0 - 背景
R-CNN中检测步骤分成很多步骤,fast-RCNN便基于此进行改进,将region proposals的特征提取融合成共享卷积层问题,但是,fast-RCNN仍然采用了selective search来进行region proposals的预测,者称为性能的瓶颈(selective search不能在GPU上运行,还没搞懂为何?)。因此faster-RCNN提出采用RPN网络来生成region proposals,且RPN和ROI Pooling之前的特征提取共享特征提取卷积层来加速模型。
R-CNN/fast-RCNN/faster-RCNN的对比图如下(图来自博客)

1 - 整体思路
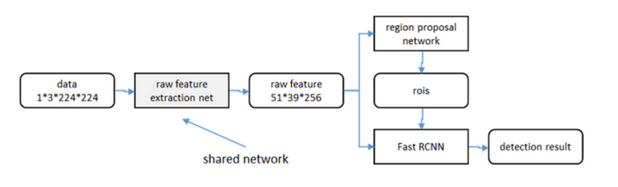

(图来自博客)
1.1 - Region Proposal Networks(RPN)
RPN网络将一张图片(大小不限制)作为输入,输出一系列的proposals,并且每一个都有非背景(前景)得分。
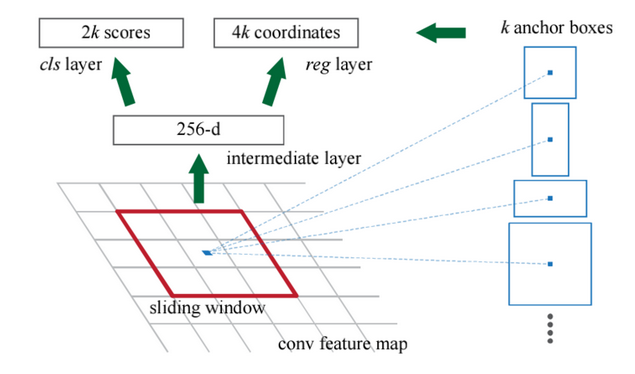
(图来自博客)
1.2 - Anchors
参照图片金字塔思想,对于窗口(sliding windows)的每一个坐标,同时预测k个尺度的proposals,因此CLS有2k个输出(即每一个proposal是否为背景),reg有4k个输出(即对该边框回归偏移量),对于同一个位置的k个proposals称之为anchor,其可以通过面积以及长宽比进行定义。文中采用了9个anchor:三种面积$\{128^2,256^2,512^2\}\times$三种比例$\{1:1,1:2,2:1\}$。

注意到,由于Anchors是对称出现了,所以保证了Translation-Invariant Anchors(翻转不变性),即对于同一个物体被翻转但仍然可以用相同的函数进行预测。
1.3 - 窗口分类&位置精修
分类层输出每一个位置上anchor属于前景还是背景的概率(从proposal提取出256维特征),窗口回归层输出每一个位置上anchor对应窗口与真实边界框的平移缩放参数(4个平移缩放参数)。
1.4 - 训练
1.4.1 - 样本
考虑训练集中的每张图片:
- 对于每个标注了真实边界框的位置,与其IOU最大的anchor记为前景样本
- 对第一步剩下的anchor,若其与真实边界框的IOU值大于0.7,记为前景样本,如果小于0.3,记为背景样本
- 对于上述两步剩下的anchor丢弃不用
- 跨越图像边界的anchor丢弃不用
1.4.2 - 损失函数
$$L({p_i},{t_i})=\frac{1}{N_{cls}}\sum_{i}L_{cls}(p_i,p_i^*)+\lambda \frac{1}{N_{reg}}\sum_{i}p_i^*L_{reg}(t_i,t_i^*)$$
1.4.3 - 近似联合训练
在SGD过程中,在训练的时候先前向传播,产生proposals后就认为proposlas是固定的,接着用其训练Fast RCNN,损失函数是它们共同的损失函数,这种方法同时迭代两个网络的参数,作者认为效果不好(我认为是将共有的特征抽取分离了?)
1.4.4 - 交替训练
- 从$W_0$开始,训练PRN,用PRN提取训练集上的proposals
- 从$W_0$开始,用proposals训练Fast RCNN,参数记为$W_1$
- 从$W_1$开始,训练PRN
执行两次迭代,并且在训练时冻结部分共享层,可以达到不错的效果。
2 - 实验
相比Fast RCNN消除了selective search的性能瓶颈,提高了模型效率。且与使用selective search方法相比,每张图生成的proposals从2000减少到300时,RPN方法(红蓝)的召回率下降不大,这说明RPN目的性更明确。

使用更大的Miscrosoft COCO库训练,直接在PASCAL VOC上测试,准确率提高6%,说明faster RCNN的泛化能力(迁移能力)良好,没有在训练集上过拟合。

3 - 参考资料
https://segmentfault.com/a/1190000012789608
https://blog.csdn.net/shenxiaolu1984/article/details/51152614
https://www.cnblogs.com/CZiFan/p/9903518.html