前言
当前手机使用成为互联网主流,每天手机App产生大量数据,学习爬虫的人也不能只会爬取网页数据,我们需要学习如何从手机 APP 中获取数据,本文就以豆果美食为例,讲诉爬取手机App的流程
环境准备
- python3
- fiddler
- 一款支持桥接模式的安卓虚拟机(本文使用夜神模拟器)
需要准备的知识有:
- requests的使用
- mongodb的使用
- fiddler抓包工具的基本操作
- 线程池ThreadPoolExecutor的基本使用
项目开始
我们项目的目标是将豆果美食App中所有的菜谱都抓取下来到我们的本地数据库中
本文不再讲解fiddler、安卓模拟器、以及某些python第三方库的安装,不会的同学可以百度,非常简单的操作
我们抓取的流程大概就是
- 安卓模拟器使用代理连接至fiddler
- 打开安卓模拟器进行操作
- 分析fiddler抓到的数据
- 使用python模拟数据给服务器发送request请求得到响应数据
- 使用多线程抓取并在本地保存至数据库
1)安卓模拟器使用代理连接至fiddler
打开fiddler,进行设置 打开最上方菜单栏中的 Tools 菜单中的 Options 选项 即配置选项进行以下配置(主要就是前3项的配置)
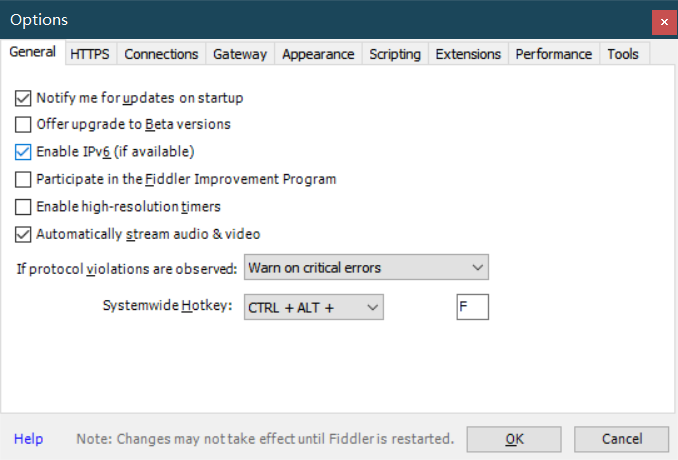
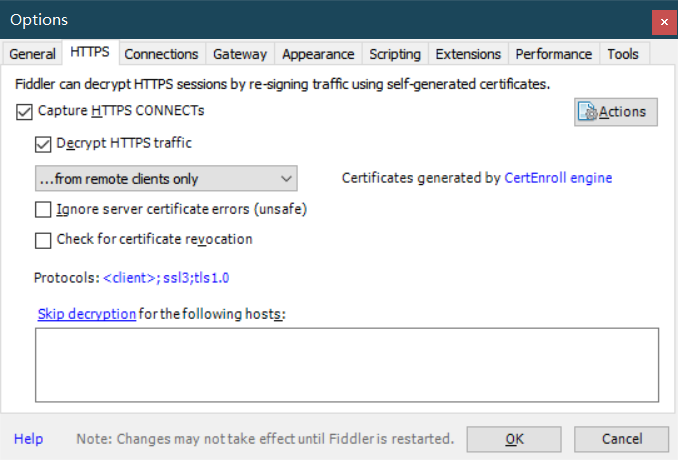
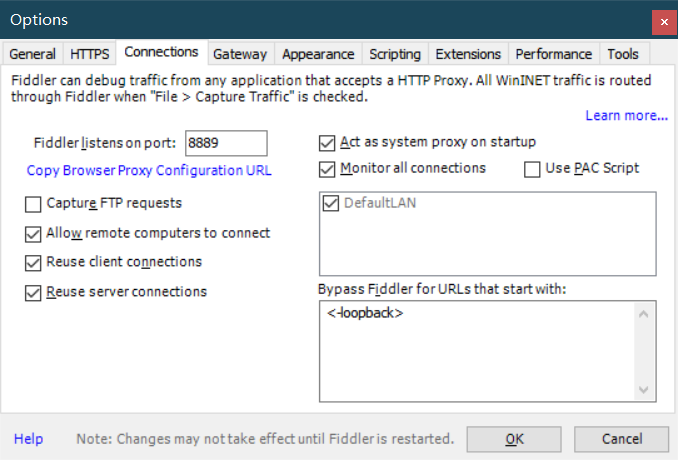
第三张图片中的8889就是我们fiddler监听的端口号,一会我们将模拟器配置代理就可以从fiddler中抓取数据包
打开安卓模拟器的网络连接的桥接模式(夜神模拟器包括此功能,此步骤需要重启),使用夜神的童鞋推荐使用android4 以为我一开始使用android5发现桥接模式无法联网
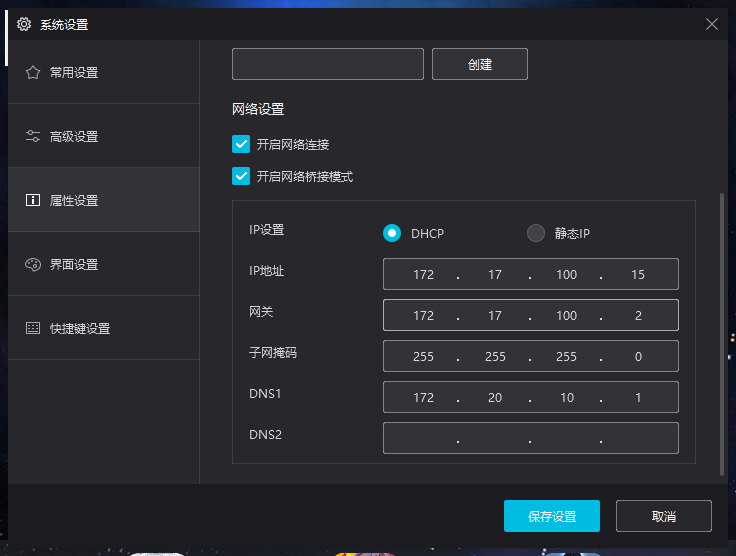
然后我们现在看下我们电脑的IP地址 打开命令行输入 ipconfig 命令即可
例如当前我的地址为 172.20.10.2 那么打开安卓模拟器的设置中的无线连接选项,长按网络名称如下图出现修改网络选项 接下来选择高级设置添加手动代理 将自己电脑的IP与fiddler中的端口号输入
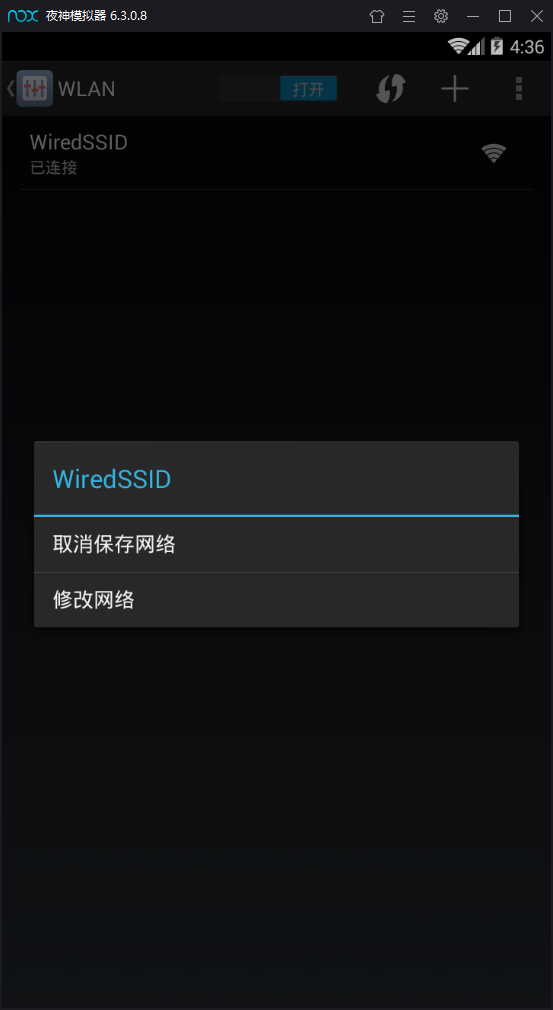
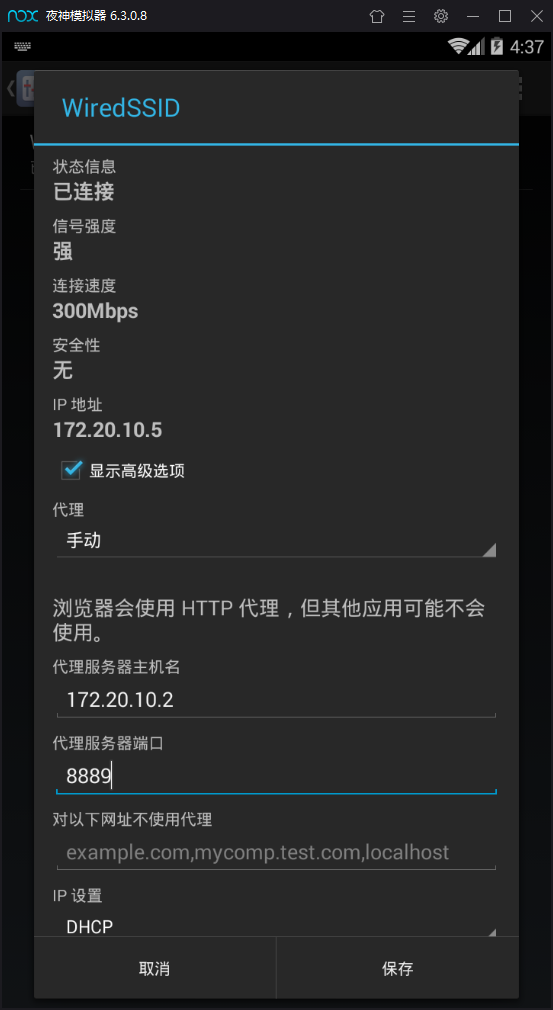
接下来测试是否能连接到fiddler 打开fiddler 然后安卓模拟器打开浏览器随便开一个网页,看看fiddler是否可以抓到包
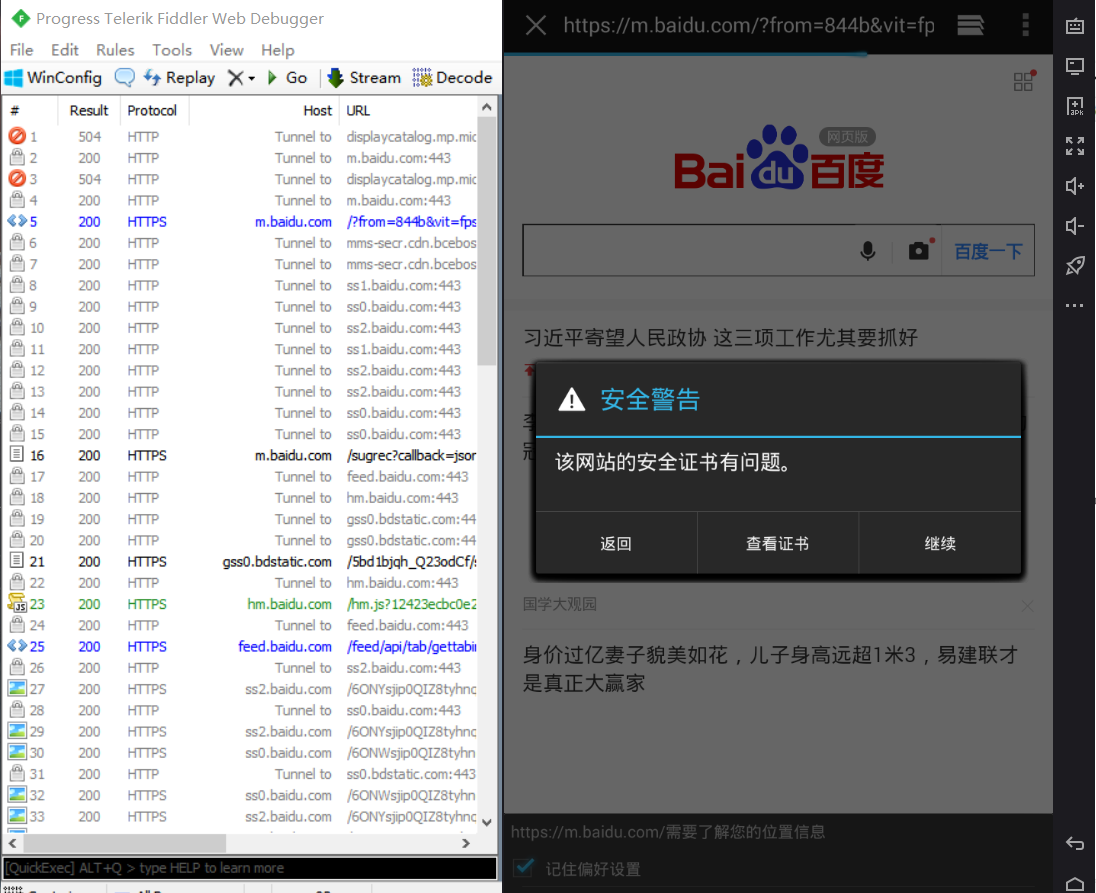
发现现在是可以抓到数据包的,但是浏览器一直在提醒安全证书有问题,这是因为我们模拟器中没有添加fiddler的证书,我们可以在模拟器浏览器中访问我们电脑的IP地址和端口号来安装证书
点击图中的最下方的超链接下载证书 然后安装证书,注意这一步可能需要我们设置下模拟器的锁屏密码自己设置即可
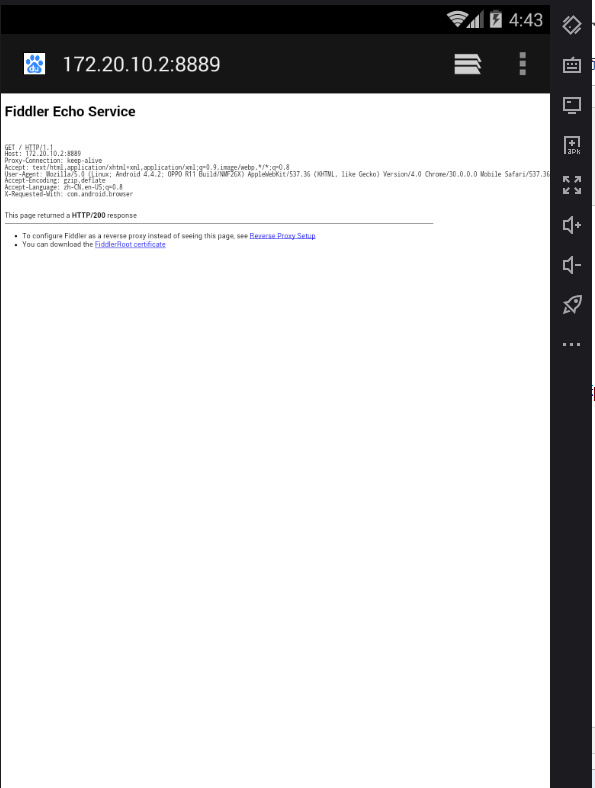
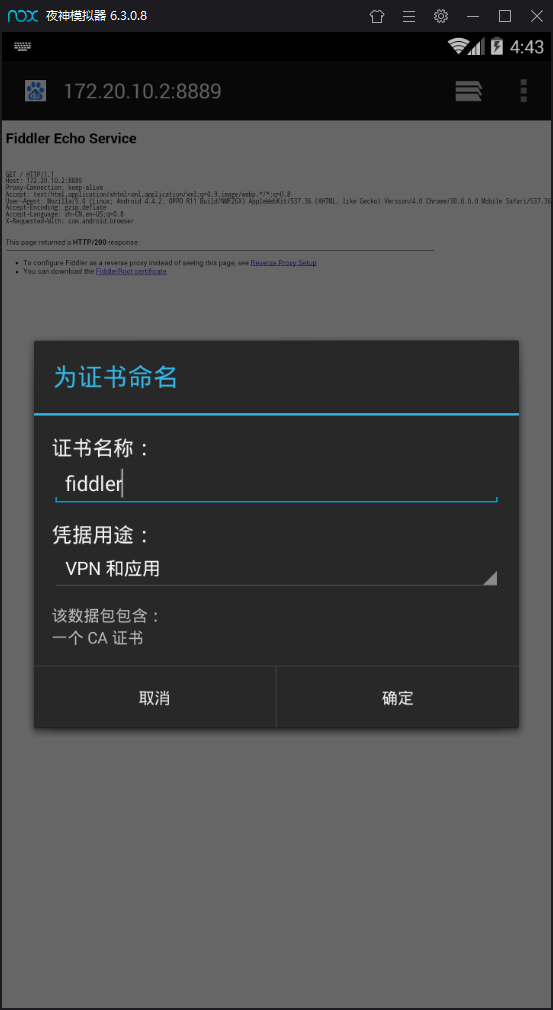
至此我们第一步模拟器连接到fiddler已经完成,接下来可以进行抓取的操作了
2)打开安卓模拟器进行操作
模拟器安装好豆果美食app开始操作 进入App (图一) 点击菜谱分类(即index页面(图二)) 点进去具体食材(图三)然后选择菜谱(图四)
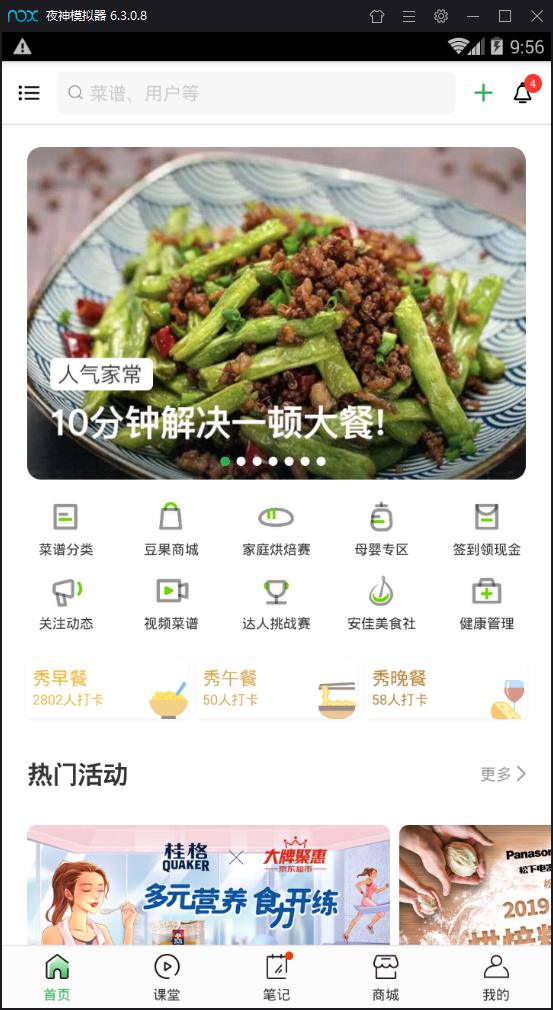
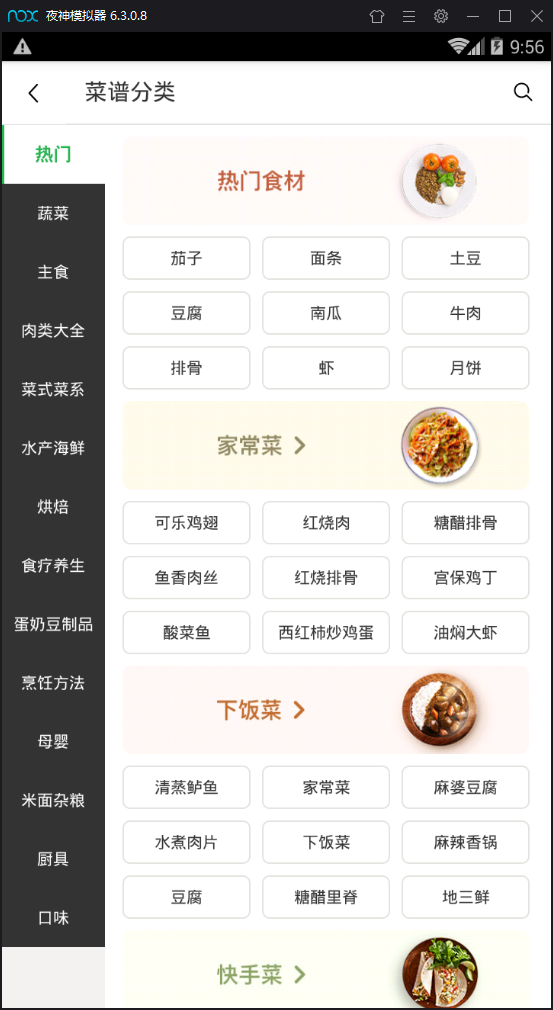
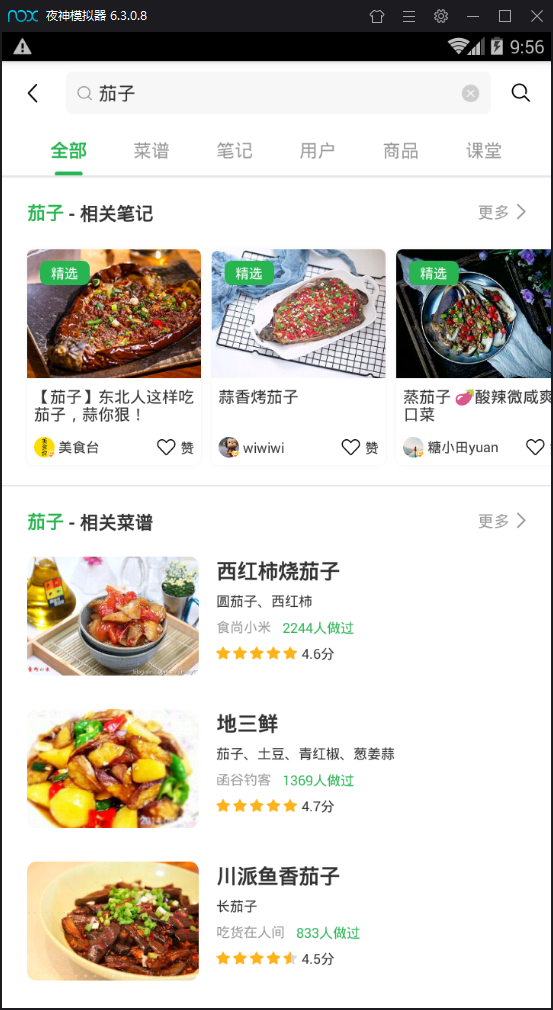
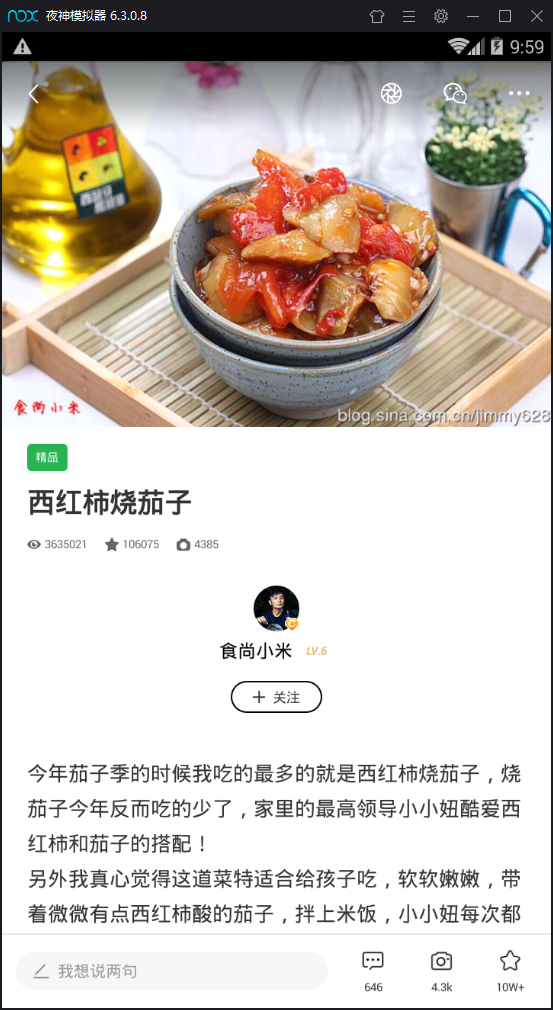
分别进行以上操作后我们的fiddler就会抓取到很多数据包 然后我们现在打开fiddler来分析下到底是哪些数据包对我们有用
3)分析fiddler抓取的数据
我们先来看下这时候fiddler中出现了什么 看起来很多数据包不知道如何下手
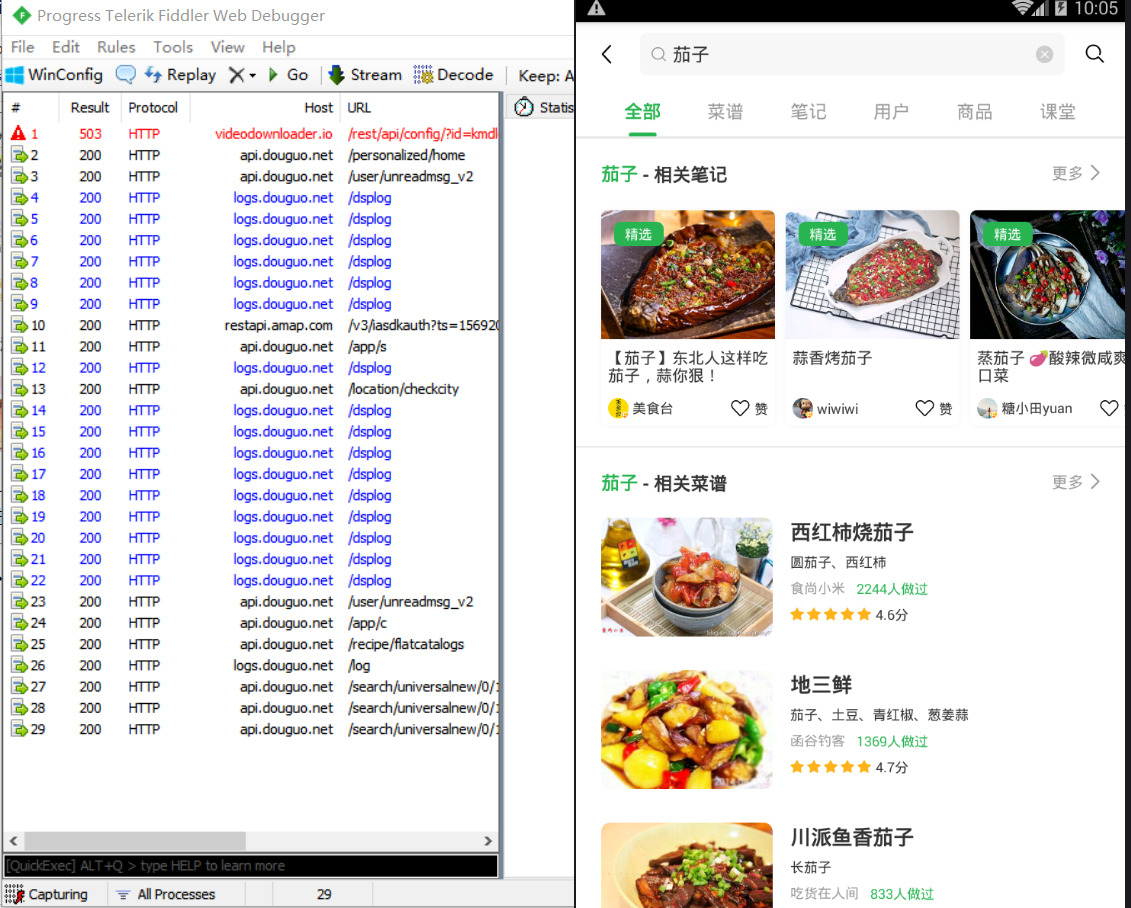
学过编程的同学们都知道一般程序的请求数据都是通过api接口的,我们发现fiddler中抓取到一些名称为 api.douguo.net 的数据包 我们来看看是不是我们想要的数据包
我们点击名称以api 接口的几个数据包就会发现里面返回的数据正是我们想要的数据(出现了分类茄子等内容的数据),所以我们现在将其他没用的数据包删掉,只留下对我们有用的数据包
并且我们根据某些数据包的url名称也会看出点东西,因为编程的命名一般不会杂乱无章的,所以有些名称直接就暴露了数据包的内容
最后我们简单的用fiddler看返回的response可以看出来我们需要用的就是以下三个 返回的数据分别对应着刚刚模拟器操作的图二图三图四 也正是菜谱的内容
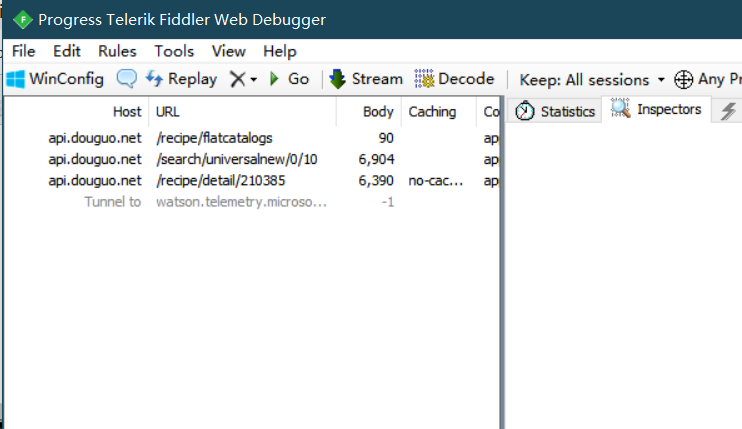
4)使用python模拟数据给服务器发送request请求得到响应数据
现在我们对于抓取到的三个包的request分析进行模拟,向服务器发送请求,看看我们能否收到想要的响应
打开pycharm 编写文件 首先我们分析第一个包 也就是菜谱分类页面如下图
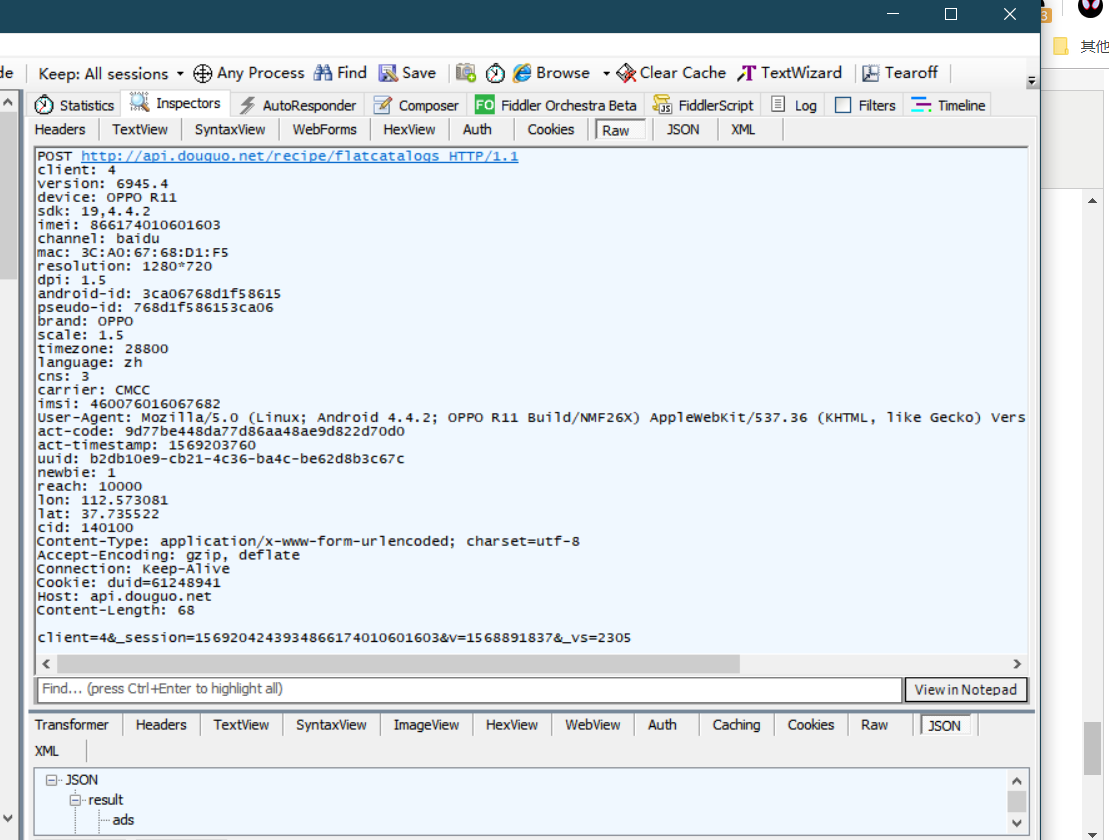
可以看出来request请求是 POST 方法 头部信息和发送的data 都在fiddler中可以看出来 现在编写py文件
将头部信息复制到notepad或者其他文本处理工具中将文本使用查找替换成我们要的字典格式如图(记得将空格删除)
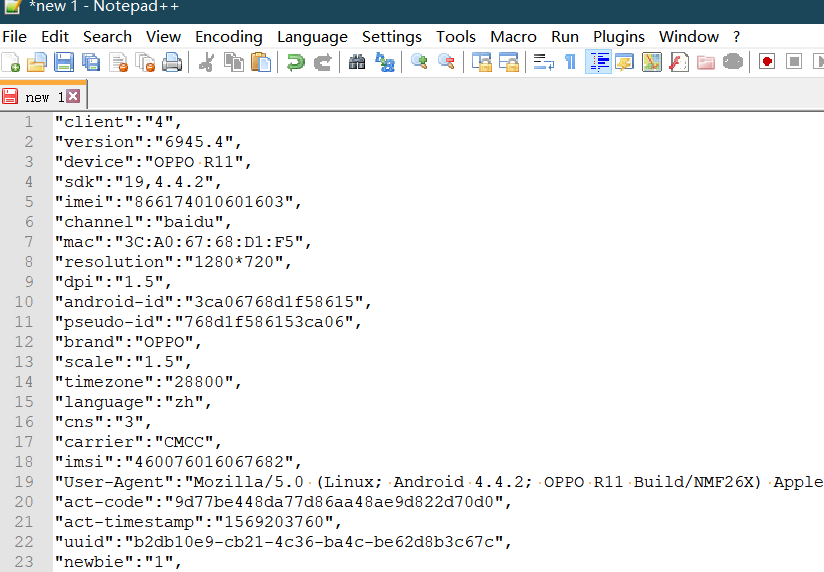
douguo_test.py文件编写如下:
import requests import json def douguo_request(url,data): #有些头部信息不需要已经进行了注释,因为可能会造成服务器检测我们多次请求问题 headers = { "client": "4", "version": "6945.4", "device": "OPPO R11", "sdk": "19,4.4.2", "imei": "866174010601603", "channel": "baidu", #"mac": "3C:A0:67:68:D1:F5", "resolution": "1280*720", "dpi": "1.5", #"android-id": "3ca06768d1f58615", #"pseudo-id": "768d1f586153ca06", "brand": "OPPO", "scale": "1.5", "timezone": "28800", "language": "zh", "cns": "3", "carrier": "CMCC", #"imsi": " 460076016067682", "User-Agent": "Mozilla/5.0 (Linux; Android 4.4.2; OPPO R11 Build/NMF26X) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/30.0.0.0 Mobile Safari/537.36", "act-code": "9d77be448da77d86aa48ae9d822d70d0", "act-timestamp": "1569203760", "uuid": "b2db10e9-cb21-4c36-ba4c-be62d8b3c67c", "newbie": "1", "reach": "10000", #"lon": "112.573081", #"lat": "37.735522", #"cid": "140100", "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", "Accept-Encoding": "gzip, deflate", "Connection": "Keep-Alive", #"Cookie": "duid=61248941", "Host": "api.douguo.net", #"Content-Length": "68", } response = requests.post(url=url,data=data,headers=headers) return response url = 'http://api.douguo.net/recipe/flatcatalogs' data = { "client":"4", #"_session" : "1568947372977863254011601605", #"v" : "1568891837", "_vs" : "2305" } response = douguo_request(url,data) print(response.text)
然后我们发现打印出一个json格式的东西,接下来我们将打印的东西放进 json.cn网站中读取一下(这样可以更方便的看json数据)

我们发现没错正是我们想要的分类数据 接下来继续下一步的操作
我们点开三个数据包会发现三个数据包的头部信息与POST方法都一样,不一样的是请求的 url 和 data 内容 所以我们编写的第一个request函数可以反复使用
第一个我们已经可以得到页面索引,现在我们来看如何进入具体食材的列表视图 如茄子 分析第二个数据包发送的data 发现data中存在些乱码,这是url编码后的结果,我们转换一下就好了
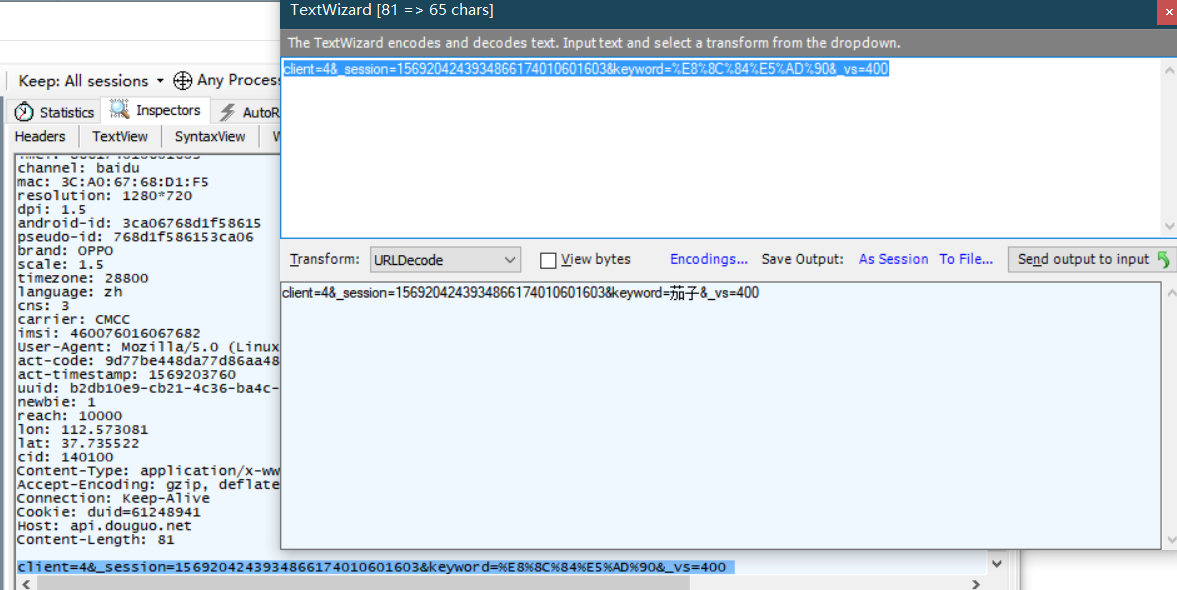
因此我们发现,其实data就是发送了具体食材的名称,那么名称从哪里获取的呢?没错就是我们刚刚返回的json中就包含,因此我们需要编写一个可以分析json结构获取名称然后组成data的函数
继续编写如下
import requests import json def douguo_request(url,data): #有些头部信息不需要已经进行了注释,因为可能会造成服务器检测我们多次请求问题 headers = { "client": "4", "version": "6945.4", "device": "OPPO R11", "sdk": "19,4.4.2", "imei": "866174010601603", "channel": "baidu", #"mac": "3C:A0:67:68:D1:F5", "resolution": "1280*720", "dpi": "1.5", #"android-id": "3ca06768d1f58615", #"pseudo-id": "768d1f586153ca06", "brand": "OPPO", "scale": "1.5", "timezone": "28800", "language": "zh", "cns": "3", "carrier": "CMCC", #"imsi": " 460076016067682", "User-Agent": "Mozilla/5.0 (Linux; Android 4.4.2; OPPO R11 Build/NMF26X) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/30.0.0.0 Mobile Safari/537.36", "act-code": "9d77be448da77d86aa48ae9d822d70d0", "act-timestamp": "1569203760", "uuid": "b2db10e9-cb21-4c36-ba4c-be62d8b3c67c", "newbie": "1", "reach": "10000", #"lon": "112.573081", #"lat": "37.735522", #"cid": "140100", "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", "Accept-Encoding": "gzip, deflate", "Connection": "Keep-Alive", #"Cookie": "duid=61248941", "Host": "api.douguo.net", #"Content-Length": "68", } response = requests.post(url=url,data=data,headers=headers) return response def douguo_index(): url = 'http://api.douguo.net/recipe/flatcatalogs' data = { "client":"4", #"_session" : "1568947372977863254011601605", #"v" : "1568891837", "_vs" : "2305" } response = douguo_request(url, data) #需要把json数据变为dict response_dict = json.loads(response.text) for item1 in response_dict['result']['cs']: for item2 in item1['cs']: for item3 in item2['cs']: data={ "client": "4", # "_session": "1568947372977863254011601605", "keyword": item3['name'], "_vs": "400" } print(data) douguo_index()
运行得到如下图
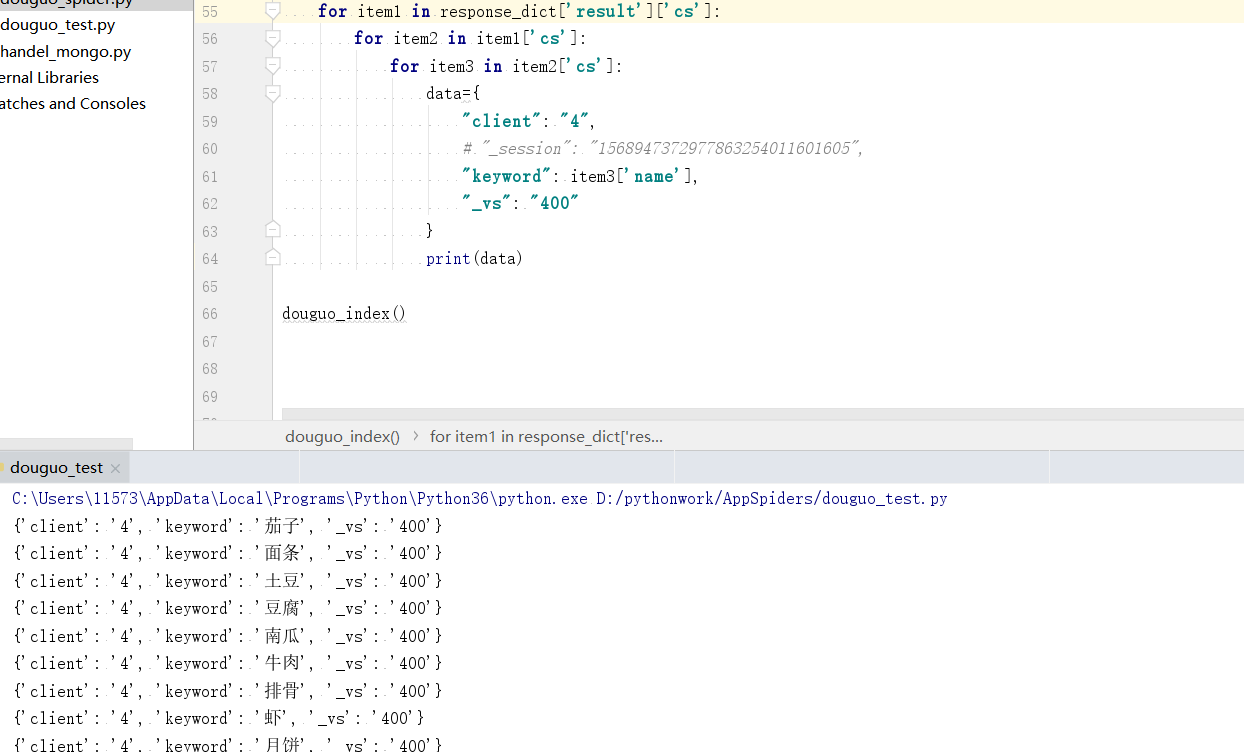
没错我们现在已经构建好了要发送的data数据
接下来我们继续构造另一个发送的函数 来获取具体食材的菜谱列表(我们只选取食材的最火的前10个菜谱) 当前我们先测试第一个获取的也就是茄子,一会我们使用队列来多线程抓取
import requests import json def douguo_request(url,data): #有些头部信息不需要已经进行了注释,因为可能会造成服务器检测我们多次请求问题 headers = { "client": "4", "version": "6945.4", "device": "OPPO R11", "sdk": "19,4.4.2", "imei": "866174010601603", "channel": "baidu", #"mac": "3C:A0:67:68:D1:F5", "resolution": "1280*720", "dpi": "1.5", #"android-id": "3ca06768d1f58615", #"pseudo-id": "768d1f586153ca06", "brand": "OPPO", "scale": "1.5", "timezone": "28800", "language": "zh", "cns": "3", "carrier": "CMCC", #"imsi": " 460076016067682", "User-Agent": "Mozilla/5.0 (Linux; Android 4.4.2; OPPO R11 Build/NMF26X) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/30.0.0.0 Mobile Safari/537.36", "act-code": "9d77be448da77d86aa48ae9d822d70d0", "act-timestamp": "1569203760", "uuid": "b2db10e9-cb21-4c36-ba4c-be62d8b3c67c", "newbie": "1", "reach": "10000", #"lon": "112.573081", #"lat": "37.735522", #"cid": "140100", "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", "Accept-Encoding": "gzip, deflate", "Connection": "Keep-Alive", #"Cookie": "duid=61248941", "Host": "api.douguo.net", #"Content-Length": "68", } response = requests.post(url=url,data=data,headers=headers) return response def douguo_index(): url = 'http://api.douguo.net/recipe/flatcatalogs' data = { "client":"4", #"_session" : "1568947372977863254011601605", #"v" : "1568891837", "_vs" : "2305" } response = douguo_request(url, data) #需要把json数据变为dict response_dict = json.loads(response.text) for item1 in response_dict['result']['cs']: for item2 in item1['cs']: for item3 in item2['cs']: data={ "client": "4", # "_session": "1568947372977863254011601605", "keyword": item3['name'], "_vs": "400" } return data def douguo_item(data): print('当前处理食材', data['keyword']) url = 'http://api.douguo.net/search/universalnew/0/10' response = douguo_request(url=url,data=data) print(response.text) douguo_item(douguo_index())
又输出了一个json数据,接着我们放进网页查看
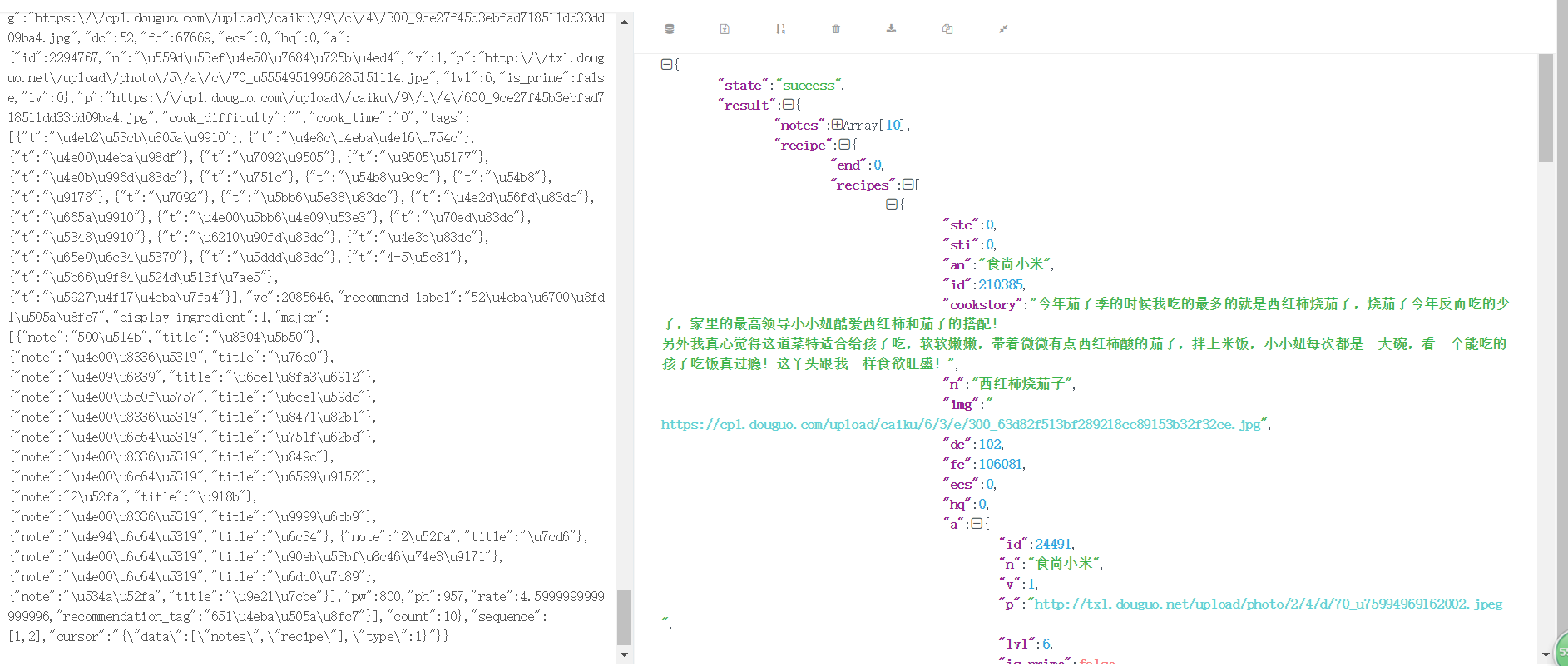
现在我们已经得到了菜谱的作者、介绍等信息但是没有菜谱的详细信息,我们可以进行简单的赋值操作

但是现在我们并没有需要的原料和具体的制作步骤,所以接下来我们分析最后一个数据包,可以得到具体的原料,制作步骤等信息
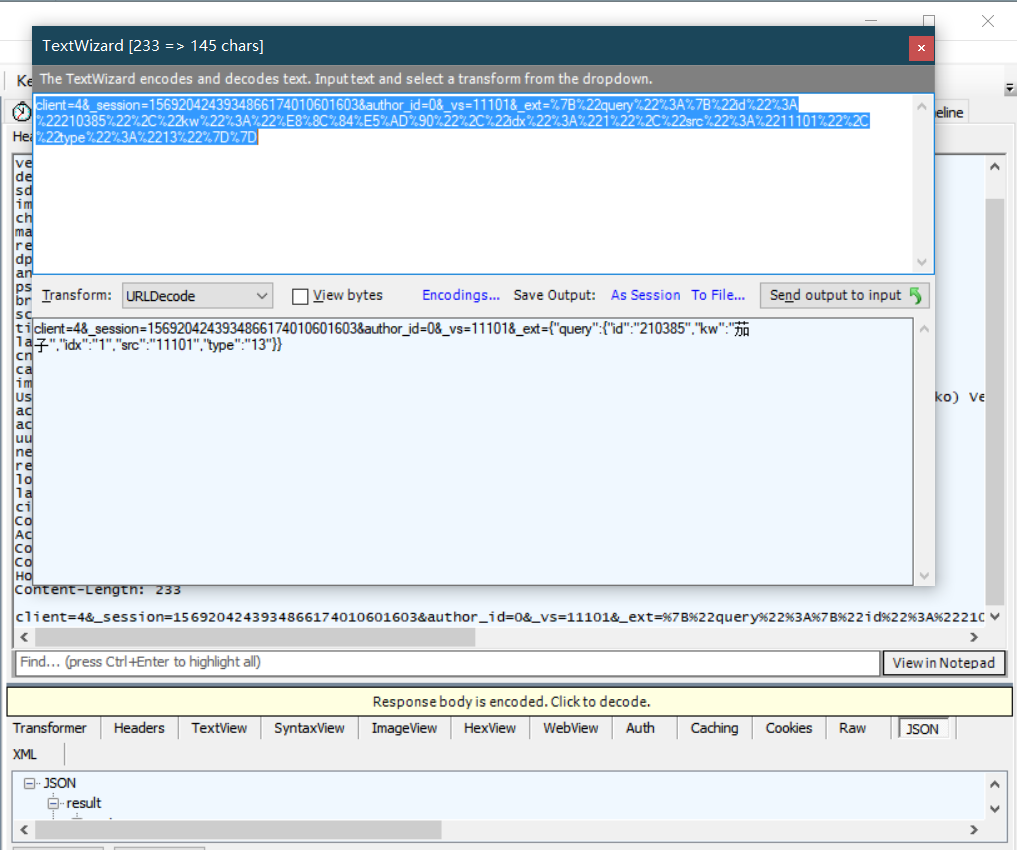
可以发现同样的我们只需要修改数据包发送的data的部分数据就可以,同上面方法类似继续编写程序然后给字典对象赋值
import requests import json def douguo_request(url,data): #有些头部信息不需要已经进行了注释,因为可能会造成服务器检测我们多次请求问题 headers = { "client": "4", "version": "6945.4", "device": "OPPO R11", "sdk": "19,4.4.2", "imei": "866174010601603", "channel": "baidu", #"mac": "3C:A0:67:68:D1:F5", "resolution": "1280*720", "dpi": "1.5", #"android-id": "3ca06768d1f58615", #"pseudo-id": "768d1f586153ca06", "brand": "OPPO", "scale": "1.5", "timezone": "28800", "language": "zh", "cns": "3", "carrier": "CMCC", #"imsi": " 460076016067682", "User-Agent": "Mozilla/5.0 (Linux; Android 4.4.2; OPPO R11 Build/NMF26X) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/30.0.0.0 Mobile Safari/537.36", "act-code": "9d77be448da77d86aa48ae9d822d70d0", "act-timestamp": "1569203760", "uuid": "b2db10e9-cb21-4c36-ba4c-be62d8b3c67c", "newbie": "1", "reach": "10000", #"lon": "112.573081", #"lat": "37.735522", #"cid": "140100", "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", "Accept-Encoding": "gzip, deflate", "Connection": "Keep-Alive", #"Cookie": "duid=61248941", "Host": "api.douguo.net", #"Content-Length": "68", } response = requests.post(url=url,data=data,headers=headers) return response def douguo_index(): url = 'http://api.douguo.net/recipe/flatcatalogs' data = { "client":"4", #"_session" : "1568947372977863254011601605", #"v" : "1568891837", "_vs" : "2305" } response = douguo_request(url, data) #需要把json数据变为dict response_dict = json.loads(response.text) for item1 in response_dict['result']['cs']: for item2 in item1['cs']: for item3 in item2['cs']: data={ "client": "4", # "_session": "1568947372977863254011601605", "keyword": item3['name'], "_vs": "400" } return data def douguo_item(data): item_index_number = 0 print('当前处理食材', data['keyword']) url = 'http://api.douguo.net/search/universalnew/0/10' list_response = douguo_request(url=url,data=data) list_response_dict = json.loads(list_response.text) for item in list_response_dict['result']['recipe']['recipes']: item_index_number = item_index_number + 1 #创建一个字典对象用来存放数据 caipu_info = {} caipu_info['shicai'] = data['keyword'] caipu_info['author'] = item['an'] caipu_info['shicai_id'] = item['id'] caipu_info['shicai_name'] = item['n'] caipu_info['describe'] = item['cookstory'] caipu_info['cailiao_list'] = item['major'] #更多细节需要继续编写请求 detail_url='http://api.douguo.net/recipe/detail/'+str(caipu_info['shicai_id']) detail_data = { "client": "4", "_session": "1569204243934866174010601603", "author_id": "0", "_vs": "11101", #最下面一条需要我们修改为指定的参数 注意引号与加号写法 "_ext":'{"query":{"id":'+str(caipu_info['shicai_id'])+',"kw":'+str(caipu_info['shicai'])+',"idx":'+str(item_index_number)+',"src":"11101","type":"13"}}' } detail_response = douguo_request(url=detail_url,data=detail_data) detail_response_dict = json.loads(detail_response.text) caipu_info['tips'] = detail_response_dict['result']['recipe']['tips'] caipu_info['cook_step'] = detail_response_dict['result']['recipe']['cookstep'] print(caipu_info) douguo_item(douguo_index())
现在我们大部分的工作已经完成了,我们已经可以获取到食材的各种信息,接下来就是最后一步了。
5)使用多线程抓取并在本地保存至数据库
大家肯定会发现我们刚刚虽然抓取成功了,但是我们只抓取了茄子的数据,那么还有很多很多的食材菜谱,我们该怎样操作呢?对了就是利用线程池进行多线程抓取提升效率
下面开始编写代码:
import requests import json #引入队列 from multiprocessing import Queue #引入线程池 from concurrent.futures import ThreadPoolExecutor #创建队列 queue_list = Queue() def douguo_request(url,data): #有些头部信息不需要已经进行了注释,因为可能会造成服务器检测我们多次请求问题 headers = { "client": "4", "version": "6945.4", "device": "OPPO R11", "sdk": "19,4.4.2", "imei": "866174010601603", "channel": "baidu", #"mac": "3C:A0:67:68:D1:F5", "resolution": "1280*720", "dpi": "1.5", #"android-id": "3ca06768d1f58615", #"pseudo-id": "768d1f586153ca06", "brand": "OPPO", "scale": "1.5", "timezone": "28800", "language": "zh", "cns": "3", "carrier": "CMCC", #"imsi": " 460076016067682", "User-Agent": "Mozilla/5.0 (Linux; Android 4.4.2; OPPO R11 Build/NMF26X) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/30.0.0.0 Mobile Safari/537.36", "act-code": "9d77be448da77d86aa48ae9d822d70d0", "act-timestamp": "1569203760", "uuid": "b2db10e9-cb21-4c36-ba4c-be62d8b3c67c", "newbie": "1", "reach": "10000", #"lon": "112.573081", #"lat": "37.735522", #"cid": "140100", "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", "Accept-Encoding": "gzip, deflate", "Connection": "Keep-Alive", #"Cookie": "duid=61248941", "Host": "api.douguo.net", #"Content-Length": "68", } response = requests.post(url=url,data=data,headers=headers) return response def douguo_index(): url = 'http://api.douguo.net/recipe/flatcatalogs' data = { "client":"4", #"_session" : "1568947372977863254011601605", #"v" : "1568891837", "_vs" : "2305" } response = douguo_request(url, data) #需要把json数据变为dict response_dict = json.loads(response.text) for item1 in response_dict['result']['cs']: for item2 in item1['cs']: for item3 in item2['cs']: data={ "client": "4", # "_session": "1568947372977863254011601605", "keyword": item3['name'], "_vs": "400" } #放入队列使用put方法 queue_list.put(data) def douguo_item(data): item_index_number = 0 print('当前处理食材', data['keyword']) url = 'http://api.douguo.net/search/universalnew/0/10' list_response = douguo_request(url=url,data=data) list_response_dict = json.loads(list_response.text) for item in list_response_dict['result']['recipe']['recipes']: item_index_number = item_index_number + 1 #创建一个字典对象用来存放数据 caipu_info = {} caipu_info['shicai'] = data['keyword'] caipu_info['author'] = item['an'] caipu_info['shicai_id'] = item['id'] caipu_info['shicai_name'] = item['n'] caipu_info['describe'] = item['cookstory'] caipu_info['cailiao_list'] = item['major'] #更多细节需要继续编写请求 detail_url='http://api.douguo.net/recipe/detail/'+str(caipu_info['shicai_id']) detail_data = { "client": "4", "_session": "1569204243934866174010601603", "author_id": "0", "_vs": "11101", #最下面一条需要我们修改为指定的参数 注意引号与加号写法 "_ext":'{"query":{"id":'+str(caipu_info['shicai_id'])+',"kw":'+str(caipu_info['shicai'])+',"idx":'+str(item_index_number)+',"src":"11101","type":"13"}}' } detail_response = douguo_request(url=detail_url,data=detail_data) detail_response_dict = json.loads(detail_response.text) caipu_info['tips'] = detail_response_dict['result']['recipe']['tips'] caipu_info['cook_step'] = detail_response_dict['result']['recipe']['cookstep'] print('当前处理的菜谱是:',caipu_info['shicai_name']) print(caipu_info) douguo_index() #同时进行处理的任务数 pool = ThreadPoolExecutor(max_workers=25) while(queue_list.qsize()>0): #注意多线程写法,douguo_item函数后一定不能加括号 pool.submit(douguo_item,queue_list.get())
再次运行,发现现在已经可以抓取所有的菜谱,然后我们只需要进行最后一步将数据保存到本地数据库就彻底大功告成了
我们可以先编写一个入库函数douguo_mongo.py
import pymongo from pymongo.collection import Collection class Cnonnect_mongo(object): def __init__(self): #本地数据库host为127.0.0.1 端口为27017 具体可以打开mongodb查看 self.client = pymongo.MongoClient(host='127.0.0.1',port=27017) #数据库名称 self.dbdata = self.client['douguomeishi'] def insert_item(self,item): #数据表名称为 douguo_item db_collection = Collection(self.dbdata,'douguo_item') db_collection.insert(item) mongo_info = Cnonnect_mongo()
然后我们去爬虫文件引用刚刚写的入库对象类并使用插入函数
import requests import json #引入队列 from multiprocessing import Queue #引入线程池 from concurrent.futures import ThreadPoolExecutor #引用入库类对象 from handel_mongo import mongo_info #创建队列 queue_list = Queue() def douguo_request(url,data): #有些头部信息不需要已经进行了注释,因为可能会造成服务器检测我们多次请求问题 headers = { "client": "4", "version": "6945.4", "device": "OPPO R11", "sdk": "19,4.4.2", "imei": "866174010601603", "channel": "baidu", #"mac": "3C:A0:67:68:D1:F5", "resolution": "1280*720", "dpi": "1.5", #"android-id": "3ca06768d1f58615", #"pseudo-id": "768d1f586153ca06", "brand": "OPPO", "scale": "1.5", "timezone": "28800", "language": "zh", "cns": "3", "carrier": "CMCC", #"imsi": " 460076016067682", "User-Agent": "Mozilla/5.0 (Linux; Android 4.4.2; OPPO R11 Build/NMF26X) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/30.0.0.0 Mobile Safari/537.36", "act-code": "9d77be448da77d86aa48ae9d822d70d0", "act-timestamp": "1569203760", "uuid": "b2db10e9-cb21-4c36-ba4c-be62d8b3c67c", "newbie": "1", "reach": "10000", #"lon": "112.573081", #"lat": "37.735522", #"cid": "140100", "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", "Accept-Encoding": "gzip, deflate", "Connection": "Keep-Alive", #"Cookie": "duid=61248941", "Host": "api.douguo.net", #"Content-Length": "68", } response = requests.post(url=url,data=data,headers=headers) return response def douguo_index(): url = 'http://api.douguo.net/recipe/flatcatalogs' data = { "client":"4", #"_session" : "1568947372977863254011601605", #"v" : "1568891837", "_vs" : "2305" } response = douguo_request(url, data) #需要把json数据变为dict response_dict = json.loads(response.text) for item1 in response_dict['result']['cs']: for item2 in item1['cs']: for item3 in item2['cs']: data={ "client": "4", # "_session": "1568947372977863254011601605", "keyword": item3['name'], "_vs": "400" } #放入队列使用put方法 queue_list.put(data) def douguo_item(data): item_index_number = 0 print('当前处理食材', data['keyword']) url = 'http://api.douguo.net/search/universalnew/0/10' list_response = douguo_request(url=url,data=data) list_response_dict = json.loads(list_response.text) for item in list_response_dict['result']['recipe']['recipes']: item_index_number = item_index_number + 1 #创建一个字典对象用来存放数据 caipu_info = {} caipu_info['shicai'] = data['keyword'] caipu_info['author'] = item['an'] caipu_info['shicai_id'] = item['id'] caipu_info['shicai_name'] = item['n'] caipu_info['describe'] = item['cookstory'] caipu_info['cailiao_list'] = item['major'] #更多细节需要继续编写请求 detail_url='http://api.douguo.net/recipe/detail/'+str(caipu_info['shicai_id']) detail_data = { "client": "4", "_session": "1569204243934866174010601603", "author_id": "0", "_vs": "11101", #最下面一条需要我们修改为指定的参数 注意引号与加号写法 "_ext":'{"query":{"id":'+str(caipu_info['shicai_id'])+',"kw":'+str(caipu_info['shicai'])+',"idx":'+str(item_index_number)+',"src":"11101","type":"13"}}' } detail_response = douguo_request(url=detail_url,data=detail_data) detail_response_dict = json.loads(detail_response.text) caipu_info['tips'] = detail_response_dict['result']['recipe']['tips'] caipu_info['cook_step'] = detail_response_dict['result']['recipe']['cookstep'] print('当前处理的菜谱是:',caipu_info['shicai_name']) #保存到数据库 mongo_info.insert_item(caipu_info) douguo_index() #同时进行处理的任务数 pool = ThreadPoolExecutor(max_workers=25) while(queue_list.qsize()>0): #注意多线程写法,douguo_item函数后一定不能加括号 pool.submit(douguo_item,queue_list.get())
运行,我们的数据就保存在数据库了
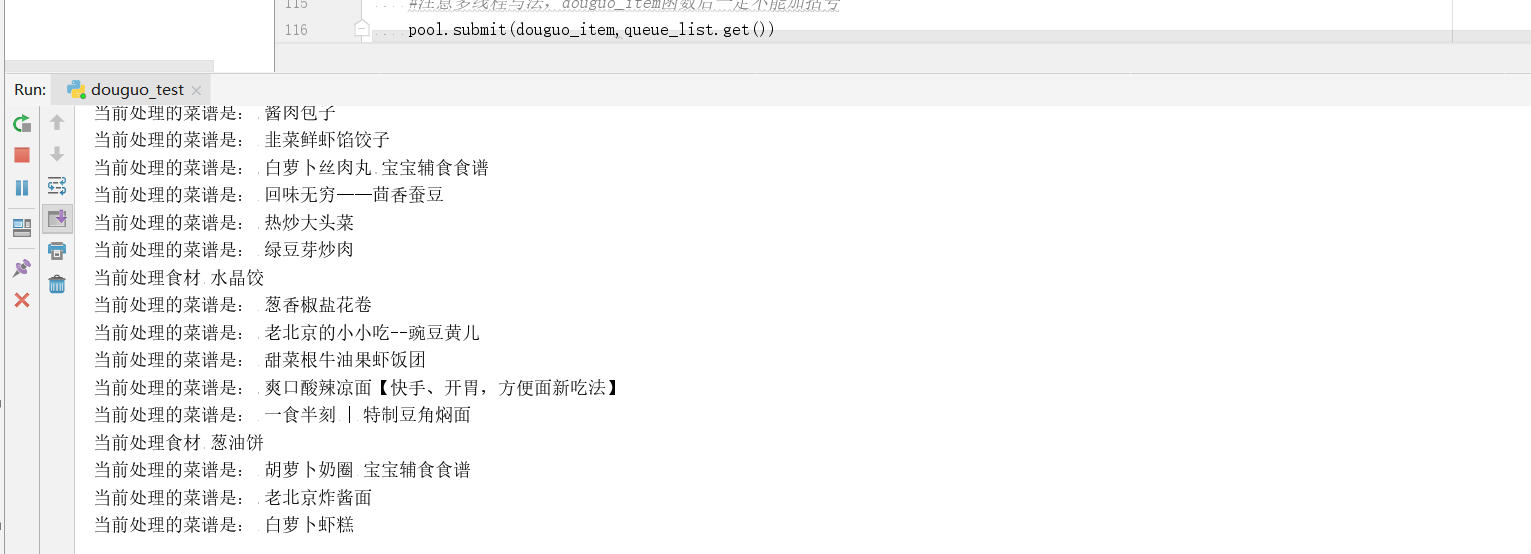
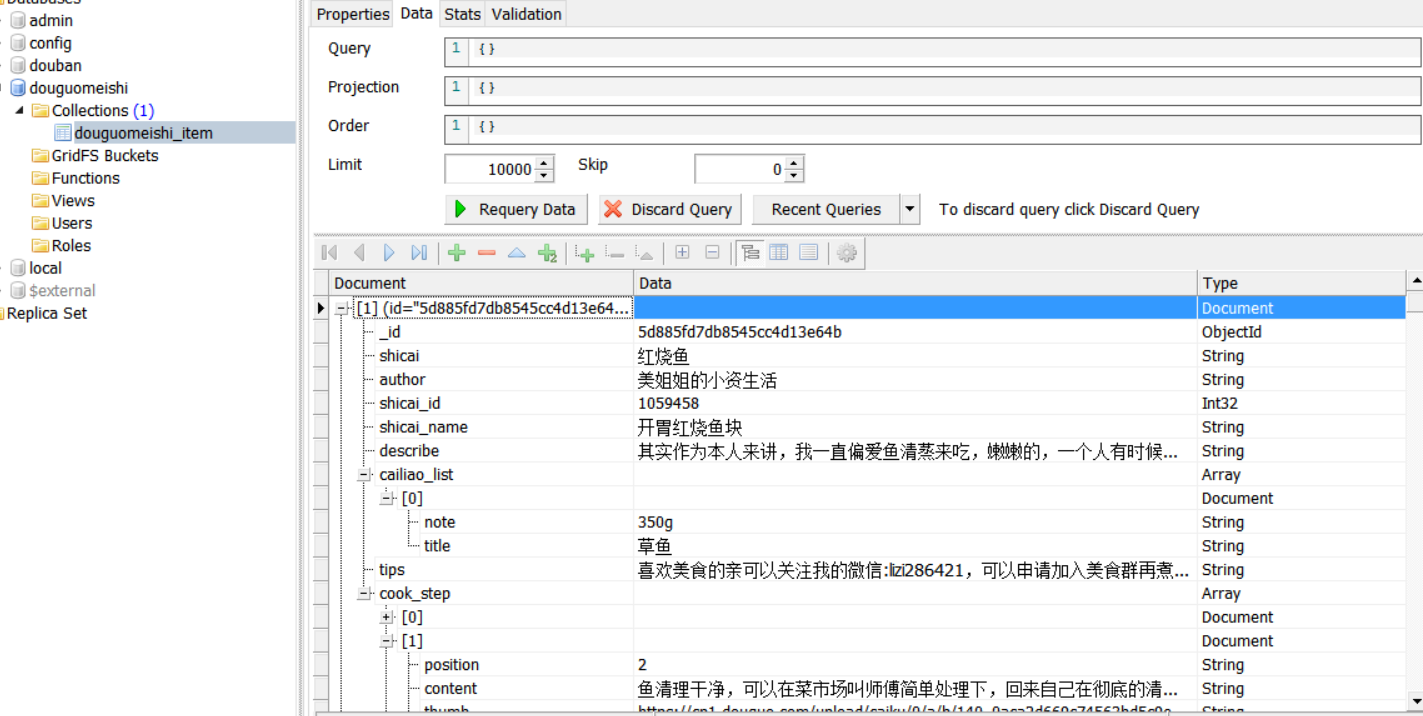
这就是爬取一个App的整个流程,有点繁琐,但也很有趣,一步一步的解析数据,挺有挑战性的。