5. XGBoost实例
本篇文章所有数据集和代码均在我的GitHub中,地址:https://github.com/Microstrong0305/WeChat-zhihu-csdnblog-code/tree/master/Ensemble%20Learning/XGBoost
5.1 安装XGBoost依赖包
pip install xgboost5.2 XGBoost分类和回归
XGBoost有两大类接口:XGBoost原生接口 和 scikit-learn接口 ,并且XGBoost能够实现分类和回归两种任务。
(1)基于XGBoost原生接口的分类
from sklearn.datasets import load_iris import xgboost as xgb from xgboost import plot_importance from matplotlib import pyplot as plt from sklearn.model_selection import train_test_split # read in the iris data iris = load_iris() X = iris.data y = iris.target # split train data and test data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # set XGBoost's parameters params = { 'booster': 'gbtree', 'objective': 'multi:softmax', # 回归任务设置为:'objective': 'reg:gamma', 'num_class': 3, # 回归任务没有这个参数 'gamma': 0.1, 'max_depth': 6, 'lambda': 2, 'subsample': 0.7, 'colsample_bytree': 0.7, 'min_child_weight': 3, 'silent': 1, 'eta': 0.1, 'seed': 1000, 'nthread': 4, } plst = params.items() dtrain = xgb.DMatrix(X_train, y_train) num_rounds = 500 model = xgb.train(plst, dtrain, num_rounds) # 对测试集进行预测 dtest = xgb.DMatrix(X_test) ans = model.predict(dtest) # 计算准确率 cnt1 = 0 cnt2 = 0 for i in range(len(y_test)): if ans[i] == y_test[i]: cnt1 += 1 else: cnt2 += 1 print("Accuracy: %.2f %% " % (100 * cnt1 / (cnt1 + cnt2))) # 显示重要特征 plot_importance(model) plt.show()
2)基于Scikit-learn接口的回归
这里,我们用Kaggle比赛中回归问题:House Prices: Advanced Regression Techniques,地址:https://www.kaggle.com/c/house-prices-advanced-regression-techniques 来进行实例讲解。
该房价预测的训练数据集中一共有81列,第一列是Id,最后一列是label,中间79列是特征。这79列特征中,有43列是分类型变量,33列是整数变量,3列是浮点型变量。训练数据集中存在缺失值。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer import xgboost as xgb from sklearn.metrics import mean_absolute_error # 1.读文件 data = pd.read_csv('./dataset/train.csv') data.dropna(axis=0, subset=['SalePrice'], inplace=True) # 2.切分数据输入:特征 输出:预测目标变量 y = data.SalePrice X = data.drop(['SalePrice'], axis=1).select_dtypes(exclude=['object']) # 3.切分训练集、测试集,切分比例7.5 : 2.5 train_X, test_X, train_y, test_y = train_test_split(X.values, y.values, test_size=0.25) # 4.空值处理,默认方法:使用特征列的平均值进行填充 my_imputer = SimpleImputer() train_X = my_imputer.fit_transform(train_X) test_X = my_imputer.transform(test_X) # 5.调用XGBoost模型,使用训练集数据进行训练(拟合) # Add verbosity=2 to print messages while running boosting my_model = xgb.XGBRegressor(objective='reg:squarederror', verbosity=2) # xgb.XGBClassifier() XGBoost分类模型 my_model.fit(train_X, train_y, verbose=False) # 6.使用模型对测试集数据进行预测 predictions = my_model.predict(test_X) # 7.对模型的预测结果进行评判(平均绝对误差) print("Mean Absolute Error : " + str(mean_absolute_error(predictions, test_y)))
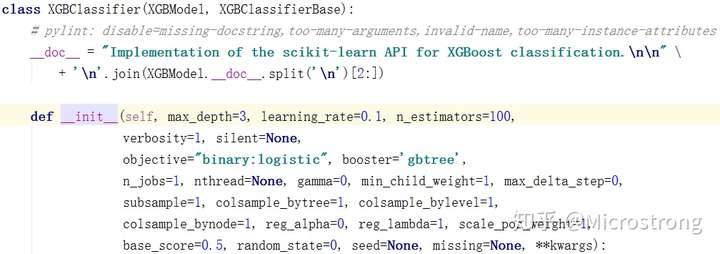
5.3 XGBoost调参
在上一部分中,XGBoot模型的参数都使用了模型的默认参数,但默认参数并不是最好的。要想让XGBoost表现的更好,需要对XGBoost模型进行参数微调。下图展示的是分类模型需要调节的参数,回归模型需要调节的参数与此类似。