from:https://www.knowledgehut.com/blog/programming/basics-of-python-programming
Python的一些功能使用户无法抗拒:
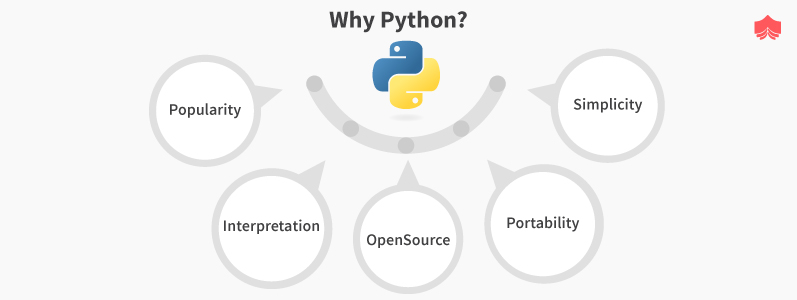
Popularity流行度: 根据2019年Stack Overflow开发者调查, Python被认为是第四大最受欢迎和增长最快的编程语言。Python被Google,YouTube,Instagram,Netflix,Spotify,Quora等世界上最著名的软件公司所使用。
Interpretation解释: Python是一种解释语言,这意味着程序直接传递给解释器,解释器直接执行它们。与编译器不同,编译器在运行之前将源代码转换为机器代码。
OpenSource开源: Python是在OSI批准的开源许可证下开发的一种免费语言,使其可以自由使用和分发,甚至用于商业目的。
Portability可移植性: Python代码是可移植的,这意味着在一个平台上编写的代码将在安装了Python解释器的任何其他平台上运行。
Simplicity简单性: Python的编码风格非常简单干净,这使得它易于阅读和学习。与其他语言(例如C ++或Java)相比,它使用的关键字更少。由于其整洁而有组织的代码结构,开发人员倾向于始终使用它。
prompt:提示窗口:
使用enumerate()而不是range() 执行迭代
>>> list_num = [30, 29, 10, 65, 95, 99] >>> for i in range(len(list_num)): if list_num[i] % 3 == 0 and list_num[i] %5 ==0: list_num[i] = 'fizzbuzz' elif list_num[i] %3 ==0: list_num[i]='fizz' elif list_num[i]%5 ==0: list_num[i]='buzz' >>> list_num ['fizzbuzz', 29, 'buzz', 'buzz', 'buzz', 'fizz']
尽管range()可以在许多迭代方法中使用,但在这种情况下最好使用enumerate(),因为它可以同时访问元素的索引和值:
>>> list_num = [30, 29, 10, 65, 95, 99] >>> for i,num in enumerate(list_num): if list_num[i] % 3 == 0 and list_num[i] %5 ==0: list_num[i] = 'fizzbuzz' elif list_num[i] %3 ==0: list_num[i]='fizz' elif list_num[i]%5 ==0: list_num[i]='buzz' >>> list_num ['fizzbuzz', 29, 'buzz', 'buzz', 'buzz', 'fizz']
内置函数:https://docs.python.org/zh-cn/3/library/functions.html
Python 标准库:https://docs.python.org/zh-cn/3/library/
IDLE:交互式命令行
#保护视力:https://gist.github.com/charygao/039a5906b385792dc1f257ddb6308897
.idlerc 目录下新建名为 config-highlight.cfg 文件,并加入如下内容
[tango]
definition-foreground = #fce94f
error-foreground = #fa8072
string-background = #2e3436
keyword-foreground = #8cc4ff
normal-foreground = #ffffff
comment-background = #2e3436
hit-foreground = #ffffff
break-foreground = #000000
builtin-background = #2e3436
stdout-foreground = #eeeeec
cursor-foreground = #fce94f
hit-background = #2e3436
comment-foreground = #73d216
hilite-background = #edd400
definition-background = #2e3436
stderr-background = #2e3436
break-background = #2e3436
console-foreground = #87ceeb
normal-background = #2e3436
builtin-foreground = #ad7fa8
stdout-background = #2e3436
console-background = #2e3436
stderr-foreground = #ff3e40
keyword-background = #2e3436
string-foreground = #e9b96e
hilite-foreground = #2e3436
error-background = #2e3436
[desert]
definition-foreground = #98fb98
error-foreground = #ff0000
string-background = #333333
keyword-foreground = #cc6600
normal-foreground = #f0e68c
comment-background = #333333
hit-foreground = #ffffff
break-foreground = black
builtin-background = #333333
stdout-foreground = #eeeeee
cursor-foreground = #ffcc00
hit-background = #333333
comment-foreground = #87ceeb
hilite-background = gray
definition-background = #333333
stderr-background = #333333
break-background = #ffff55
console-foreground = #87ceeb
normal-background = #333333
builtin-foreground = #519e51
stdout-background = #333333
console-background = #333333
stderr-foreground = #ff3e40
keyword-background = #333333
string-foreground = #ffa0a0
hilite-foreground = #000000
error-background = #000000
[Obsidian]
definition-foreground = #678CB1
error-foreground = #FF0000
string-background = #293134
keyword-foreground = #93C763
normal-foreground = #E0E2E4
comment-background = #293134
hit-foreground = #E0E2E4
builtin-background = #293134
stdout-foreground = #678CB1
cursor-foreground = #E0E2E4
break-background = #293134
comment-foreground = #66747B
hilite-background = #2F393C
hilite-foreground = #E0E2E4
definition-background = #293134
stderr-background = #293134
hit-background = #000000
console-foreground = #E0E2E4
normal-background = #293134
builtin-foreground = #E0E2E4
stdout-background = #293134
console-background = #293134
stderr-foreground = #FB0000
keyword-background = #293134
string-foreground = #EC7600
break-foreground = #E0E2E4
error-background = #293134
重启IDLE,依次选 Options -> Configure IDLE -> Highlighting

Python 的 IDLE 使用技巧
Shell 里
Alt + p:返回上一次的输入
Alt + n:与 Alt + p 相反
上面 p 的意思是 precious,n 的意思是 next
IDLE 里
Ctrl + [ :可以实现多行代码整体左移
Ctrl + ] :可以实现多行代码整体右移
. 操作符(点操作符)后使用 Tab 可以查看有哪些东西,嫌提示出来的太慢可以在 Options -> Configure IDLE -> Extension 里第一个那里配置
在未完成的变量后使用 Tab 产生提示
ALT + 3 : 批量注释
ALT + 4 :批量取消注释
ALT + / :自动补全
Options -> Configure IDLE -> Key 进入快捷键配置。
F5 : run;
回车:结束输入并运行;(自动确定是否输入结束,函数会多一空行);
增强
IDLE(3.7.5 以前) 里面没有行标等等功能,我们可以使用 idlex 来增强它。方法如下
pip3 install IDLEX首先下载这个插件,然后在 C:Program FilesPython36Scripts 下新建一个叫做 idlex.bat 的脚本,里面添加如下代码保存。
-
@echo off
-
rem Start IDLE using the appropriate Python interpreter
-
set CURRDIR=%~dp0
-
start "IDLE" "%CURRDIR%..pythonw.exe" "%CURRDIR%idlex.pyw" %1 %2 %3 %4 %5 %6 %7 %8 %9
然后创建个快捷方式放到桌面就可以了。
想要更改 IDLEX 的主题可以现在原来的 IDLE 里保存一个你喜欢的主题 a,然后同时在 IDELX 中保存一个主题 b。然后在 C:UsersAdministrator.idlerc 下找到 idlex-config-highlight.cfg,将其中 [b] 下面的配置替换为 idle-config-highlight.cfg 中 [a] 下的配置代码。
ps. Options -> Configure IDLE -> Highlighting 进入主题配置。
可以查看 IDLE 的帮助文档获取更多:Help-->IDLE Help
查看python安装路径
Linux下:which python
Windows下:where python

明显win10 打算集成python了。
使用列表推导[List Comprehensions]代替map() 和filter()
>>> list_num = [1, 2, 3, 4, 5, 6] >>> def square_num(z): return z*z >>> list(map(square_num, list_num)) [1, 4, 9, 16, 25, 36] >>> [square_num(z) for z in list_num] [1, 4, 9, 16, 25, 36]
>>> list_num = [1, 2, 3, 4, 5, 6] >>> def odd_num_check(z): return bool(z % 2) >>> list(filter(odd_num_check, list_num)) [1, 3, 5] >>> [z for z in list_num if odd_num_check(z)] [1, 3, 5]
使用breakpoint()而不是print()进行调试
调试是编写软件必不可少的部分,从长远来看它展示了Python工具知识,有助于快速开发。但最初使用print()调试一个小问题可能会很好,但代码将变得笨拙。
另一方面,使用像breakpoint()这样的调试器,将比print()更快。
如果您使用的是Python 3.7,则只需在代码中要调试的点上加上breakpoint()即可,而无需导入其他内容:
#带有错误的复杂代码Complicated Code With Bugs
...
...
...
breakpoint()#断点
每当调用breakpoint()时,您都会被放入Python Debugger- pdb中。但是,如果您使用的是Python 3.6或更早版本,则可以执行显式导入,就像调用breakpoint()一样:
import pdb; pdb.set_trace()#导入 pdb并设置跟踪
示例中,pdb.set_trace()将您放入pdb。由于难记,因此建议使用breakpoint()。您还可以尝试其他调试器。在面试之前习惯调试器将是一个很大的优势,但您可以随时回到pdb,因为它是Python标准库的一部分并且始终可用。
Formatting Strings with the help of f-Strings 用f-Strings格式化字符串
由于Python有许多不同的字符串格式化技术,因此应该使用哪种类型的字符串格式化很容易混淆。但是有个好方法是在Python 3.6或更高版本的编码中使用Python的f-String。
文字字符串插值(Literal String Interpolation字面字符串插值)或f-String是一种强大的,更具可读性,更简洁,更快速且更不易出错字的符串格式化技术。
它支持字符串格式化迷你语言(Format Specification Mini-Language),这使字符串插值更加简单。您还可以选择添加新变量和Python表达式,并且可以在运行时前对其进行求值:
>>> def name_and_age(name, age):
return f"My name is {name} and I'm {age / 10:.5f} years old."
>>> name_and_age("Alex", 21)
"My name is Alex and I'm 2.10000 years old."
使用f-String,您可以在一次操作中将Alex的名称添加到字符串中,并使用所需的格式类型将其添加到相应的年龄。
请注意,如果输出包含用户生成的值,则建议使用模板字符串(Template strings)https://docs.python.org/3/library/string.html#string.Template。
$$ is an escape; it is replaced with a single $.
$identifier names a substitution placeholder matching a mapping key of "identifier". By default, "identifier" is restricted to any case-insensitive ASCII alphanumeric string (including underscores) that starts with an underscore or ASCII letter. The first non-identifier character after the $ character terminates this placeholder specification.
${identifier} is equivalent to $identifier. It is required when valid identifier characters follow the placeholder but are not part of the placeholder, such as "${noun}ification".
$$替换为一个$。
$identifier指定与映射键“identifier”匹配的替换占位符。默认情况下,“identifier”仅限于任何以下划线或ASCII字母开头的不区分大小写的ASCII字母数字字符串(包括下划线)。$字符后的第一个非标识符字符终止此占位符规范。
${identifier}等效于$identifier。当有效的标识符字符跟在占位符后面但不是占位符的一部分时,如“${noun}ification”时,它是必需的。
>>> s = Template('$who likes $what')
>>> s.substitute(who='tim', what='kung pao')
'tim likes kung pao'
>>> d = dict(who='tim')
>>> Template('Give $who $100').substitute(d)
Traceback (most recent call last):
...
ValueError: Invalid placeholder in string: line 1, col 11
>>> Template('$who likes $what').substitute(d)
Traceback (most recent call last):
...
KeyError: 'what'
>>> Template('$who likes $what').safe_substitute(d)
'tim likes $what'
使用sorted()对复杂列表进行排序
有效利用数据结构数据结构是面试应该了解的概念之一。
Python的标准数据结构实现功能异常强大,并提供了许多默认功能,这些功能肯定会有助于编码面试。
Storing Values with Sets 用集合存储值
每当您想从现有数据集中删除重复元素时,请使用集合而不是列表。
考虑一个函数random_word,该函数总是从一组单词中返回一个随机单词:
>>> import random
>>> words = "all the words in the world".split()
>>> def random_word():
return random.choice(words)
>>> random_word()
'world'
>>> random_word()
'the'
>>> random_word()
'all'
在上面的示例中,您需要重复调用random_word以获得1000个随机选择,然后返回一个包含每个唯一单词的数据结构。
让我们看看执行此操作的三种方法–两种次优方法和一种好的方法。
不好的,错误的方法
将值存储在列表中然后转换为集合的示例:
>>> def unique_words():
words = []
for _ in range(1000):
words.append(random_word())
return set(words)
>>> unique_words()
{'the', 'all', 'words', 'in', 'world'} #{ 'planet','earth','to','words }
在此示例中,创建列表然后将其转换为集合是不必要的方法。面试官对这种设计会有此疑问。
>>> def unique_words():
words = []
for _ in range(1000):
word = random_word()
if word not in words:
words.append(word)
return words
>>> unique_words()
['words', 'in', 'all', 'the', 'world']
{ 'planet','earth','to','words }
这种方法更差,因为您必须将每个单词与列表中已经存在的每个其他单词进行比较。简单来说,这种情况下的时间复杂度比前面的示例要大得多。
好的方法
在此示例中,您可以从头开始跳过列表并完全使用 sets 集:
>>> def unique_words():
words = set()
for _ in range(1000):
words.add(random_word())
return words
>>> unique_words()
{'the', 'world', 'in', 'words', 'all'}
{ 'planet','earth','to','words }
此方法不同于第二种方法,因为此方法中的元素存储允许几乎恒定时间检查集合中是否存在值,而使用列表时需要线性时间查找。这种方法的时间复杂度为O(N),比第二种方法的时间复杂度以O(N²)的速率增长要好得多。
使用 Generators 生成器节省内存
尽管 lists comprehensions 列表理解是方便的工具,但它可能导致过多使用内存。
考虑一种情况,您需要使用列表推导 list comprehensions 来找到以1开头的前1000个平方的和:
>>> sum([z * z for z in range(1, 1001)])
333833500
您的解决方案通过列出每个完美正方形的列表来返回正确答案,然后对这些值求和。但是,面试官要求计算更大的数字的平方和。
最初,您的程序可能运行良好,但会逐渐变慢,并且过程将完全更改。
但您可以通过将方括号替换为圆括号来解决此内存问题:
>>> sum((z * z for z in range(1, 1001)))
333833500
当您从方括号更改为圆括号时,列表理解 list comprehension 将更改为 generator 生成器表达式。它返回一个生成器对象。该对象仅在需要时才计算下一个值。
生成器 Generators 主要用于海量数据序列,以及需要从序列中检索数据但又不想同时访问所有数据的情况。
使用.get()和.setdefault()定义字典中的默认值
从字典中添加,修改或检索项目是编程中最原始的任务之一,并且使用Python功能很容易执行。但是,开发人员通常会明确检查值,即使不是必需的值。
考虑一种情况,其中存在一个名为shepherd的字典,并且您想通过有条件地显式检查key来获得牛仔的名字:
牧羊犬shepherd
>>> shepherd = {'age': 20, 'sheep': 'yorkie', 'size_of_hat': 'large'}
>>> if 'name' in shepherd:
name = shepherd['name']
else:
name = 'The Man with No Name'
>>> name
'The Man with No Name'
在此示例中,在字典中搜索键名,并返回相应的值,否则返回默认值。
您可以在一行中使用.get()而不是显式检查键:
>>> name = shepherd.get('name', 'The Man with No Name')
get()与第一种方法执行相同的操作,但是现在可以自动处理它们。
但.get()函数无法在需要使用默认值更新字典的同时访问同一key键。在这种情况下,您需要使用显式检查:
>>> if 'name' not in shepherd:
shepherd['name'] = 'The Man with No Name'
>>> name = shepherd['name']
>>> name
'The Man with No Name'
然而,Python还提供了一种使用.setdefault()的更优雅方法:
>>> name = shepherd.setdefault('name', 'The Man with No Name')
.setdefault()操作同前一方法。如果 shepherd 中存在name,它将返回name的值,否则将shepherd ['name']设置为“无名男子”,并返回该新值。
利用Python标准库
Python的功能本身很强大,所有东西都可以通过使用import语句访问。如果您知道如何充分利用标准库,它将提高您的编码面试技巧。
如何处理遗漏的字典 missing dictionaries ?
若要为单个键设置默认值,可以使用.get()和.setdefault()。但在某些情况下,您需要为所有可能的未设置键设置默认值,尤其是在编码面试中。
假设(Consider)您有一群学生,您要跟踪他们在作业中的成绩。输入值是一个带有Student_name和成绩的元组。您想查看单个学生的所有成绩,而无需遍历整个列表。
使用字典存储成绩数据的示例:
>>> grades_of_students = {}
>>> grades = [
('alex', 89),
('bob', 95),
('charles', 81),
('alex', 94),
]
>>> for name, grade in grades:
if name not in grades_of_students:
grades_of_students[name] = []
grades_of_students[name].append(grade)
>>> grades_of_students
{'alex': [89, 94], 'bob': [95], 'charles': [81]}
在上面的示例中,您遍历列表并检查名称是否已存在于字典中。如果不是,则将它们添加到带有空列表的字典中,然后将其实际成绩附加到学生的成绩列表中。
虽然,这个方法很好,但是使用defaultdict可以更简洁地解决这种情况:
>>> grades = [
('alex', 89),
('bob', 95),
('charles', 81),
('alex', 94),
]
>>> from collections import defaultdict
>>> student_grades = defaultdict(list)
>>> for name, grade in grades:
student_grades[name].append(grade)
>>> student_grades
defaultdict(<class 'list'>, {'alex': [89, 94], 'bob': [95], 'charles': [81]})
在这种方法中,将创建一个defaultdict,它使用没有参数的list()。list()返回一个空列表。如果名称不存在,则defaultdict调用list(),然后附加 grade 成绩。
使用defaultdict,您可以一次性处理所有的通用默认值,而不必担心具体某个key键级别的默认值。并且它生成了更简洁的程序代码。
如何计算哈希对象?
假设您有一长串没有标点符号或大写字母的单词文本,要求您对每个单词的出现频率次数进行统计。在这种情况下,您可以使用collections.Counter,用0作为任何缺少的元素默认值,使统计不同对象的个数更加容易和简洁:
>>> from collections import Counter
>>> words = "if I am there but if
... he was not there then I was not".split()
>>> counts = Counter(words)
>>> counts
Counter({'if': 2, 'I': 2, 'there': 2, 'was': 2, 'not': 2, 'am': 1, 'but': 1, '...': 1, 'he': 1, 'then': 1})
当列表传递给Counter时,它将存储每个单词以及该单词在列表中的出现次数。
如果您想了解上述字符串列表中的两个最常见的单词,则可以使用.most_common(),它仅通过count返回n个最频繁的输入:
>>> counts.most_common(2)
[('if', 2), ('I', 2)]
如何访问通用字符串组?How to Access Common String Groups?
如果要检查是否“ A”>“ a”,则必须使用ASCII图表进行操作。答案将是错误的,因为A的ASCII值为65,而a的值为97,这显然更大。
但是,要记住小写和大写ASCII字符的ASCII码将是一项艰巨的任务,而且此方法有点笨拙。您可以使用字符串模块(https://docs.python.org/3/library/string.html)中更容易使用的常量。
检查字符串中所有字符是否都大写的示例:
>>> import string
>>> def check_if_upper(word):
for letter in word:
if letter not in string.ascii_uppercase:
return False
return True
>>> check_if_upper('Thanks Alex')
False
>>> check_if_upper('ROFL')
True
函数check_if_upper遍历单词中的字母,并检查字母是否为string.ascii_uppercase的一部分。设置的文字是“ABCDEFGHIJKLMNOPQRSTUVWXYZ”。
常用字符串常量如下:
string.ascii_letters
string.ascii_upercase
string.ascii_lowercase
string.ascii_digits
string.ascii_hexdigits
string.ascii_octdigits
string.ascii_punctuation
string.ascii_printable
string.ascii_whitespace
结论
自信而轻松地完成面试是一项技能。您可能是一名优秀的程序员,但这只是版图的一小部分。
您可能无法通过一些面试,但是如果您遵循一个好的过程,从长远来看肯定会对您有帮助。
热情是一个重要因素,它将对您的面试结果产生巨大影响。
除此之外,还有练习。练习总是有帮助的。复习所有常见的面试概念,然后开始练习不同的面试题。如果您可以正确沟通和互动,则采访者还会在采访过程中提供帮助。提出问题,并始终通过蛮力和优化的解决方案进行交谈。
现在让我们总结一下到目前为止在本文中学到的内容:
使用enumerate()遍历索引和值。
用breakpoint()调试有问题的代码。
使用f字符串有效地格式化字符串。
使用自定义参数对列表进行排序。
使用生成器而不是列表推导来节省内存。
在查找字典键时定义默认值。
用collections.Counter类对可哈希对象进行计数。
如何运行您的Python脚本
如果您打算进入Python编程领域,那么您应该学习的第一项也是最基本的技能就是知道如何运行Python脚本和代码。这将更容易理解代码是否真正起作用。
作为领先的编程语言之一,Python具有相对简单的语法,这对于那些刚开始学习该语言的人来说更加容易。同样,它是处理大型数据集和数据科学项目的首选语言。
代码,脚本和模块有什么区别?Code, Script and Modules
在计算中,代码code 是从人类语言转换为计算机可以理解的一组“单词”的语言。它也被称为一起构成一个程序的一条语句。简单的函数或语句也可以视为代码。
另一方面,脚本script 是由指令的逻辑顺序组成的文件或由其他程序而不是计算机处理器解释的批处理文件。简单来说,脚本script 是一个简单程序,存储在包含Python代码的纯文本文件中。该代码可以由用户直接执行。脚本也称为顶级程序文件 top-level-program-file.。
模块module 是在Python的对象与可以随机结合并参考的属性特征。
Python是编程语言(编译型)还是脚本语言?
基本上,所有脚本语言都被视为编程语言。两者之间的主要区别在于,编程语言是编译的,而脚本语言是解释的。
脚本语言比编程语言慢,通常位于它们的后面。由于它们仅在一部分编程语言上运行,因此对计算机本地功能的访问较少。
Python既可以作为编译器也可以作为解释器,因此可以称为脚本语言和编程语言。标准的Python可以将Python代码编译为字节码,然后像Java和C一样对其进行解释。
但是,考虑到通用编程语言和脚本语言之间的历史关系,更恰当地说Python是一种通用编程语言,它也可以很好地用作脚本语言。
Python解释器
该解释器是一个软件层,它作为程序和系统硬件来保持代码的运行之间的桥梁。Python解释器是负责运行Python脚本的应用程序。
Python解释器可在Read-Eval-Print-Loop(REPL)环境中工作。
读取命令。
评估命令。
打印结果。
循环返回,过程重复进行。
当我们使用exit()或quit()命令时,解释器终止,否则执行将继续进行。
Python解释器以两种方式运行代码:
以脚本或模块的形式。
以在交互式会话中编写的一段代码的形式。
启动Python解释器
启动解释器的最简单方法是打开终端,然后从命令行使用解释器。
要打开命令行解释器:
在Windows上,命令行称为命令提示符或MS-DOS控制台。一种更快速的访问方法是进入“ 开始”菜单 → “运行”,然后键入cmd。
在GNU / Linux上,可以通过xterm,Gnome Terminal或Konsole等多个应用程序访问命令行。
在MAC OS X上,可以通过应用程序→实用程序→终端访问系统终端。 Applications → Utilities → Terminal.
交互式运行Python代码
通过交互式会话运行Python代码是一种广泛使用的方法。交互式会话是一种很好的开发工具,可以尝试使用该语言,并且可以让您随时随地测试每段Python代码。
要启动Python交互式会话,请在命令行或终端中键入python,然后按键盘上的ENTER键。
终端上的>>>表示交互模式的标准提示。如果看不到这些字符,则需要在系统上重新安装Python。
解释器运行Python脚本
术语“ Python执行模型”Python Execution Model被赋予运行Python脚本的整个多步骤过程。
1.解释器会按顺序处理脚本的语句或表达式。
2.将代码编译成一种称为字节码 bytecode 的指令集形式。
基本上,代码被转换为称为字节码的低级语言。它是与机器无关的中间代码,可优化代码执行过程。因此,下一次执行代码时,解释器将忽略编译步骤。
3.解释器传输代码以执行。
Python虚拟机(PVM)是Python解释器过程的最终步骤。它是系统中安装的Python环境的一部分。PVM在Python运行时中加载字节码,并读取每个操作并按照指示执行它们。它是实际运行脚本的组件。
使用命令行运行Python脚本
编写Python程序最受追捧的方法是使用纯文本编辑器。会话关闭后,Python交互式会话中编写的代码会丢失,尽管它允许用户编写很多行代码。在Windows上,文件使用.py扩展名。
现在,您需要创建一个测试脚本。为此,请打开最合适的文本编辑器并编写以下代码:
print('Hello World!')
然后将文件以first_script.py或您喜欢的任何名称保存在桌面中。请记住,您只需要提供.py扩展名。
使用python命令
运行Python脚本的最基本,最简单的方法是使用python命令。您需要打开一个命令行,然后输入单词python,然后输入脚本文件的路径,如下所示:
python first_script.py
Hello World!
重定向输出
Windows和类Unix系统具有称为流重定向的过程。您可以将流的输出重定向到其他文件格式,而不是标准系统输出。将输出保存在其他文件中以供以后分析很有用。
python first_script.py> output.txt
发生的情况是您的Python脚本被重定向到output.txt文件。如果文件不存在,则系统地创建它。但是,如果已经存在,则替换其内容。
使用-m选项运行模块
模块是包含Python代码的文件。它允许您以逻辑方式排列Python代码。它定义了函数,类和变量,还可以包括可运行的代码。
如果要运行Python模块,Python会根据用户的需求提供许多命令行选项。命令之一
python -m
它在 sys.path中搜索模块名称,并将运行以下内容
__main__:
python -m first_script
Hello World!
请注意,模块名称是模块对象,而不是任何字符串。
使用脚本文件名
Windows利用系统寄存器和文件关联来运行Python脚本。它确定运行该特定文件所需的程序。您只需输入包含代码的文件名。
有关如何使用命令提示符执行此操作的示例:
C:UsersLocalPythonPython37> first_script.py
Hello World!
在GNU / Linux系统上,您需要在文本之前添加一行— #!/ usr / bin / env python。Python不会考虑这一行,但操作系统会考虑所有内容。它有助于系统确定应使用哪个程序来运行文件。
字符组合#!称为hashbang或shebang认领 表示开头行,接着解释器路径。
最后,要运行脚本,请分配执行权限并配置hashbang行,然后只需在命令行中键入文件名即可:
#Assign the execution permissions分配执行权限
chmod +x first_script.py
#Run script using its filename使用脚本名称运行脚本
./first_script.py
Hello World!
但是,如果它不起作用,则可能要检查脚本是否位于当前工作目录中。否则,您要检查文件的路径。
交互式运行Python脚本
正如我们之前所讨论的,在交互式会话中运行Python脚本是编写脚本的最常见方式,并且还提供了广泛的可能性。
使用导入Using import
导入模块意味着加载其内容,以便之后访问和使用。这是调用其他模块的最常用方法。它类似于C或C ++中的#include。使用import,一个模块中的Python代码可以访问另一个模块中的代码。
import first_script
Hello World!
仅当模块包含对产生可见输出的函数,方法或其他语句的调用时,您才能看到其执行。
需要注意的重要一件事是,导入选项每个会话仅工作一次。这是因为这些操作很昂贵。
为了使此方法有效运行,应将包含Python代码的文件保留在当前工作目录中,并且该文件也应位于Python模块搜索路径(PMSP)中。PMSP是导入模块和软件包的地方。
您可以运行下面的代码来了解当前的PSMP:
import sys
for path in sys.path:
print(path)
UsersLocalPython37Libidlelib
UsersLocalPython37python37.zip
UsersLocalPython37DLLs
UsersLocalPython37lib
UsersLocalPython37
UsersLocalPython37libsite-packages
您将获得目录和.zip文件的列表,这些目录和.zip文件将模块和包导入其中。
使用importlib
importlib是一个模块,是Python代码中import语句的实现。它包含import_module,其工作是通过模仿导入操作来执行任何模块或脚本。
import importlib
importlib.import_module('first_script')
Hello World!
importlib.reload()用于重新导入模块,因为您不能使用import来第二次运行它。即使您是第一次使用import,也不会执行任何操作。当您想要修改和测试更改而不退出当前会话时,importlib.reload()很有用。
import first_script #First import
Hello World!
import first_script
import importlib #Second import does nothing
importlib.reload(first_script)
Hello World!
但是,您只能使用模块对象,而不能使用其他字符串作为reload()的参数。如果使用字符串作为参数,则它将显示TypeError,如下所示:
importlib.reload(first_script)
Traceback (most recent call last):#追溯(最近一次通话):
...
...
raise TypeError("reload() argument must be a module")
TypeError: reload() argument must be a module
使用runpy.run_module()和runpy.run_path()
在Python标准库(https://docs.python.org/3/library/index.html)有一个名为模块runpy。run_module()是 runpy中的一个函数,其功能是执行模块而不首先导入它们。
使用导入找到模块,然后执行。run_module()的第一个参数必须包含一个字符串:
import runpy
runpy.run_module(mod_name='first_script')
Hello World!
{'__name__': 'first_script',
...
'_': None}}
同样,runpy包含另一个函数run_path(),您可以通过提供位置来运行模块。
import runpy
runpy.run_path(file_path='first_script.py')
Hello World!
{'__name__': '',
...
'_': None}}
这两个函数都返回已执行模块的全局字典。
使用exec()
除了最常用的运行Python脚本的方法外,还有其他替代方法。一种这样的方式是通过使用内置函数exec()。它用于动态执行Python代码,无论是字符串还是目标代码。
exec(open('first_script.py').read())
Hello World!
使用py_compile
py_compile是一个行为类似于import语句的模块。它生成两个函数-一个从源文件生成字节码,另一个在将源文件作为脚本调用时生成。
您可以使用以下模块编译Python脚本:
import py_compile
py_compile.compile('first_script.py'
'__pycache__\first_script.cpython-37.pyc'
该py_compile生成一个名为“新子目录__pycache__ ”如果它不存在。在子目录中,创建了脚本文件的编译Python文件(.pyc)版本。打开.pyc文件时,您可以看到Python脚本的输出。
使用IDE或文本编辑器运行Python脚本
集成开发环境(IDE)是允许开发人员在集成环境中构建软件以及所需工具的应用程序。
您可以使用Python IDLE(标准Python发行版的默认IDE)来编写,调试,修改和运行模块和脚本。您可以使用其他IDE,例如Spyder,PyCharm,Eclipse和Jupyter Notebook,它们也允许您在其环境中运行脚本。
您还可以使用流行的文本编辑器(例如Sublime和Atom)来运行Python脚本。
如果要从IDE或文本编辑器运行Python脚本,则需要首先创建一个项目。创建之后,将您的.py文件添加到其中,或者您只需使用IDE创建一个即可。最后,运行它,您可以在屏幕上看到输出。
从文件管理器运行Python脚本
如果要在文件管理器中运行Python脚本,则只需双击文件图标即可。释放源代码后,此选项主要用于生产阶段。
但是,要实现这一点,必须满足一些条件:
在Windows上,要通过双击脚本来运行脚本,需要将脚本文件保存为.py(对于python.exe)和.pyw(对于pythonw.exe)。
如果使用命令行运行脚本,则可能会遇到屏幕上出现黑色窗口闪烁的情况。为了避免这种情况,请在脚本的末尾添加一条语句-input ('Enter')。仅当您按ENTER键时,这才退出程序。请注意,只有在代码没有错误的情况下,input()函数才有效。
在GNU / Linux和其他类似Unix的系统上,您的Python脚本必须包含hashbang行和执行权限。否则,双击把戏将无法在文件管理器中使用。
尽管只需双击文件即可执行脚本,但由于其附带的限制和依赖性因素(例如操作系统,文件管理器,执行权限,文件关联)因此不可行。
因此建议仅在调试代码并准备将其投入生产市场后使用此选项。
结论
使用脚本有其自身的优势,例如易于学习和使用,更快的编辑和运行,交互性,功能等等。它们还以简化的方式用于自动化复杂的任务。
在本文中,您学习了如何使用以下命令运行Python脚本:
操作系统的终端或命令行。
Python交互式会话。
您最喜欢的IDE或文本编辑器。
系统文件管理器。