网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。爬虫实在是计算机从业者的福音,它大大的缩减了我们的工作量。今天,我们就来尝试一下网页的爬取。
首先,我们需要安装两个基本的库,requests和beautifulsoup4。
requests:requests是Python中一个第三方库,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
beautifulsoup4:Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
我们安装这两个库的最简单的方法当然是通过pip指令。首先打开控制台,输入cmd,然后输入指令:
pip install requests/beautifulsoup4
即可自动安装。(关于pip的基本用法请见上一篇博客:https://www.cnblogs.com/Chen-K/p/11785161.html)
接下来,我们尝试着爬取一个网页的代码:
import requests
r=requests.get("https://httpbin.org")
print(type(r))
print(r.status_code)
print(r.encoding)
print(r.text)
print(r.cookies)
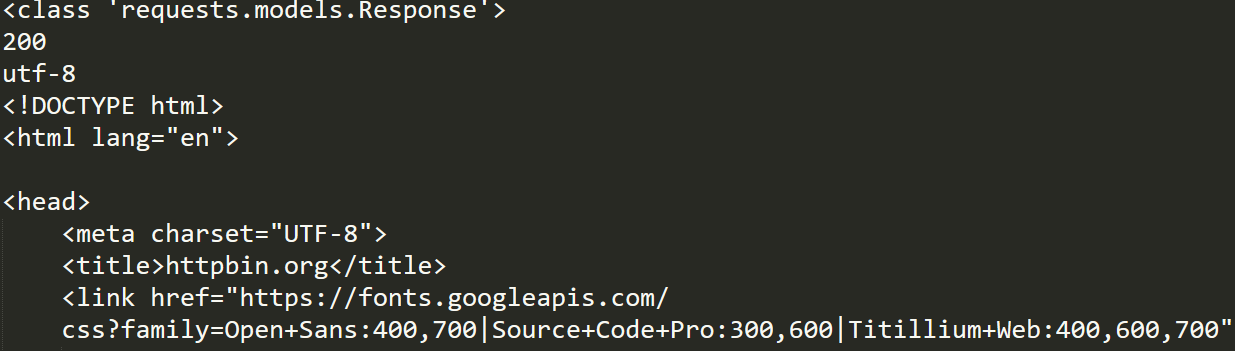
那么,当我们只想爬取网页上的某一个标签时,又该如何操作呢?
import requests
from bs4 import BeautifulSoup
r=requests.get("https://www.baidu.com")
r.encoding='utf-8'
result=r.text
# print(result)
soup=BeautifulSoup(result,'html.parser')
name=soup.find_all('head')
for i in name:
print(i.text)
