从hot path中消失,但是WordNum函数取代它成为hot path,
更具体地:

是lowco[k]==eword此句用得过多。
优化策略:修改lowco的存储方式,使用map存储lowco,提高查找效率。
优化后:

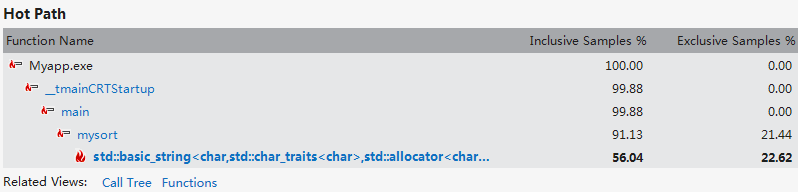
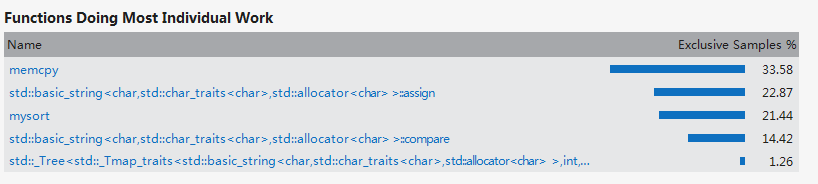
此时的hotpath中WordNum查询分词函数已经消失,说明优化是非常成功的。
第三次优化:
从第二次优化的结果可以看出,虽然WordNum已经从Hotpath中消失,但mysort取代了其;
更具体地:

是因为O(n^2)的排序算法效率过低。
解决方法:使用sort函数提高效率。
优化后:
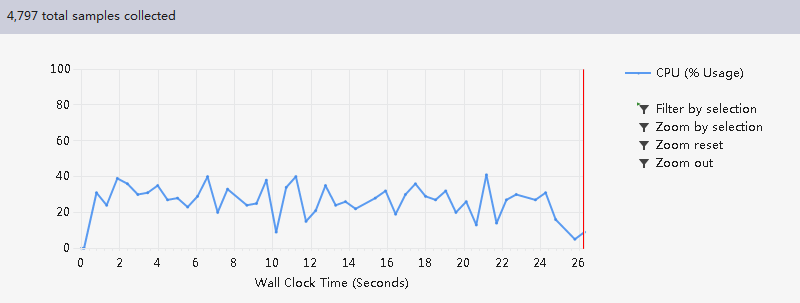
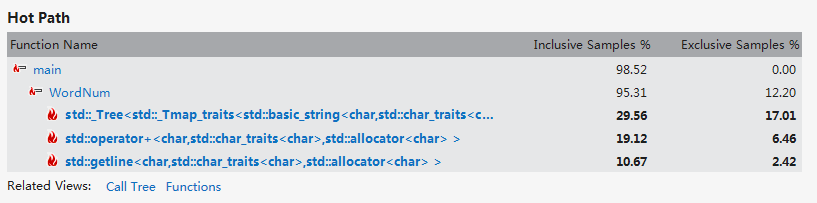
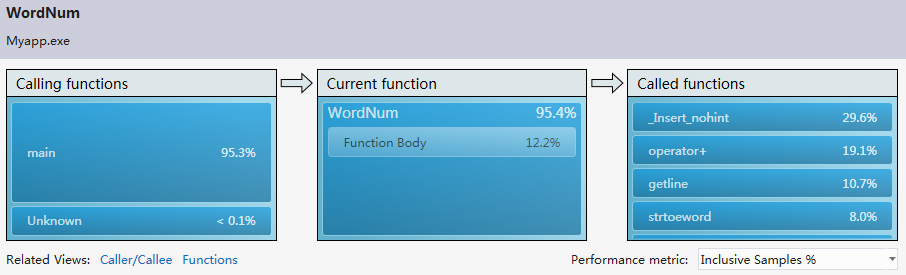
此时的mysort已不是hotpath,优化是成功的。
第四次优化:
从第三次优化结果可以看出,WordNum又一次回到了hotpath
具体地:

可以看出,分离单词的逐条拼接,过于频繁;
解决方案:将单词一次性拼接;
优化结果:
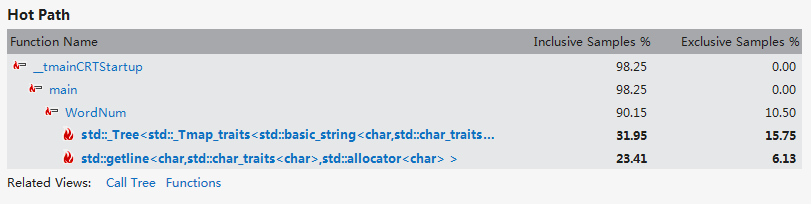

可以看出word的拼接高效了很多,优化成功。
优化总结:(第5部分的总结写了代码优化的具体细节哦~)
首先,这个代码分析来优化的方法真是好用呀~
从优化的整个过程来分析,刚开始程序的算法设计中有一个“缺陷”,如果不是测试数据指出,我没有料想到起初算法的主要效率问题在那里。
发现单词查询统计是瓶颈,之后用map存储“处理单词”(大小写忽略或尾数字忽略)和相应存储vector的下标,以提高查找效率。事后发现,这是一个很好的存储方法:只需要查找一次,就可以实现两个集合的修改,即只需要查找map,得知单词在vector中的下标,对vector进行下标访问,实现修改。
发现单词排序是瓶颈,然后用sort函数代替自己写的排序算法,自己写了一个O(n^2)的算法,和一个O(nlogn)的二路归并排序,但前者是时间效率过低,后者对操作数的赋值过多,造成效率也不高,发现sort的算法真的很高效,有时间学习一下~
在几乎优化了程序所有部分之后,发现瓶颈竟然是单词查询统计,修改了单词读取拼接的算法,但是对于查询单词,在我的能力范围内,觉得map已经很好了。
总体的优化结果还是很令人满意的,以前一个20M的测试文件要跑大概3分钟,现在5秒就可以跑出结果。
在多步优化后,单词分离查询又成为程序的瓶颈,说明此程序最应该优化的部分应该是单词分离查询部分。
但是,由于在此程序中已对此部分进行了优化(使用map进行查询),其效率是很高的。所以此程序的优化应该在个人能力范围内基本完成。
4) Share your 10 test cases, and how did you make sure your program can produce the correct result. (programs with incorrect result will get 0 points, regardless of speed)
测试案例
1.不合法的目录:包括目录不存在和目录格式错误;
2.不合法的命令格式:包括命令参数格式错误,数量错误,不含有此类命令等;
3.存在空文件夹:包括本身文件夹为空和空子文件夹;
4.存在空文件或空行;
5.文件在多层文件夹下;//文件递归测试;
6.存在文件格式.txt,.cs,.cpp,.h,.TXT,.CS,.CPP,.H;
7.存在多种字符格式:前四个字母,大小写,数字,分隔符,中文符号ele,e2e,elepha特nt,elephat,elePHat,elephat123,Elephant342e等等;
8.较大数据的读取和处理,例如读取一个100M的文件夹;
9.带有中文符号的路径读取;
10.排序是否正确:按频率排序,同频率不同单词的排序结果。
测试方法:
1.首先检查各种路径输入(有无),非法输入;
2.先用一个文件进行测试,此文件包含许多测试点,人工比对,随后复制成各种不同文件,分散在文件夹中,统计频率是否成正比;
3.文件夹只包含一个非常大的文件,随机抽取文字,用word检索后,核对结果;
4.与同学相互测试,核对结果。
5) Describe what you had learned in this exercise.
这次的感想很多,学到很多,所以隆重推出——
总结小目录*
整体过程通并快乐着,学到很多C++知识,感谢那些在程序编写过程中帮助我的同学~
自学=犯错误/不知道->看书+上网查资料+同学交流
编程区别:实际工程中,编程 =1/3写代码+1/3优化+1/3测试
课堂大作业,编程=写代码
迭代优化:通过代码分析这个神奇东东发现性能瓶颈,对代码进行不断地优化,但不能全靠软件工具进行优化,自己的不断学习和良好的思维才能构建好框架,才能更有意义地优化。
测试! 测试!测试:写测试+手工阅读代码;写完代码后不能就再不看它了,隔一段时间,看代码的过程是完整、系统地,所以更容易检查出逻辑错误。
实践和课本:实践中,还是要具体情况具体对待。例如,课本上讲的排序主要用比较次数来衡量效率,但是,如果赋值过程更加耗时,那么就要权衡考虑啦~
不足:
没有很好地规划时间,对于自己完成工程所用时间完全没有思路,就是有时间就写的状态。
代码没有进行蓝本学习,全靠自己的实践尝试,是不是有点效率低?应该多看一些编程类书籍,提高知识储备。
详文:
自学=犯错误/不知道->看书+上网查资料+同学交流
这一次写代码完全有一次C++从入门到精通的感觉,其实不能说是精通,可以说是使用吧。虽然书架上躺着一本C++ Primer,但是它只是躺着。这一次,我看到C++ Primer真是相见恨晚,觉得书里很多有用的东西。
在写代码之前进行了算法的初步构思,由于个人对C++的了解有限,就先用最直白的方式写吧。写的过程中,就是不断地看书、上网查资料和问同学。Debug的过程中,就是不断地学习软件的过程,和了解C++语言的过程。
迭代优化:代码分析很强大,但也不能依赖工具,忽略个人内功
其实,让我觉得最惊奇的地方在于,代码分析功能,太强大了~通过代码分析,可以找到代码的瓶颈,通过改善瓶颈优化代码。第一次代码分析就让我大吃一惊,我原先没觉得字符转换需要什么时间,但仔细分析,发现需要O(n^2)才能解决,其实字符转化O(n)就可以,通过改变比较策略,增加O(n)空间就解决了,也让我对代码分析更加熟悉。于是,我就一遍又一遍地运用这个工具进行代码优化,直到——我现阶段没有能力修改了。但也发现代码分析不是万能的,其实如果你的代码框架错误,那怎样也会有瓶颈的存在,所以软件开发工具只是辅助,核心在于程序员要不断学习,有好的思维。
代码优化过程中有一个小插曲,在将查询过程修改成用Map时,我想Map如此好用,不如把存放单词频次表的Vector也一并改成Map吧。可又一想,不好,使用Map每次相当于查找一次,不如将Map里存放Vector中单词的小写部分和相应的下标,这样,每个单词只进行一次查询,且Vector更易用下表访问和排序,现在想想也觉得这个思路很不错呢~
实践和课本:具体情况具体对待
有一次代码优化让我印象深刻,代码分析中说排序函数是瓶颈,所以我将自己写的一个O(n^2)的排序算法改成了O(nlogn)的二路归并排序算法,惊喜是——更慢了。看了分析报告发现,虽然二路归并算法的比较次数比较少,但是它过多地对数据进行移动,而pair的赋值很耗时,所以算法反而比以前的慢了。这和课本里所讲的排序的复杂度依赖于比较次数好像有那么一点不同,感觉“尽信书不如无书”,只有真实地实践和实验才能感觉到。
测试! 测试!测试:写测试+手工阅读代码;
最后,测试阶段,因为这一次如果结果错误就没有分数,所以要非常认真地对待测试。首先自己写一些小例子进行测试,随后找同学一起测试。话语觉得很简短,但是过程很是漫长,也让我第一次觉得工程与大作业的不同。以前写大作业,程序bug不是很在意,程序能运行就可以,更不用说效率了。其实仔细想想,实际工程中的程序有bug是很严重的事,对于低效率也是一样。
检查warning的过程中,其实有很多思路上的bug软件工具都无法检测到,所以我自己通过完整地看和理解代码两遍,发现了几个小的逻辑错误,觉得以后写代码不能调试、测试没问题就ok,还是要手工地进行逻辑检查。因为写代码过程中的逻辑思维是具体的,而间隔一段时间(这样会很好),看代码的过程是完整、系统地,所以更容易检查出错误。