Introduction
1. develop a common framework for all problems that are the task of predicting pixels from pixels.
2. CNNs learn to minimize a loss function -an objective that scores the quality of results-- and although the learning process is automatic, a lot of manual effort still goes into designing effective losses.
3.the CNN to minimize Euclidean distance(欧式距离L2) between predicted and ground truth pixels, it will tend to produce blurry results.
why? because the L2 distance is minimized by averaging all plausible outputs, which cause blurring.
4.GANs learn a loss that tries to classify if the output image is real of fake , blurry images will not be tolerated since they obviously fake!
5. they apply cGANs suitable for image-to-image translation tasks, where we condition on input image and generate a corresponding output image.
Releted work
1.image-to-image translation problems are formulated as per-pixel(逐个像素的)classfication or regression.but these formulations treat the output space as “unstructured” ,each output pixel is considered conditionally independent from all others given the input image.(独立性!)
2. conditional GANs learn a structured loss.
3. cGANs is different in that the loss is learned(损失可以学习), in theory, penalize any possible structure that differs between output and target.(条件GAN的不同之处在于,损失是可以习得的,理论上,它可以惩罚产出和目标之间可能存在差异的任何结构。)
4. the choices for generator and discriminator achitecture:
for G: using 'U-Net '
for D: using PatchGAN classifier penalizes structure at the scale of image patches.
The purpose of PatchGAN aim to capure local style statistics.(用于捕获本地样式统计信息)
Method
1. The whole of framwork is that conditional GANs learn a mapping from observed image x and random noise vector z, to y. $G:{x,z} ightarrow y(ground-truth)$ .
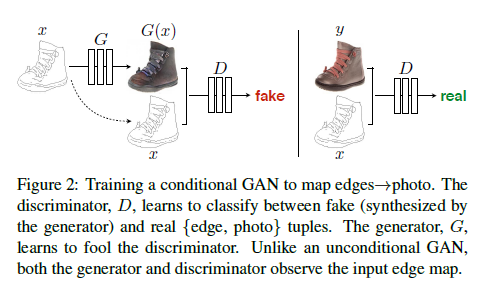
2. Unlike an unconditional GAN, both the generator and discriminator observe the input edge map.
3. objective function:
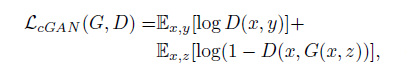
G try to minimize this objective against an adversarial D that try to maximize it.
4. they test the importence of conditioning the disctiminator, the discriminator dose not oberve x(edge map):
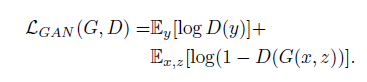
5. it's beneficial to mix GAN objective with a more traditional loss, such as L2-distance.
6. G is tasked to not only fool the discriminator but also to be near the ground truth output in an L2 sense.
7. L1 distance is applied into the additional loss rather than L2 as L1 encourages less blurring(remeber it!).
8.
final objective
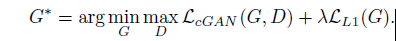
9. without $z$ (random noise vector), the net still learn a mapping from $x$ to $y$, but would produce deterministic output, therefore fail to match any distribution other than a delta function.(因此无法匹配除函数之外的任何分布)
10. towords $z$, Gaussian noise often is used in the past, but authors find this strategy ineffective, the G simply learned to ignore the noise. Finally, in the form of dropout is provided.but we observe only minor stochasticity in the output of our nets.
Network Architecture
1. The whole of generator and discriminator architectures from DCGANs.
For G: U-Net;DCGAN; encoder- decoder; bottleneck; shuttle the information;
The job:
1.mapping a high resolution grid to a high resolution output grid.
2. although the input and output differ in surface appearance, but both are rendering of same underlying structure.
The character:
structure in the input is roughly aligned with structure in the output.
The previous measures:
1.encoder-decoder network is applied.
2.until a bottleneck layer, downsample is changed to upsample.
Q:
1. A great deal of low-level information shared between the input and output, shuttling this information directly across the net is desirable.例如,在图像着色的情况下,输入和输出共享突出边缘的位置。
END:
To give the generator a means to circumvent(绕过) the bottleneck for information like this, adding skip connections is adopted, this architecture called 'U-Net'

The results of different loss function:

L1 loss or L2 loss produce the blurry results on image generation problems.
For D:
1. both L1 and L2 produce blurry results on image generation problems.
2. L1 and L2 fail to encourage high frequency crispness(锐度),nonetheless(仍然) accurately capture the low frequencies.
3.in order to model high-frequencies , we pay attention to the structure in local image patches.
4.This discriminator tries to classify if each patch in an N*N image is real or fake. We run this discriminator convolutationally across the image, averaging all responses to provide the ultimate output of D.(这个鉴别器试图分类一个N*N图像中的每个补丁是真还是假。我们用这个判别器对图像进行卷积,对所有响应进行平均,得到D的最终输出).
5. N can be much smaller than full size of image and still produce high quality results. smaller pathGAN have mang advantages.
6. D effectively models the image as Markov random field, PatchGAN cn be understand as a form of texture/ style loss!
For Optimization.
1. slows down D relative to G.(此外,在优化D时,我们将目标除以2,这减慢了D相对于G的学习速度)
2.当批大小设置为1时,这种批处理规范化方法被称为实例规范化,并被证明在图像生成任务中是有效的,
batchsize is setted into 1 to 10
3. Instance normalization(IN) and batch normalization(BN), the strategy of IN is adopted in this paper because IN has been demonstrated to be effective at image generation task.
BN 是一个batch 里面的所有图片的均值和标准差,IN 是对一张图片求均值和标准差,shuffle的存在让batch 不稳定, 本来就相当于引入了noise, in the task of image generation, IN outperforms compared with BN, 因为这类生成式任务自己的风格较为独立不应该与batch中的其他样本产生较大的联系,相反在图像和视频的task of classification, BN outperforms IN .
For Experiments
1. removing conditioning for D have very poor performance because the loss does not penalize mismatch between the input and output; it only cares
that the output look realistic.
2. L1 + CGANs create realistic rendersings(渲染), L1 penalize the distance between ground truth outputs, which correctly match the input and synthesized outputs.
3.An advantage of the PatchGAN is that a fixed-size patch discriminator can be applied to arbitrarily large images.
4.