ASCII简介
ASCII 码使用指定的 7 位或 8 位二进制数组合来表示 128 或 256 种可能的字符。标准 ASCII 码也叫基础ASCII码,使用 7 位二进制数来表示所有的大写和小写字母,数字 0 到 9、标点符号, 以及在美式英语中使用的特殊控制字符。其中:
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(振铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为 8、9、10 和 13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
32~126(共95个)是字符(32sp是空格),其中48~57为0到9十个阿拉伯数字;
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
同时还要注意,在标准ASCII中,其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。
后128个称为扩展ASCII码,目前许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展 ASCII 码允许将每个字符的第 8 位用于确定附加的 128 个特殊符号字符、外来语字母和图形符号。
ASCII产生
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)、以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了所谓的ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
美国标准信息交换代码是由美国国家标准学会(American National Standard Institute , ANSI )制定的,标准的单字节字符编码方案,用于基于文本的数据。起始于50年代后期,在1967年定案。它最初是美国国家标准,供不同计算机在相互通信时用作共同遵守的西文字符编码标准,它已被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准。适用于所有拉丁文字字母。
ASCII国际问题
ASCII是美国标准,所以它不能良好满足其它讲英语国家的需要。例如英国的英镑符号(£)在哪里?拉丁语字母表重音符号。使用斯拉夫字母表的希腊语、希伯来语、阿拉伯语和俄语。汉字系统的中国象形汉字,日本和朝鲜。
1967年,国际标准化组织(ISO:International Standards Organization)推荐一个ASCII的变种,代码0x40、0x5B、0x5C、0x5D、0x7B、0x7C和0x7D“为国家使用保留”,而代码0x5E、0x60和0x7E标为“当国内要求的特殊字符需要8、9或10个空间位置时,可用于其它图形符号”。这显然不是一个最佳的国际解决方案。因为这并不能保证一致性。但这却显示了人们如何想尽办法为不同的语言来编码的。
ASCII码的算法
A在ASCII中定义为01000001,也就是十进制65,有了这个标准后,当我们输入A时,计算机就可以通过ASCII码知道输入的字符的二进制编码是01000001。而没有这样的标准,我们就必须自己想办法告诉计算机我们输入了一个A;没有这样的标准,我们在别的机器上就需要重新编码以告诉计算机我们要输入A。ASCII码指的不是十进制,是二进制。只是用十进制表示习惯一点罢了,比如在ascii码中,A的二进制编码为01000001,如果用十进制表示是65,用十六进制表示就是41H。
在ASCII码表中,只包括了一些字符、数字、标点符号的信息表示,这主要是因为计算机是美国发明的,在英文下面,我们使用ASCII表示就足够了!但是在汉字输入下面,用ASCII码就不能表示了,而汉字只是中国的通用表示,所以如果我们要在计算机中输入汉字,就必须有一个像ascii码的标准来表示每一个汉字,这就是中国的汉字国标码,它定义了汉字在计算机中的一个表示标准。通过这个标准,但我们输入汉字的时候,我们的输入码就转换为区位码,通过唯一的区位码得到这个汉字的字形码并显示出来。当然汉字的区位码在计算机中也是用二进制表示的!
汉字编码
0-127 是 7位ASCII 码的范围,是国际标准。
至于汉字,不同的字符集用的ascii 码的范围也不一样,常用的汉字字符集有GB2312-80,GBK,Big5,unicode 等。下面我重点说一说最常用的GB_2312 的字符集。
GB_2312 字符集是目前最常用的汉字编码标准,windows 95/98/2000 中使用的 GBK字符集 就包含了GB2312,或者说和GB2312 兼容,GB_2312 字符集包含了 6763个的 简体汉字,和682 个标准中文符号。在这个标准中,每个汉字用2个字节来表示,每个字节的ascii码为 161-254 (16 进制A1 - FE),第一个字节 对应于 区码的1-94 区,第二个字节 对应于位码的1-94 位。
161-254 其实很好记忆,大家知道英文字符中,可打印的字符范围为33-126。将 这对 数加上128(或者说最高位置1),就得到汉字使用的字符的范围。
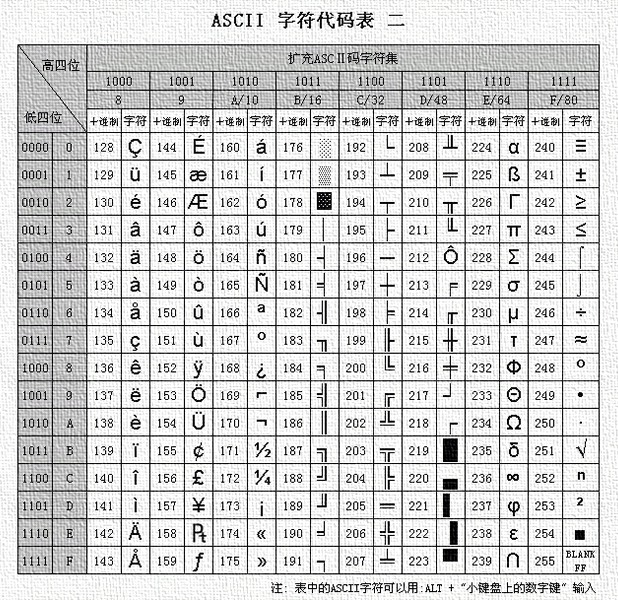
ASCII码表大致可以分三部分组成:
一:ASCII非打印控制字符
二:ASCII打印字符
三:扩展ASCII打印字符
一:ASCII非打印控制字符
ASCII表上的数字0–31分配给了控制字符,用于控制像打印机等一些外围设备。例如,12代表换页/新页功能。此命令指示打印机跳到下一页的开头。(参详ASCII码表中0-31)
二:ASCII打印字符
数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。数字127代表 DELETE 命令。(参详ASCII码表中32-127)


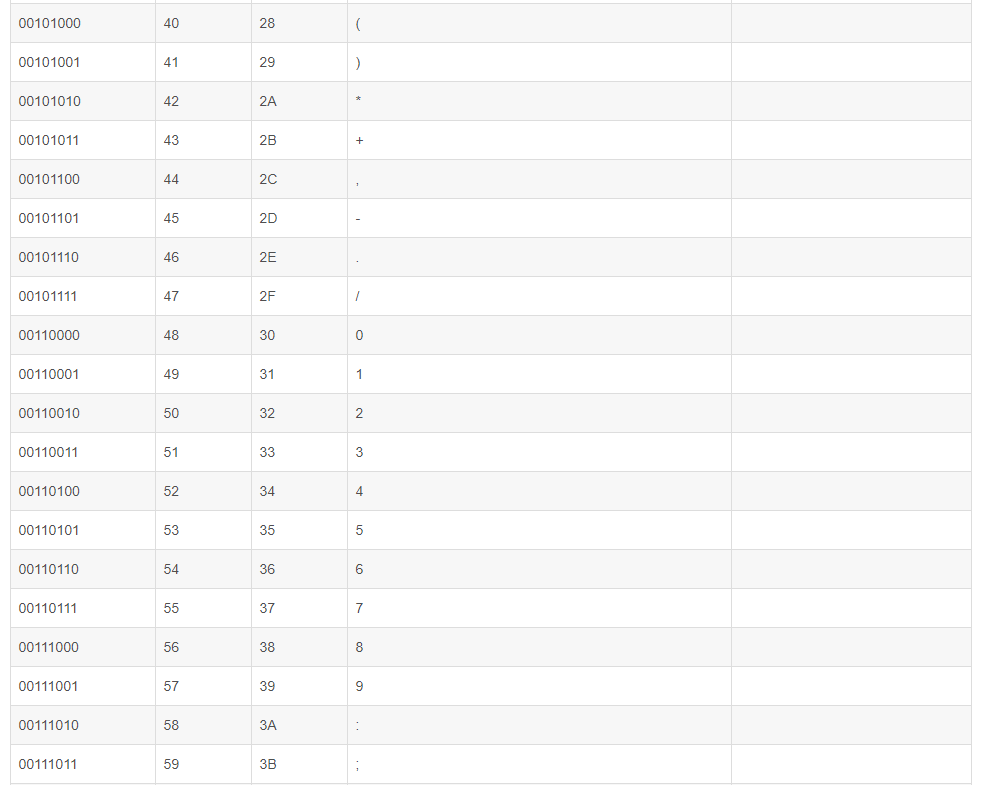
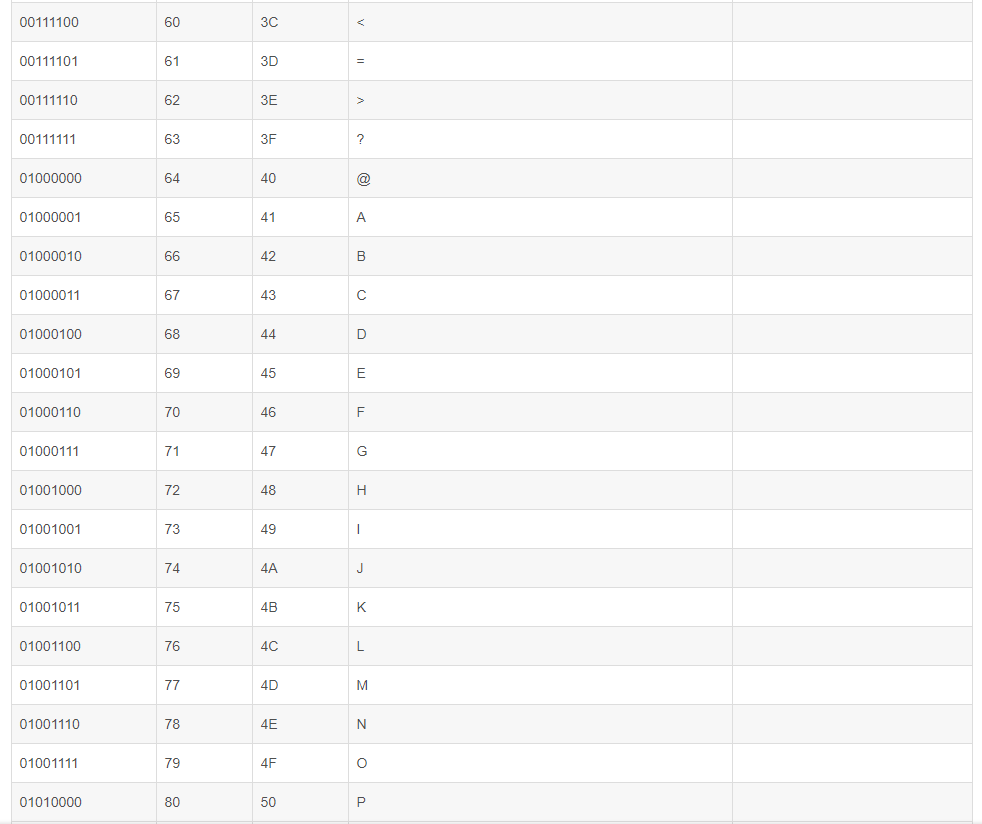
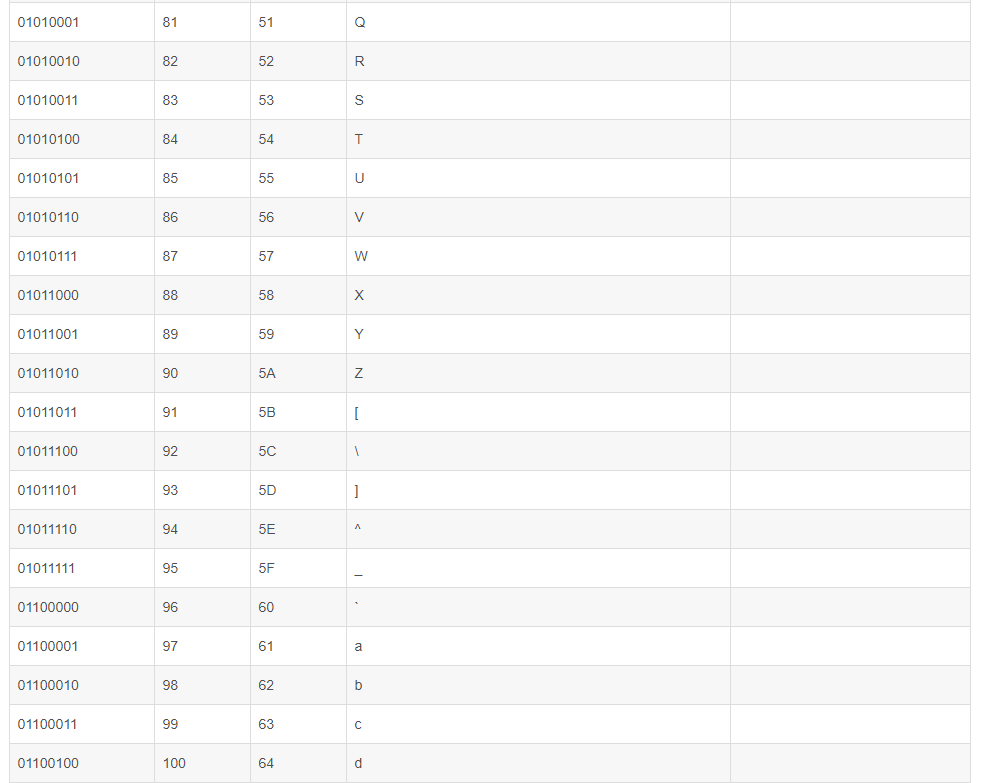
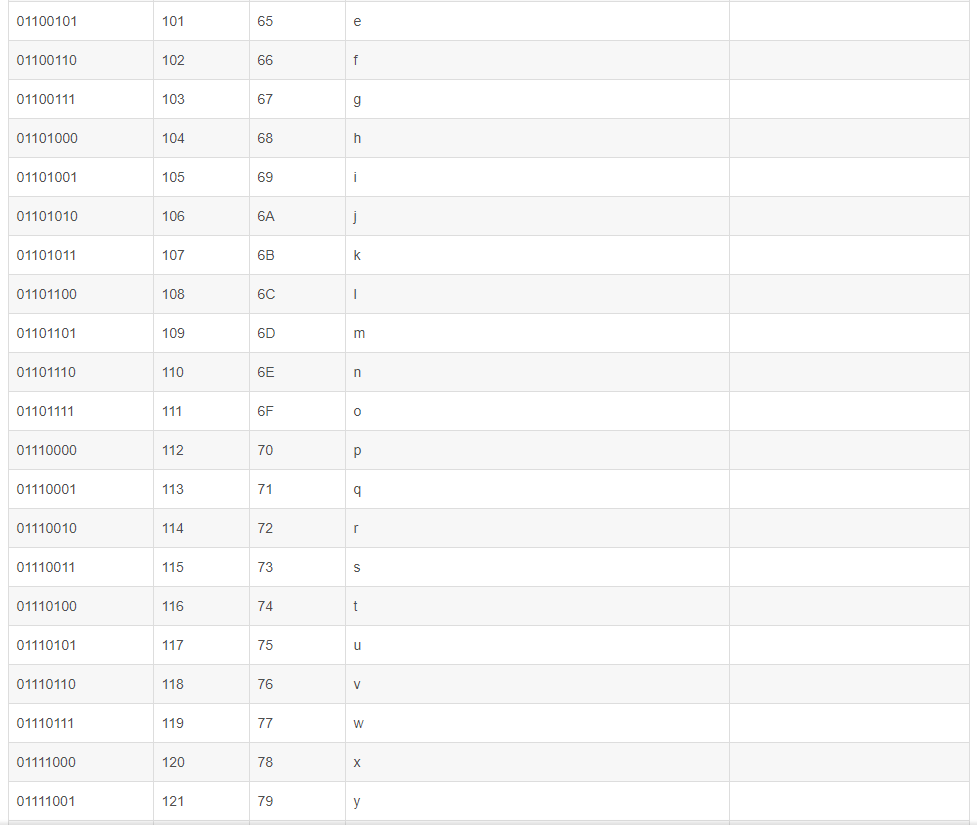

三:扩展ASCII打印字符
扩展的ASCII字符满足了对更多字符的需求。扩展的ASCII包含ASCII中已有的128个字符(数字0–32显示在下图中),又增加了128个字符,总共是256个。即使有了这些更多的字符,许多语言还是包含无法压缩到256个字符中的符号。因此,出现了一些ASCII的变体来囊括地区性字符和符号。例如,许多软件程序把ASCII表(又称作ISO8859-1)用于北美、西欧、澳大利亚和非洲的语言。