sudo apt install openssh-server报错:
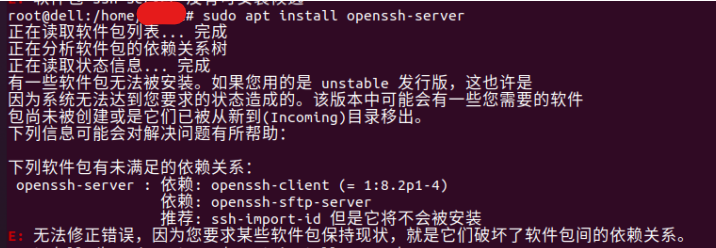
解决办法: sudo apt install openssh-client=1:8.2p1-4 降级安装后再安装openssh-server
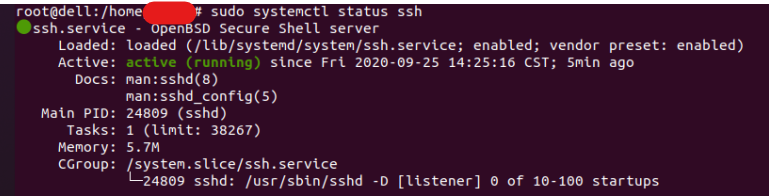
sudo systemctl status ssh 显示运行状态
Ubuntu随附了一个名为UFW的防火墙配置工具。如果在系统上启用了防火墙,请确保打开SSH端口:
sudo ufw allow ssh现在,您可以从任何远程计算机通过SSH连接到Ubuntu系统。Linux和macOS系统默认安装了SSH客户端。要从Windows计算机连接,请使用SSH客户端(例如PuTTY)。
连接到SSH服务器
要通过LAN连接到Ubuntu计算机,请调用ssh命令,然后输入用户名和IP地址,格式如下:
ssh username@ip_address确保
username使用实际用户名和ip_address安装SSH的Ubuntu计算机的IP地址进行更改。
如果您不知道IP地址,则可以使用以下ip命令轻松找到它:
ip a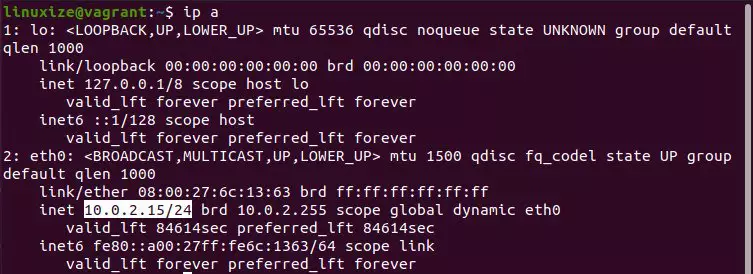
从输出中可以看到,系统IP地址为10.0.2.15。
找到IP地址后,通过运行以下ssh命令登录到远程计算机:
ssh linuxize@10.0.2.15首次连接时,您会看到如下消息:
The authenticity of host '10.0.2.15 (10.0.2.15)' can't be established.
ECDSA key fingerprint is SHA256:Vybt22mVXuNuB5unE++yowF7lgA/9/2bLSiO3qmYWBY.
Are you sure you want to continue connecting (yes/no)?键入yes你会被提示输入您的密码。
Warning: Permanently added '10.0.2.15' (ECDSA) to the list of known hosts.
linuxize@10.0.2.15's password:输入密码后,将收到默认的Ubuntu消息:
Welcome to Ubuntu 20.04 LTS (GNU/Linux 5.4.0-26-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
...现在,您已登录到Ubuntu计算机。
在NAT后连接到SSH
要通过Internet连接到您的家用Ubuntu计算机,您需要知道您的公共IP地址,并将路由器配置为接受端口22上的数据,并将其发送到运行SSH的Ubuntu系统。
要确定你想SSH到机器的公网IP地址,只需访问以下网址:https://www.baidu.com/s?wd=ip。
在设置端口转发时,每个路由器都有不同的方式来设置端口转发。您应该查阅路由器文档,以了解如何设置端口转发。简而言之,您需要输入进行请求的端口号(默认SSH端口为22)和您先前ip a在运行SSH的计算机上找到的私有IP地址(使用命令)。
找到IP地址并配置路由器后,您可以通过输入以下内容登录:
ssh username@public_ip_address如果要将计算机暴露在Internet上,则最好实施一些安全措施。最基本的方法是将路由器配置为在非标准端口上接受SSH流量,并将其转发到运行SSH服务的计算机上的端口22。
您还可以设置基于SSH密钥的身份验证并连接到Ubuntu计算机,而无需输入密码。
在Ubuntu上禁用SSH
要在您的Ubuntu系统上禁用SSH服务器,只需运行以下命令即可停止SSH服务:
sudo systemctl disable --now ssh稍后,要重新启用它,请输入:
sudo systemctl enable --now ssh结论
我们已经向您展示了如何在Ubuntu 20.04上安装和启用SSH。现在,您可以登录计算机并通过命令提示符执行日常sysadmin任务。
如果要管理多个系统,则可以通过在SSH配置文件中定义所有连接来简化工作流程。更改默认的SSH端口,可以降低自动攻击的风险,从而为您的系统增加一层额外的安全保护。
有关如何配置SSH服务器的更多信息,请阅读Ubuntu的SSH / OpenSSH /配置指南和官方SSH手册页。
查看Ubuntu系统的版本号
a@a-desktop:~$ cat /etc/issue
Ubuntu 20.04.1 LTS l
a@a-desktop:~$ sudo lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.1 LTS
Release: 20.04
Codename: focal
查看Ubuntu系统位数
a@a-desktop:~$ uname -ar
Linux dell 5.4.0-42-generic #46-Ubuntu SMP Fri Jul 10 00:24:02 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
安装cuda时 提示toolkit installation failed using unsupported compiler解决方法
在安装cuda的时候,有时候会提示toolkit installation failed using unsupported compiler。这是因为GCC版本不合适所导致的。
解决的方法很简单,直接在安装命令之后加-override再安装,一般来说就没什么问题了。如:sudo ./cuda_6.0.37_linux_64.run -override
NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver.
更新一下!!!
最安全的做法是重装显卡驱动,有丰富的linux调试经验到的人可以参考下我的文章,小白千万不要按照我的这篇文章来做!!!
按照我这篇文章来做的时候有以下注意:!!!
一定要看一下自己的之前能用的内核是什么,不要一切都按照我的配置来,每个人的机器都有自己之前的配置,不然很容易导致没有内核可用而导致无法开机或者桌面驱动不可用导致的重复输入密码而进入桌面!!!
这是一个巨坑
重要的话说三遍
- 不要更新你的Ubuntu内核
- 不要更新你的Ubuntu内核
- 不要更新你的Ubuntu内核
为什么呢?
因为当你更新你的内核之后,你进入的系统默认使用最新的,而这个最新的却不会把你之前安装的nvidia驱动也迁移过来,所以导致:
驱动崩坏——>重装驱动——>更新内核——>驱动崩坏——>重装驱动
的死循环。
那么现在除了重装驱动还有救么?有!
我们要去做的,就是修改系统配置使启动系统时启用我们之前的内核
在终端输入:
grep menuentry /boot/grub/grub.cfg
你就可以看见你的启动项里面的所有内核。比如我的:
如果你没有更改过的话,那么你默认启动的是:
这会默认使用你最新的内核。
以我为例,我的拥有有效驱动的内核为:
也就是高级选项下第三个内核,使用我要去在grub里面设置默认启用这个内核(当然,你在系统启动时手动选择也可以,具体grub是啥限于篇幅就不介绍了)
现在我们可以修改我们的grub配置项了:
sudo nano /etc/default/grub
以我为例,修改grub配置如下,黄线标注出来的选项默认是0,我们需要更改它到高级选项下的第三个内核,就改为"1> 2",注意">"和"2"之间有一个空格: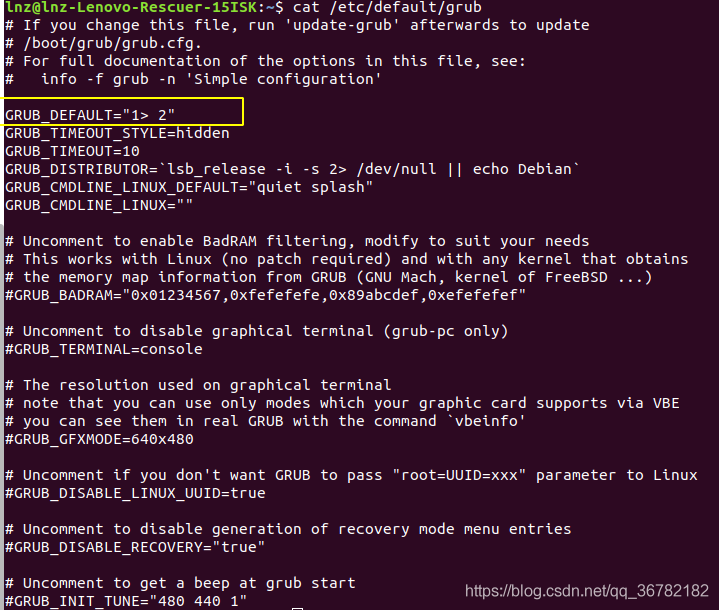
之后我们使用:
sudo update-grub
更新配置就完成了我们的默认内核设置。重启电脑,使用更新后的默认选项便可以挽救我们的电脑啦~~~
GPU 调用问题:failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
字面意思是GPU不可用。
但是我nvdia-smi了一下,发现服务器几个gpu都是空的啊。不可能啊。而且我的运行有加前缀:
CUDA_VISIBLE_DEVICES=2 python test.py
思来想去,查来查去,还是CUDA_VISIBLE_DEVICES的问题。原来代码隐藏的某处,把这个数值写死了,写成了
CUDA_VISIBLE_DEVICES=-1意为使用cpu。。。
命令行传进去的值被里面覆盖了。好吧。改写后就正常了。
https://help.ubuntu.com/18.04/installation-guide/i386/ch03s07.html
安装 Ubuntu 预安装硬件和操作系统设置
调用 BIOS 设置菜单
BIOS 提供启动计算机和允许操作系统访问硬件所需的基本功能。您的系统提供 BIOS 设置菜单,用于配置 BIOS。要进入 BIOS 设置菜单,您必须在打开计算机后按键或按键组合。通常是del键或 F2 键,但某些制造商使用其他key。通常,启动计算机时会有一条消息,说明要按哪个键进入设置屏幕。
启动设备选择
在 BIOS 设置菜单中,您可以选择应按哪个顺序检查可引导操作系统的设备。可能的选择通常包括内部硬盘hdd、CD/DVD-ROM 驱动器和 USB 大容量存储设备,如 USB 记忆棒或外部 USB 硬盘。在现代系统上,也经常有可能通过 PXE 启用网络引导。
根据您选择的安装介质(CD/DVD ROM、USB bar、网络引导),如果尚未启用相应的引导设备,则应启用这些设备。
大多数 BIOS 版本允许您在系统启动时调用启动菜单,在该菜单中选择计算机应为当前会话启动的设备。如果此选项可用,BIOS 通常会在系统启动时显示一条短消息,如"按 F12启动菜单"。用于选择此菜单的实际键因系统而异;常用的键是F12,F11和F8。 在此菜单中选择设备不会更改 BIOS 的默认启动顺序,即您可以将内部硬盘配置为普通主引导设备时,可以从 U 盘启动一次。
如果您的 BIOS 没有为您提供启动菜单来临时选择当前启动设备,则必须更改 BIOS 设置,以使应从中启动的设备成为主引导设备。debian-installer
不幸的是,有些计算机包含错误 BIOS 版本。即使 BIOS 设置菜单中有适当的选项,并且将斗杆选为主引导设备,从 U 盘启动也可能无法正常工作。在某些系统上,使用 USB 作为引导介质是不可能的;其他人可以通过改变设备类型在BIOS设置从默认的"USB-hdd/USB/USB ZIP/USB CDROM"从usb外设启动。特别是,如果您在 U 盘上使用混合 CD/DVD 映像(参见 4.3.1 节"使用混合 CD 或 DVD 映像准备 USB 记忆棒"),将设备类型更改为"USB CDROM"有助于使用某些 BIOS,这些 BIOS不会从 USB 硬盘模式下从 USB 记忆棒启动。debian-installer
如果您无法操作 BIOS 直接从 U 盘启动,您仍然可以选择使用复制到该棒的 ISO。使用第 4.4 节"为硬盘启动准备文件"启动,在扫描安装程序 ISO 映像的硬盘后,选择 USB 设备并选择安装映像。debian-installer
带 UEFI 固件的系统
UEFI (" 统一可扩展固件接口 ") 是一种新型的系统固件,用于许多现代系统,除其他用途外,还打算取代经典的PC BIOS。
目前,大多数使用 UEFI 的 PC 系统在固件中还具有所谓的"兼容性支持模块"(CSM),它为操作系统提供与经典 PC BIOS 完全相同的接口,因此可以不更改使用为经典 PC BIOS 编写的软件。 尽管如此,UEFI 打算有一天完全更换旧的 PC BIOS,而不完全向后兼容,并且已经有很多系统有 UEFI,但没有 CSM。
在使用 UEFI 的系统上,在安装操作系统时需要考虑一些事项。固件加载操作系统的方式在经典 BIOS(或 CSM 模式下的 UEFI)和本机 UEFI 之间根本不同。一个主要区别是硬磁盘分区在硬盘上的记录方式。当 CSM 模式下的经典 BIOS 和 UEFI 使用 DOS 分区表时,本机 UEFI 使用不同的分区方案,称为"GUID 分区表" (GPT)。在单个磁盘上,对于所有实际目的,只能使用两个磁盘中的一个,如果一个磁盘上具有不同操作系统的多引导设置,则所有磁盘都必须使用相同类型的分区表。仅在本机 UEFI 模式下才能从具有 GPT 的磁盘启动,但随着硬盘大小的增长,使用 GPT 变得越来越常见,因为经典 DOS 分区表无法解决大于 2 TB 的磁盘,而 GPT 允许更大的磁盘。BIOS(或CSM模式下的 UEFI)和本机 UEFI 之间的另一个主要区别是存储引导代码的位置以及必须采用的格式。这意味着每个系统都需要不同的引导加载程序。
在使用 CSM 在 UEFI 系统上启动时,后者变得非常重要,因为检查它是在 BIOS - 还是本机 UEFI 系统上启动的,并安装相应的引导加载程序。通常,这只会起作用,但在多引导环境中可能会出现问题。在某些具有 CSM 的 UEFI 系统上,可移动设备的默认引导模式可能不同于从硬盘启动时实际使用的模式,因此,当从 USB 棒以不同于从硬盘启动另一个已安装的操作系统时使用的不同模式启动安装程序时,可能会安装错误的引导加载程序,并且完成安装后系统可能无法启动。从固件引导菜单中选择引导设备时,某些系统为每个设备提供两个单独的选择,以便用户可以选择引导是发生在 CSM 还是本机 UEFI 模式下。debian-installerdebian-installer
禁用 Windows 8 [快速启动]功能
Windows 8 提供了一项名为"快速启动"的功能,可缩短系统启动时间。从技术上讲,当启用此功能时,Windows 8 不会执行真正的关闭,在被命令关闭时不会执行真正的冷启动,而是执行类似于部分挂起到磁盘的检查,以减少"启动"时间。只要 Windows 8 是计算机上唯一的操作系统,这是没有问题的,但是当您进行双引导设置时,可能会导致问题和数据丢失,其中另一个操作系统访问与 Windows 8 相同的文件系统。在这种情况下,文件系统的真实状态可能不同于 Windows 8 认为在"启动"之后的状态,这可能会导致文件系统在进一步写入文件系统访问时损坏。因此,在双启动设置中,为了避免文件系统损坏,必须禁用Windows 中的"快速启动"功能。
可能还需要禁用"快速启动",甚至允许访问 UEFI 设置以选择启动其他操作系统或 。在某些 UEFI 系统上,固件通过不初始化键盘控制器或 USB 硬件来减少"启动"时间;在这些情况下,必须引导到 Windows 并禁用此功能以允许更改启动顺序。debian-installer
需要注意的硬件问题
USB BIOS 支持和键盘。如果您没有 PS/2 风格的键盘,但只有 USB 型号,在一些非常旧的 PC 上,您可能需要在 BIOS 设置中启用旧键盘仿真,以便能够在引导加载器菜单中使用键盘,但这不是现代系统的问题。如果您的键盘在引导加载器菜单中不起作用,请参阅主板手册,并在 BIOS 中查找"旧键盘仿真"或"USB 键盘支持"选项。
4.6.获取系统安装介质, 自动安装系统(Kickstart 文件示例):https://help.ubuntu.com/18.04/installation-guide/i386/ch04s06.html
w3m . # 字符画显示目录结构
包管理系统
sudo apt-get install synaptic
激活 Canonical 合作伙伴软件仓库
Canonical 合作伙伴软件仓库,提供了一些专有的应用程序,这些应用程序都是免费的,但也都是闭源的。它们包括 Adobe Flash 插件之类的软件。该存储库中的软件将出现在 Ubuntu 软件中心搜索结果中,但必须要启用这些软件源以后才能安装。
要启用该库,请遵照上述步骤打开在软件和更新 中的其他软件标签页。如果您在列表中看到Canonical 合作伙伴仓库,请确保将其选中,然后关闭 软件和更新 窗口。如果没有看到该库,单击添加,然后输入:
deb http://archive.canonical.com/ubuntu focal partner
点添加源,然后关闭软件和更新窗口,等待 Ubuntu 软件中心下载软件库信息。
键盘导航: https://help.ubuntu.com/lts/ubuntu-help/keyboard-nav.html.zh-CN
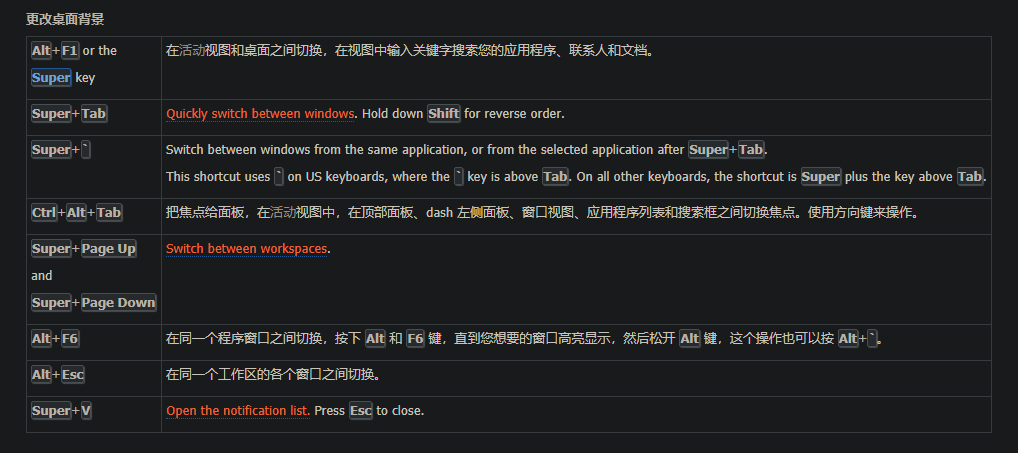
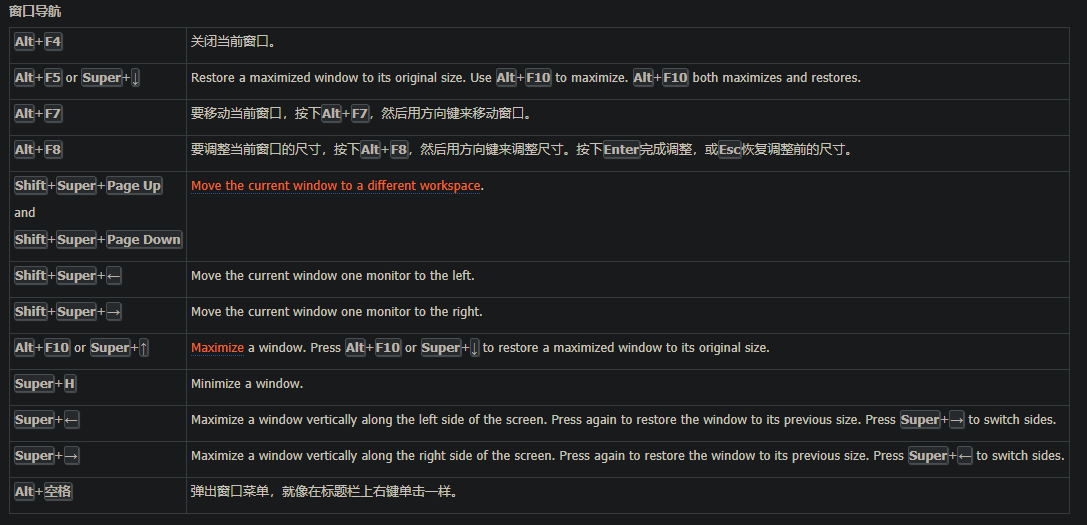
https://help.ubuntu.com/lts/ubuntu-help/keyboard-shortcuts-set.html.zh-CN
预定义的快捷键
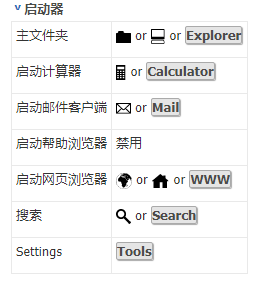
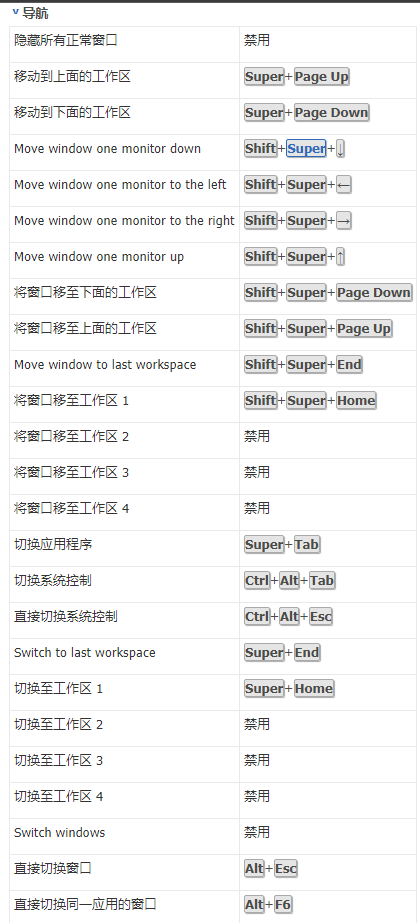

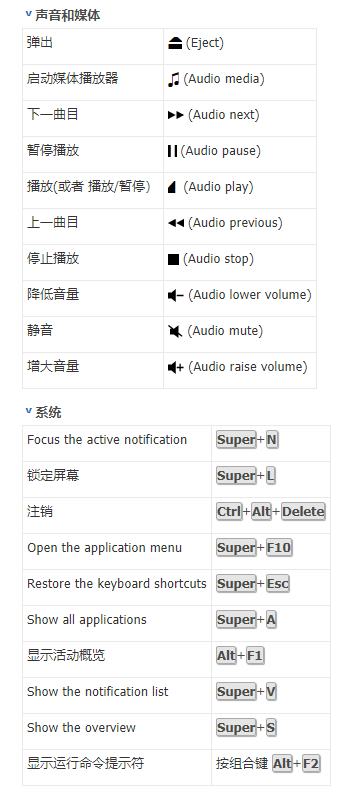
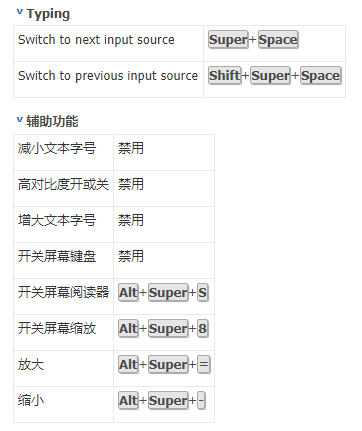
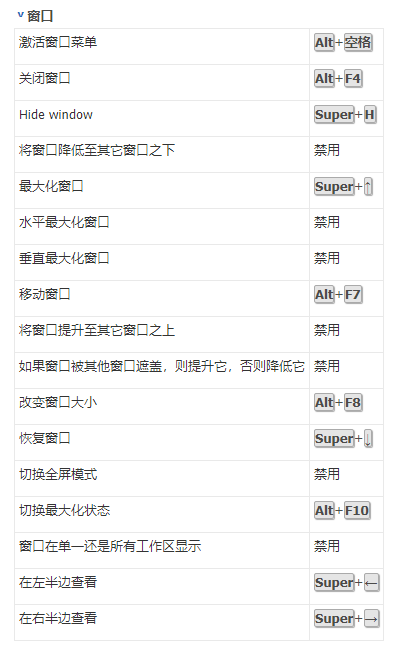
自定义快捷键
若要在键盘设置中创建自己的应用程序键盘快捷方式:
-
单击+按钮。将显示"添加自定义快捷方式"窗口。
-
键入名称以标识快捷方式,键入命令以运行应用程序。例如,如果您想要打开节奏框的快捷方式,可以命名它音乐并使用节奏框命令。
-
单击刚刚添加的行。打开"设置自定义快捷方式"窗口时,按住所需的快捷方式键组合。
-
单击"添加"。
键入的命令名称应是有效的系统命令。您可以通过打开终端并在中键入来检查该命令能否正常工作。打开应用程序的命令不能与应用程序本身具有相同的名称。
如果要更改与自定义键盘快捷方式关联的命令,请单击快捷方式的名称。将显示"设置自定义快捷方式"窗口,您可以编辑该命令。
ubuntu software安装软件提示snap无法安装has install-snap change in progress
我用ubuntu software装啥软件,都是各种snap报错,就没有成功过。每次都是提示snap错误,怀疑是snap自身的问题,尝试在命令模式下载安装。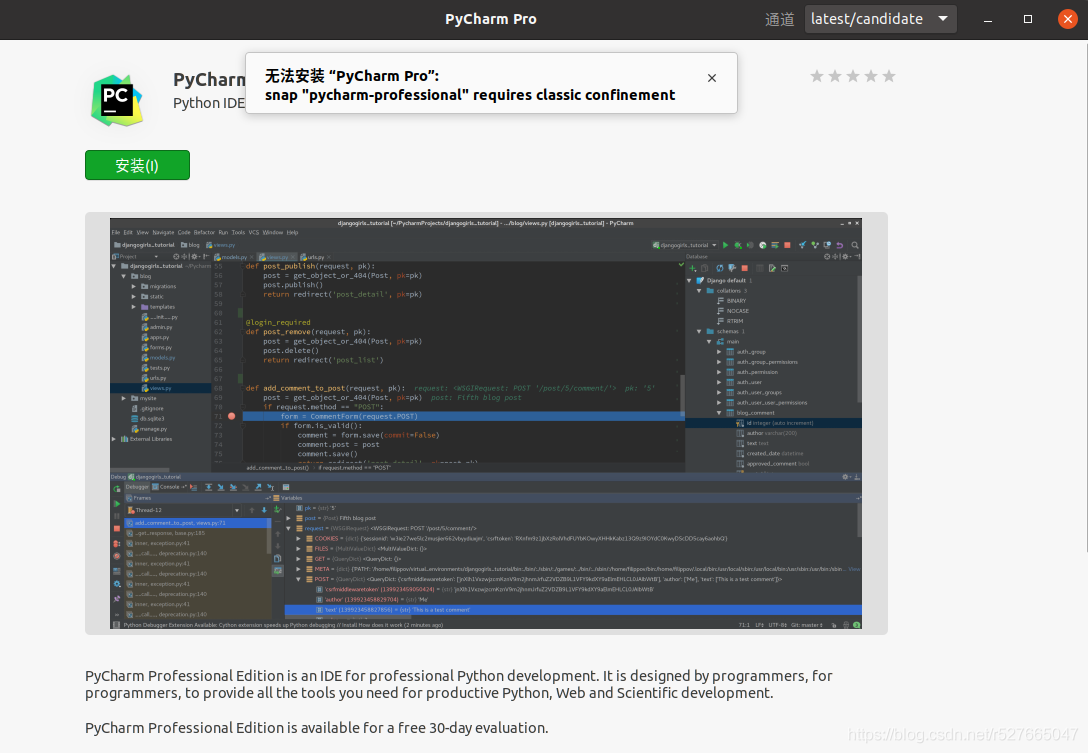
用windows思维理解,就是图片界面安装出错,需要在任务管理器先结束安装进程,然后DOS命令下重新安装。
查看命令如下:
snap changes

接下来我们把对应ID的进程关闭掉。我当前在安装的是pycharm专业版,它的ID为9,参考命令如下:
sudo snap abort 9

进程结束以后,直接用命令snap进行下载,不要用软件管理器下载,像我当前在下载的是pycharm的专业版(这下载速度不是一般的慢,但是懒得再去单独下载安装包)。命令参考:
snap install --classic pycharm-professional
图片参考如下:
超简单!Linux下FTP服务器的安装和配置(基于Ubuntu)
sudo apt-get install vsftpd
我这里已经是安装过了
二、配置vsftpd.conf文件,这里是不允许匿名登录的情况
1、进入etc目录
cd /etc/
2、进入编辑
sudo vi vsftpd.conf
3、去掉Listen=YES anonymous_enable=NO local_enable=YES write_enable=YES前面的#号
要注意的是,如果你没有涉及到ipv6地址,listen_ipv6=YES记得要注释掉,不然的话会出现connection refused,至少我是这样了TAT

4、在文件末尾插入
pasv_min_port=10060
pasv_max_port=10090
此为vsftpd被动模式(pasv)的端口范围
5、保存退出
三、添加FTP用户
1、在一个合适的地方创建文件夹,这个文件夹作为用户的根目录,并设置好权限。例如:/home/ubuntu/ftp
2、执行如下语句添加用户(username为用户名)
sudo useradd -d /home/ubuntu/ftp -s /bin/bash username
3、执行如下语句设置密码(username为用户名)
sudo passwd username
四、启动ftp服务
sudo service vsftpd start
五、Enjoy!
六、中文乱码问题:
配置最后一行,启用 utf8_filesystem=YES
Ubuntu下如何查看已安装软件版本
如何查看Ubuntu下安装过的全部软件。
-
查看安装的所有软件【带简介】
➜ ~ dpkg -l查看输出:
➜ ~ dpkg -l 期望状态=未知(u)/安装(i)/删除(r)/清除(p)/保持(h) | 状态=未安装(n)/已安装(i)/仅存配置(c)/仅解压缩(U)/配置失败(F)/不完全安装(H)/触发器等待(W)/触发器未决(T) |/ 错误?=(无)/须重装(R) (状态,错误:大写=故障) ||/ 名称 版本 体系结构: 描述 +++-==================================-======================-======================-========================================================================= ii a11y-profile-manager-indicator 0.1.10-0ubuntu3 amd64 Accessibility Profile Manager - Unity desktop indicator ii account-plugin-facebook 0.12+16.04.20160126-0u all GNOME Control Center account plugin for single signon - facebook ii account-plugin-flickr 0.12+16.04.20160126-0u all GNOME Control Center account plugin for single signon - flickr ii account-plugin-google 0.12+16.04.20160126-0u all GNOME Control Center account plugin for single signon -
查看软件安装的路径
dpkg -L | grep terminator查看输出
3.使用apt查看已安装版本
apt list --installed
查看输出
当然,需要找特定的软件,只需要后面跟grep就好了。
小结
dpkg -l大法好。
解决Could not load dynamic library 'libcudart.so.10.0'的问题
问题表现与分析
在安装了CUDA和CUDNN还有Tensorflow最新的2.0正式版本后,我在使用Pycharm写TF代码并运行时,遇到这样的问题

主要表现就是提示找不到动态库文件,扫了一眼文件名,都是CUDA的库文件,那怎么会说找不到
2019-10-15 19:19:41.440285: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1 2019-10-15 19:19:41.465433: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2019-10-15 19:19:41.465758: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties: name: GeForce RTX 2080 Ti major: 7 minor: 5 memoryClockRate(GHz): 1.665 pciBusID: 0000:01:00.0 2019-10-15 19:19:41.465809: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcudart.so.10.0'; dlerror: libcudart.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.465841: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcublas.so.10.0'; dlerror: libcublas.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.465870: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcufft.so.10.0'; dlerror: libcufft.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.465900: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcurand.so.10.0'; dlerror: libcurand.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.465930: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcusolver.so.10.0'; dlerror: libcusolver.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.465959: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcusparse.so.10.0'; dlerror: libcusparse.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.468179: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7 2019-10-15 19:19:41.468189: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1641] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform. Skipping registering GPU devices... 2019-10-15 19:19:41.468361: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA 2019-10-15 19:19:41.490938: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3696000000 Hz 2019-10-15 19:19:41.492057: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x520eba0 executing computations on platform Host. Devices: 2019-10-15 19:19:41.492085: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version 2019-10-15 19:19:41.559665: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2019-10-15 19:19:41.560029: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x5241a20 executing computations on platform CUDA. Devices: 2019-10-15 19:19:41.560040: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): GeForce RTX 2080 Ti, Compute Capability 7.5 2019-10-15 19:19:41.560084: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1159] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-10-15 19:19:41.560088: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1165] 2019-10-15 19:19:41.562457: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2019-10-15 19:19:41.562855: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties: name: GeForce RTX 2080 Ti major: 7 minor: 5 memoryClockRate(GHz): 1.665 pciBusID: 0000:01:00.0 2019-10-15 19:19:41.562913: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcudart.so.10.0'; dlerror: libcudart.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.562945: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcublas.so.10.0'; dlerror: libcublas.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.562975: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcufft.so.10.0'; dlerror: libcufft.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.563004: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcurand.so.10.0'; dlerror: libcurand.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.563032: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcusolver.so.10.0'; dlerror: libcusolver.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.563062: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcusparse.so.10.0'; dlerror: libcusparse.so.10.0: cannot open shared object file: No such file or directory 2019-10-15 19:19:41.563069: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7 2019-10-15 19:19:41.563073: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1641] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform. Skipping registering GPU devices... 2019-10-15 19:19:41.563080: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1159] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-10-15 19:19:41.563083: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1165] 0 2019-10-15 19:19:41.563086: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1178] 0: N 2019-10-15 19:19:41.563504: I tensorflow/core/common_runtime/direct_session.cc:359] Device mapping: /job:localhost/replica:0/task:0/device:XLA_CPU:0 -> device: XLA_CPU device /job:localhost/replica:0/task:0/device:XLA_GPU:0 -> device: XLA_GPU device
本来以为是因为我的环境变量没有配置清楚,但是试着测试了一下CUDA和CUDNN都在该在的位置,在终端上也能正常的运行
后面发现这个问题的出现是由于目前版本的Tensorflow还只能支持CUDA10.0,而英伟达的CUDA则是更新到了10.1,要解决这个问题,其实可以通过两个版本切换的方式来达到,要用哪个切换哪个
解决流程
下载CUDA10.0,我电脑上面已经配置了10.1版本了
wget https://developer.nvidia.com/compute/cuda/10.0/Prod/local_installers/cuda_10.0.130_410.48_linux添加可执行权限
sudo chmod +x cuda_10.0.130_410.48_linux
以sudo执行这个安装程序,记得这样选,只安装CUDA10.0但是不要安装驱动程序,选项可以参考我这边的截图


然后就会开始安装了,安装完成之后,sudo vim ~/.bashrc 修改环境变量,修改前如下

修改后,把这部分我们先前配置的删除,替换成如下,保存文件
export CUDA_HOME=/usr/local/cuda export LD_LIBRARY_PATH=/usr/local/cuda/lib64:"$LD_LIBRARY_PATH:/usr/loacl/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64" export PATH=/usr/local/cuda/bin:$PATH
使用 source ~/.bashrc 来应用环境配置,如果一切就绪,应该使用nvcc --version显示的就是CUDA 10.0版本了
arenascat@TensorSystem:~$ nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2018 NVIDIA Corporation Built on Sat_Aug_25_21:08:01_CDT_2018 Cuda compilation tools, release 10.0, V10.0.130
如果Pycharm那边再运行python还是没成功,就先把cuda目录文件删除,这个文件其实是一个软链接,之后,再重建一个链接就好了
sudo rm -rf /usr/local/cuda
sudo ln -s /usr/local/cuda-10.0/ /usr/local/cuda
再次运行调用了tensorflow-gpu的代码,可以看到已经成功的读取了库

如果要设置为CUDA 10.1的话,把上面的10.0改一改就行了
如果这个问题不能解决的话,再试试多设置一下环境变量,新建一个文件
sudo vi /etc/profile.d/cuda.sh把以下内容复制进去并保存
export PATH=$PATH:/usr/local/cuda/bin
export CUDADIR=/usr/local/cuda
这一个位置也要新建一个文件,如果你装了10.1可能里面会已经有一个cuda10.1.conf不用管它
sudo vi /etc/ld.so.conf.d/cuda.conf文件里面有这一句
/usr/local/cuda/lib64应用设置
sudo ldconfig
密码策略
最小密码长度
默认情况下,Ubuntu 需要 6 个字符的最小密码长度,以及一些基本的熵检查。这些值在文件中受控制,下面概述。/etc/pam.d/common-password
password [success=1 default=ignore] pam_unix.so obscure sha512如果要将最小长度调整为 8 个字符,请将相应的变量更改为最小值=8。修改概述如下。
password [success=1 default=ignore] pam_unix.so obscure sha512 minlen=8
密码过期
创建用户帐户时,应制定策略,规定用户具有最小和最大密码期限,强制用户在密码过期时更改其密码。
-
若要轻松查看用户帐户的当前状态,请使用以下语法:
sudo chage -l username下面的输出显示了有关用户帐户的有趣事实,即没有应用任何策略:
Last password change : Jan 20, 2015 Password expires : never Password inactive : never Account expires : never Minimum number of days between password change : 0 Maximum number of days between password change : 99999 Number of days of warning before password expires : 7 -
要设置这些值中的任何一个,只需使用以下语法,然后按照交互式提示操作:
sudo chage username以下是如何手动将显式到期日期 (-E) 更改为 01/31/2015、最低密码期限 (-m) 5 天、最大密码期限 (-M) 90 天、密码过期后 30 天的不活动期 (-I) 以及密码过期前 14 天的警告时间段 (-W) 的示例:
sudo chage -E 01/31/2015 -m 5 -M 90 -I 30 -W 14 username -
若要验证更改,请使用前面提到的相同语法:
sudo chage -l username下面的输出显示已为帐户建立的新策略:
Last password change : Jan 20, 2015 Password expires : Apr 19, 2015 Password inactive : May 19, 2015 Account expires : Jan 31, 2015 Minimum number of days between password change : 5 Maximum number of days between password change : 90 Number of days of warning before password expires : 14
禁用用户的 SSH 访问
如果用户以前设置过 SSH 公钥身份验证,则只需禁用/锁定用户密码不会阻止用户远程登录服务器。他们仍然能够获得对服务器的 shell 访问权限,而无需任何密码。请记住,请检查用户主目录中是否允许这种类型的经过身份验证的 SSH 访问的文件,例如 。/home/username/.ssh/authorized_keys
删除或重命名用户主文件夹中的目录,以防止进一步的 SSH 身份验证功能。.ssh/
请务必检查残障用户建立的任何 SSH 连接,因为它们可能具有现有的入站或出站连接。杀死任何找到的。
who | grep username (to get the pts/# terminal)
sudo pkill -f pts/#
仅对应具有 SSH 的用户帐户进行 SSH 访问。例如,您可以创建一个名为"sshlogin"的组,并将组名称添加为与文件中的变量关联的值。AllowGroups/etc/ssh/sshd_config
AllowGroups sshlogin
然后将允许的 SSH 用户添加到组"sshlogin",然后重新启动 SSH 服务。
sudo adduser username sshlogin
sudo systemctl restart sshd.service nmtui