0 - 背景
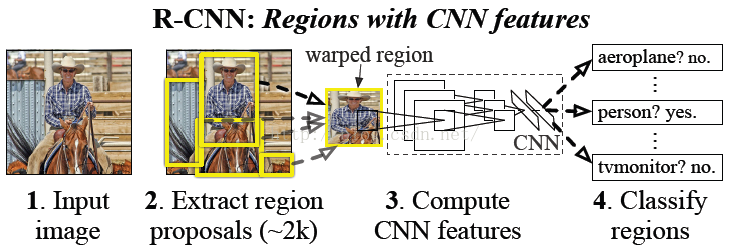
该论文是2014年CVPR的经典论文,其提出的模型称为R-CNN(Regions with Convolutional Neural Network Features),曾经是物体检测领域的state-of-art模型。
1 - 相关知识补充
1.1 - Selective Search
该算法用来产生粗选的regions区域,在我的另一篇博文Selective Search for Object Recognition(理解)中进行详细讲解。
1.2 - 无监督预训练&有监督预训练
1.2.1 - 无监督预训练(Unsupervised pre-traning)
栈式自编码、DBM采用的都是无监督预训练,预训练阶段样本不需要人工标注数据。(详细思路后续再进行补充)
1.2.2 - 有监督预训练(Supervised pre-training)
有监督预训练可以称为迁移学习,通过在别的训练集上训练好网络之后将参数作为当前任务网络的初始化参数,相比直接采用随机初始化等方法其精度有很大提高。
在该论文提出的时候,图片分类的训练数据相比物体检测的数据多得多,因此通过用分类数据集预训练网络而后再将参数用于目标检测网络参数的初始化,是该论文的一个亮点。
1.3 - IOU
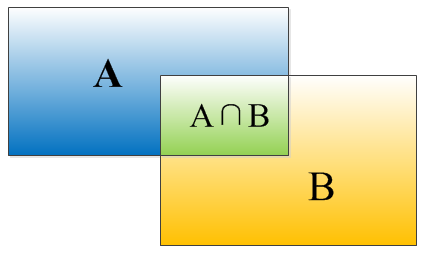
IOU是算法给出的bounding box和真实box的匹配程度,其计算公式为$IOU=\frac{(A\cap B)}{(A\cup B)}$,等价于$IOU=\frac{S_I}{(S_A+S_B-S_I)}$
1.4 - 非极大值抑制
如下图,在检测一个目标时候算法可能会给出一堆的bounding boax,这时候需要判断哪些bounding box是没用的,将它们丢掉。先假设有6个bounding box,根据分类器类别分类概率做排序,从小到大分别属于目标概率为A、B、C、D、E、F。
- 从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU时候大于设定的阈值
- 假设B、D与F的重叠度超过阈值,那么就丢掉B、D;并标记第一个bounding box F是我们保留下来的
- 从剩下的bounding box A、C、E中,选择概率最大的E,然后判断A、C与E的重叠度,重叠度大于阈值就扔掉,并标记E是我们保留下来的第二个bounding box
- 重复上述过程,找到所有被保留下来的bounding box

2 - 整体思路
首先输入一张图片,通过selective search定位出2000个物体检测框,然后采用CNN提取每个候选框中图片的特征向量,特征向量的维度为4096维,而后采用线性SVM对每个特征向量进行分类。概括起来有如下三个步骤:
- 找出候选框
- 每一个候选框采用CNN提取特征向量
- 利用线性SVM对特征向量进行分类
- 对分类好的region proposal进行边界回归,用bounding box回归值校正原来的建议窗口,生成预测窗口坐标
2.1 - 各向异性&各向同性缩放
由于selective search生成出的候选框大小规模都不一样,而传统CNN要求输入的图像尺度必须是固定的,因此需要采用各向异性或者各向同性缩放的方法来对图像大小进行缩放。
2.1.1 - 各向异性缩放
不管图片的长宽比例,直接缩放成固定的$227 \times 227$,如下图(D)所示,优点是简单,缺点是很容易造成目标扭曲变形等等。
2.1.2 - 各向同性缩放
- 方法一:直接在原始图片中,把bounding box的边界扩展成需要的固定尺度,然后再进行裁剪,如果已经延伸到原始图片边界外,采用bounding box中的像素颜色均值进行填充,如下图(B)所示
- 方法二:先把bounding box裁剪出来,然后用固定的背景颜色填充成所需的固定大小尺度(背景颜色也是采用bounding box的像素颜色均值),如下图(C)所示

论文中还提出了padding处理,上图1、3行采用了padding=0,而2、4行采用了padding=16。经过试验,作者发现采用各向异性缩放、padding=16的精度最高(这里作者提出,图像扭曲的影响并没有我们直观感觉到的那么大)。
2.2 - 正负样本标注
上述产生的bounding box不可能刚刚好和人工标注的box完全匹配,因此我们需要对这些bounding box打上标签,方便下一步CNN训练使用。标注根据如下规则:
- 如果该bounding box与真实box的IOU大于0.5,则为正样本,打上对应物体类别的标签
- 否则为负样本,将其归为背景的类别
2.3 - 训练
2.3.1 - CNN网络架构
提取特征的CNN结构有两个可选方案:Alexnet和VGG 16,经过测试Alexnet精度为58.5%,VGG 16精度为66%,但VGG 16的计算量大约是Alexnet的7倍。
2.3.2 - CNN有监督预训练
目标检测的数据集较小,采用随机初始化参数则目前的训练量远远不够,因此先用ImageNet的分类数据集训练CNN,而后将模型结构微调成适应检测任务,直接采用分类模型参数,再做fine-tuning训练。(采用随机梯度下降优化方法,学习率大小为0.001)。
2.3.3 - fine-tuning阶段
采用selective search生成的候选框,将其处理到指定大小尺度,对上面有监督预训练后的CNN模型进行fine-tuning训练。假设要检测的物体类别有N类,则需要将预训练的CNN模型最后一层替换成N+1个输出的神经元(额外加1表示背景),这一层采用随机初始化方法,其他网络层参数不变,再采用SGD(随机梯度下降)训练就可以了。(注:SGD学习率选择为0.001,batch size为128,其中32个正样本+86个负样本)。
2.3.3 - 关于CNN的思考
疑问1:如果直接采用Alexnet作为特征提取器而不做fine-tuning训练是否可以?
论文中也对该想法进行了实验,实验结果表明直接采用网络中$p_5$的输出作为特征提取结果的精度跟$f_6$和$f_7$差不多,反而$f_6$提取到的特征还比$f_7$的精度略高。可以总结出一个规则,如果不针对特定任务进行fine-tuning,而是把CNN作为特征提取器,卷积层所学到的特征其实是基础的泛化的特征,而后续的全连接层更多的学习到是特定任务的表示。
疑问2:CNN的输出可以通过一个softmax层直接达成分类目的,为何还需要通过SVM进行分类?
通过上述正负样本标注过程可以知道,训练集中正样本远比负样本少,并且只要IOU大于0.5便标注为正样本(条件宽松),而CNN的效果跟训练数据的大小有一定关系,所以少量的标注数据对于CNN来说还是不够,而SVM更适用于少量样本,因此SVM的效果会比softmax好,所以作者采用了额外的SVM分类器。(注:通过实验发现,当IOU的阈值采用0.3的时候效果最好,采用0.0的时候下降了4个百分点,采用0.5的时候下降了5个百分点)
3 - 参考资料
https://blog.csdn.net/mydear_11000/article/details/51882818